搭建5個節點的hadoop叢集環境(CDH5)
提示:如果還不瞭解Hadoop的,可以下檢視這篇文章Hadoop生態系統,通過這篇文章,我們可以首先大致瞭解Hadoop及Hadoop的生態系統中的工具的使用場景。
搭建一個分散式的hadoop叢集環境,下面是詳細步驟,使用cdh5 。
|
作業系統
|
64位
|
|
CPU
|
(英特爾)Intel(R) I3處理器
|
|
記憶體
|
8.00 GB ( 1600 MHz)
|
|
硬碟剩餘空間
|
50G
|
|
作業系統
|
64位
|
|
CPU
|
(英特爾)Intel(R) I5處理器或以上配置
|
|
記憶體
|
16.00 GB ( 1600 MHz)
|
|
硬碟剩餘空間
|
100G
|
注意:上面是在單個pc機上搭建叢集,所以對記憶體要求較高。若是在多臺pc機上搭建叢集環境,則只需要記憶體足夠即可。
| 虛擬機器 | VMWare |
| 作業系統 | CentOS6.5 |
| JDK | jdk-7u79-linux-x64.tar.gz |
| 遠端連線 | XShell |
hadoop生態系統 |
hadoop-2.6.0-cdh5.4.5.tar.gz hbase-1.0.0-cdh5.4.4.tar.gz hive-1.1.0-cdh5.4.5.tar.gz flume-ng-1.5.0-cdh5.4.5.tar.gz sqoop-1.4.5-cdh5.4.5.tar.gz zookeeper-3.4.5-cdh5.4.5.tar.gz |
|
CDHNode1 /192.168.3.188 |
CDHNode2 /192.168.3.189 |
CDHNode3 /192.168.3.190 |
CDHNode4 /192.168.3.191 |
CDHNode5 /192.168.3.192 |
|
|---|---|---|---|---|---|
|
namenode |
是 |
是 |
否 |
否 |
否 |
|
datanode |
否 |
否 |
是 |
是 |
是 |
|
resourcemanager |
是 |
是 |
否 |
否 |
否 |
|
journalnode |
是 |
是 |
是 |
是 |
是 |
|
zookeeper |
是 |
是 |
是 |
