閱讀目錄
本文版權歸mephisto和部落格園共有,歡迎轉載,但須保留此段宣告,並給出原文連結,謝謝合作。
文章是哥(mephisto)寫的,SourceLink
序
上一篇,我們介紹了Hive的資料多種方式匯入,這樣我們的Hive就有了資料來源了,但有時候我們可能需要純粹的匯出,或者叢集Hive資料的遷移(不同叢集,不同版本),我們就可以通過這兩章的知識來實現。
下面我們開始介紹hive的資料匯出,以及叢集Hive資料的遷移進行描述。
將查詢的結果寫入檔案系統
一:說明
將上篇中從其他表匯入語法進行簡單的修改,就可以將查詢的結果寫入到檔案系統。
二:語法:
Standard syntax: INSERT OVERWRITE [LOCAL] DIRECTORY directory1 [ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0) SELECT ... FROM ... Hive extension (multiple inserts): FROM from_statement INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1 [INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ... row_format : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] (Note: Only available starting with Hive 0.13)三:寫入到本地
如果使用LOCAL,則資料會寫入到本地
四:寫入到叢集
如果不使用LOCAL,則資料會寫到指定的HDFS中,如果沒寫全路徑,則使用Hadoop的配置項
fs.default.name(NameNode的URI)。五:實戰
修改tmp資料夾許可權(這裡只是測試,所以使用最大許可權)
chmod 777 tmp
進入Hive
sudo -u hdfs hive
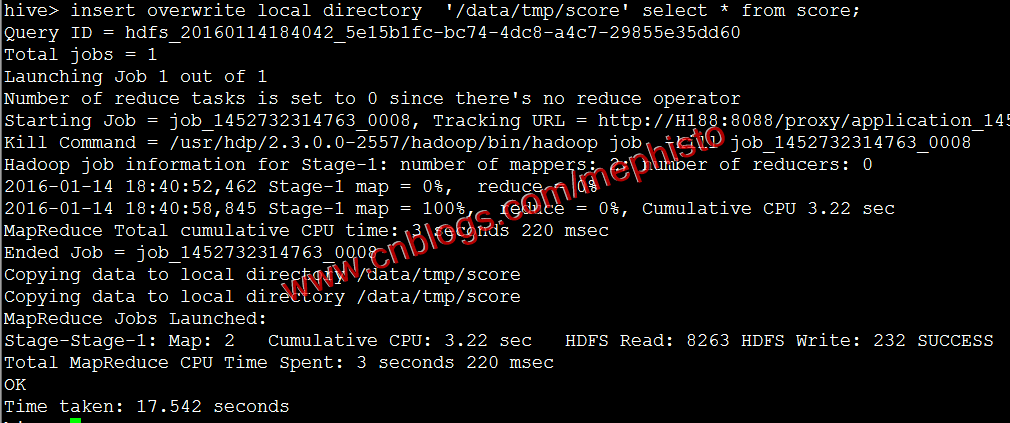
將上一篇中的score表資料匯出到本地
insert overwrite local directory '/data/tmp/score' select * from score;
我們可以看到/data/tmp/score/目錄下有檔案。
cd /data/tmp/score
ll
這樣我們就把hive的資料匯出到本地了。
下面我們使用不帶local引數的命令,將hive表資料導到hdfs中
insert overwrite directory '/data/tmp/score' select * from score;我們使用hdfs的ls命令檢視
hadoop fs -ls /data/tmp/score
這裡檔案只有一個,和上面的不一樣,但總的內容是一樣的,上面同樣的資料匯出,有時候也只有一個檔案。這裡就不做考究了。



叢集資料遷移一
一:介紹
在官網裡,我們可以看到EXPORT和IMPORT,該功能從Hive0.8開始加入進來。
二:Export/Import
匯出命令根據後設資料匯出表或者分割槽,輸出位置可以是另一個Hadoop叢集或者HIVE例項。支援帶有分割槽的表。匯出的後設資料儲存在目標目錄,資料檔案儲存在子目錄。
匯入匯出的源和目標的後設資料儲存DBMS可以是不同的關係型資料庫。
三:Export語法
EXPORT TABLE tablename [PARTITION (part_column="value"[, ...])] TO 'export_target_path'四:Import語法
IMPORT [[EXTERNAL] TABLE new_or_original_tablename [PARTITION (part_column="value"[, ...])]] FROM 'source_path' [LOCATION 'import_target_path']五:官方例子
簡單匯入匯出
export table department to 'hdfs_exports_location/department'; import from 'hdfs_exports_location/department';改名匯入匯出
export table department to 'hdfs_exports_location/department'; import table imported_dept from 'hdfs_exports_location/department';分割槽匯出
export table employee partition (emp_country="in", emp_state="ka") to 'hdfs_exports_location/employee'; import from 'hdfs_exports_location/employee';分割槽匯入
export table employee to 'hdfs_exports_location/employee'; import table employee partition (emp_country="us", emp_state="tn") from 'hdfs_exports_location/employee';指定匯入位置
export table department to 'hdfs_exports_location/department'; import table department from 'hdfs_exports_location/department' location 'import_target_location/department';作為外部表匯入
export table department to 'hdfs_exports_location/department'; import external table department from 'hdfs_exports_location/department';
叢集資料遷移二
一:介紹
雖然官方的Export/Import命令很強大,但在實際使用中,可能是版本的不同,會出現無法匯入的情況,自己在這塊也琢磨了下,總結出自己的一套帶有分割槽的Hive表資料遷移方案,該方案在Cloudera和Hontorworks的叢集中成功遷移過,Hive版本也不一致。
二:匯出資料
由於Cloudera的發行版本CDH-5.3.3的Hive版本低於0.8所以用這個作為資料來源。
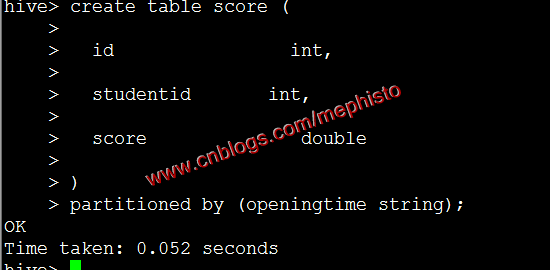
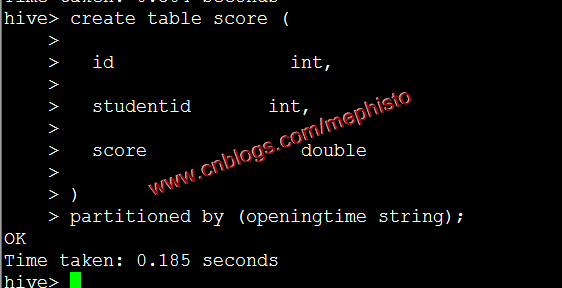
建立帶分割槽表score
create table score ( id int, studentid int, score double ) partitioned by (openingtime string);
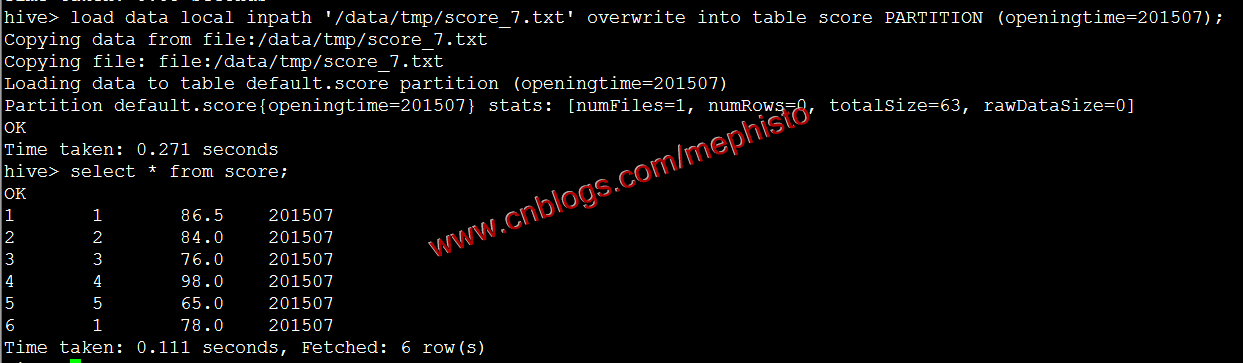
根據上一篇中匯入資料的方式匯入7,8月資料
load data local inpath '/data/tmp/score_7.txt' overwrite into table score PARTITION (openingtime=201507);
參考我們上面的匯出到本地還是放在/data/tmp/score下
insert overwrite local directory '/data/tmp/score' select * from score;三:遷移資料
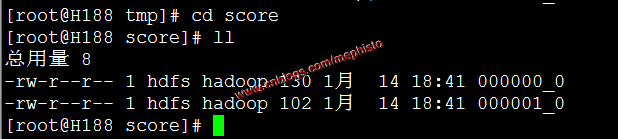
在另外一個叢集新建/data/tmp目錄
mkdir -p /data/tmp/score拷貝資料
scp /data/tmp/score/* root@h188:/data/tmp/score/檢視
cd /data/tmp/score ll
四:建立分割槽表和沒有分割槽的臨時表
被匯入的叢集是Hortonworks的HDP-2.7.1發行版本。
分割槽表就是我們最終的目標表,沒有分割槽的臨時表時過度用的。
進入Hive
sudo -u hdfs hive建立帶分割槽的表
create table score ( id int, studentid int, score double ) partitioned by (openingtime string);
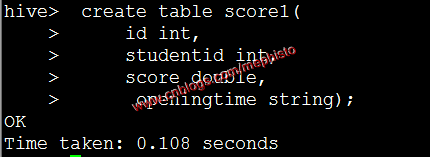
建立不帶分割槽的臨時表
create table score1( id int, studentid int, score double, openingtime string
);
五:將資料匯入臨時表
load data local inpath '/data/tmp/score' into table score1;
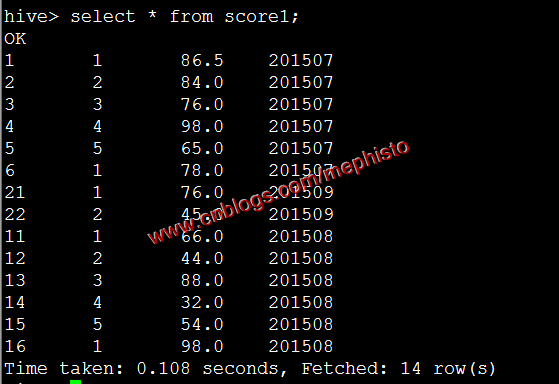
我們查下導進來的資料
select * from score1;
六:從臨時表匯入到分割槽表
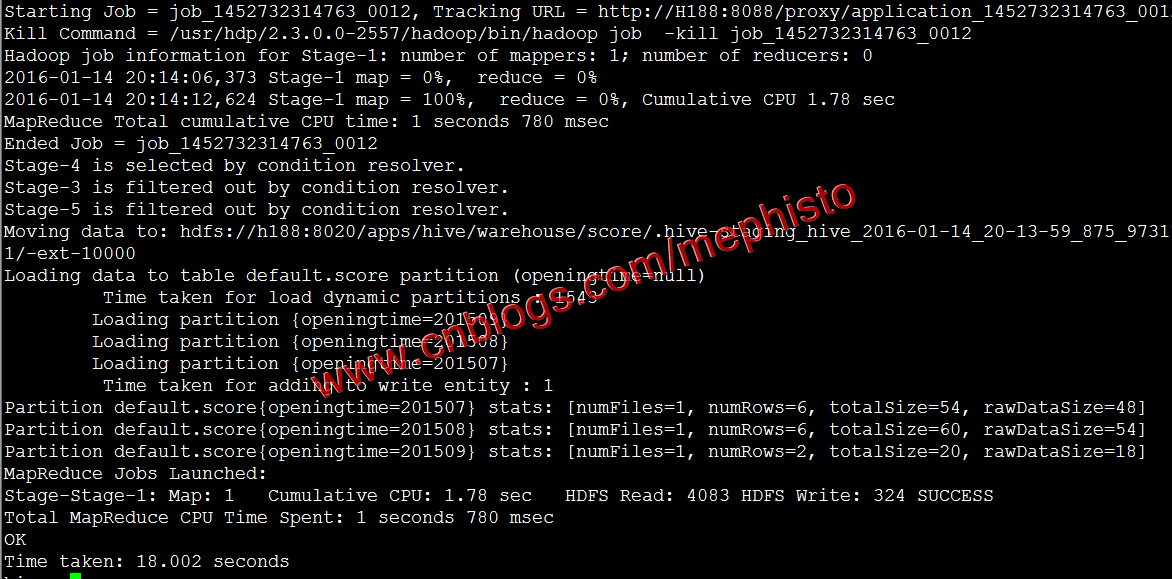
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.max.dynamic.partitions.pernode=10000; #匯入 insert overwrite table score partition(openingtime) select * from score1;
查詢
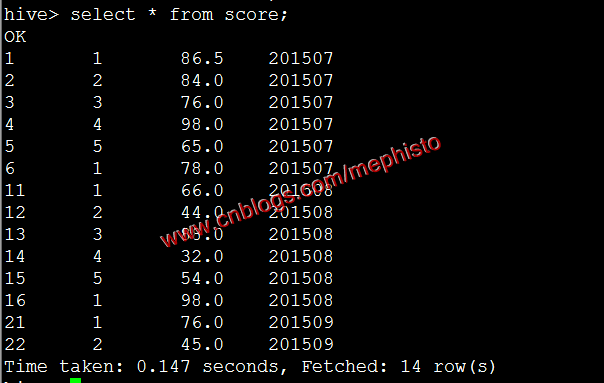
select * from score;
我們在hdfs中檢視下hive的檔案
hadoop fs -ls -R /apps/hive/warehouse/score
可以明顯的看到根據openingtime分割槽了。
七:刪除臨時表
drop table score1八:刪除臨時資料
rm -rf /data/tmp/score
這樣我們的Hive叢集資料遷移告一段落。
--------------------------------------------------------------------
到此,本章節的內容講述完畢。


系列索引
本文版權歸mephisto和部落格園共有,歡迎轉載,但須保留此段宣告,並給出原文連結,謝謝合作。
文章是哥(mephisto)寫的,SourceLink