否 |
否 |
注意:Journalnode和ZooKeeper保持奇數個,最少不少於 3 個節點。具體原因,以後詳敘。
我的主機分配情況是在兩臺pc的虛擬機器上安裝centos系統,具體分配情況如下:
| CDHNode1 | CDHNode2 | CDHNode3 | CDHNode4 | CDHNode4 | |
| PC1 | 是 | 是 | |||
| PC2 | 是 | 是 | 是 |
三、詳細安裝步驟
我們首先在1個主機(CHDNode1/192.168.3.188)上安裝centos6.5作業系統,使用root使用者配置網路,建立hadoop使用者,關閉防火牆,安裝一些必備軟體。為記下來的叢集軟體安裝做準備。
CentOS6.5安裝
在主機CHDNode1/192.168.3.188,安裝CentOS6.5作業系統。詳細安裝步驟可以檢視CentOS安裝這篇文章。此處就不再贅敘。
網路配置
1.開啟安裝好的CentOS虛擬機器CDHNode1
2、登入CentOS系統

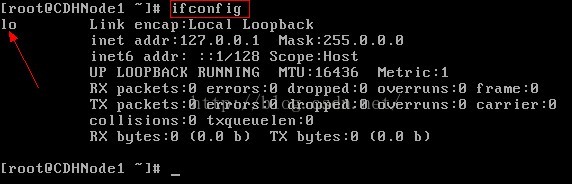
3.輸入ifconfig命令,先檢視ip地址
4、這個時候我們發現除了迴環地址以外,我們並不能和外界通訊,比如我們可以使用ping命令進行測試。
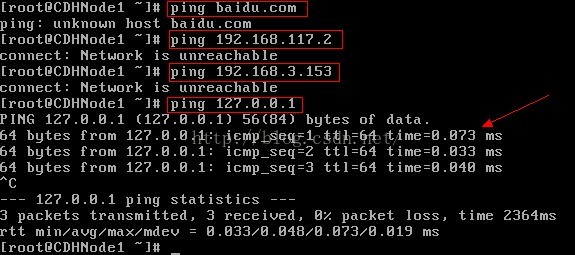
注意:ping 127.0.0.1時,結束icmp報文,使用Ctrl+C命令
第一次ping 百度,ping不通,說明虛擬機器無法連線外網
第二次ping 虛擬機器NAT閘道器,ping不通
注:虛擬機器閘道器檢視方法
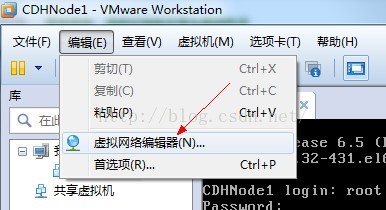
點選虛擬機器網路編輯器,點選VMnet8
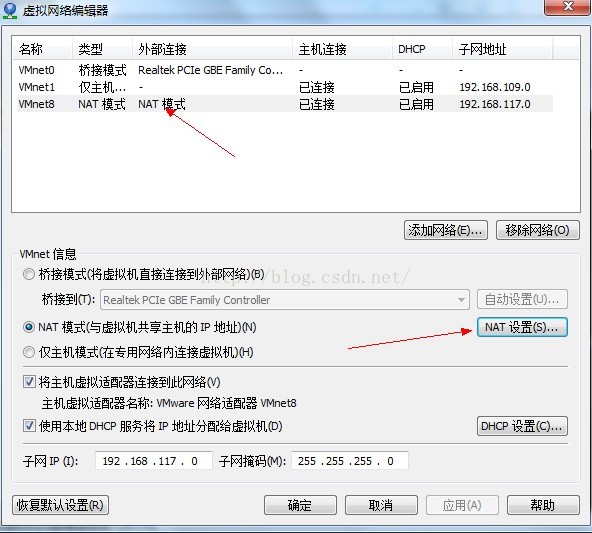
點選Nat設定
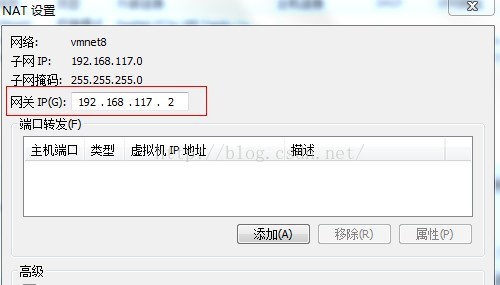
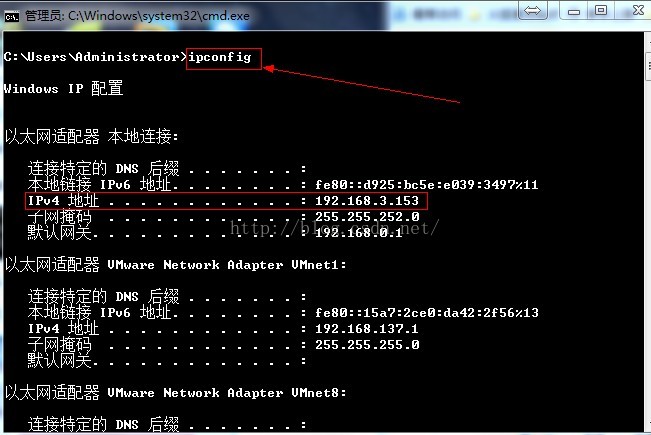
第三次ping物理機ip地址,ping不通
注:檢視物理機IP地址,開啟cmd.exe ,輸入ipconfig
第四次ping虛擬機器的迴環地址,ping成功,說明虛擬機器的網路協議是正確的
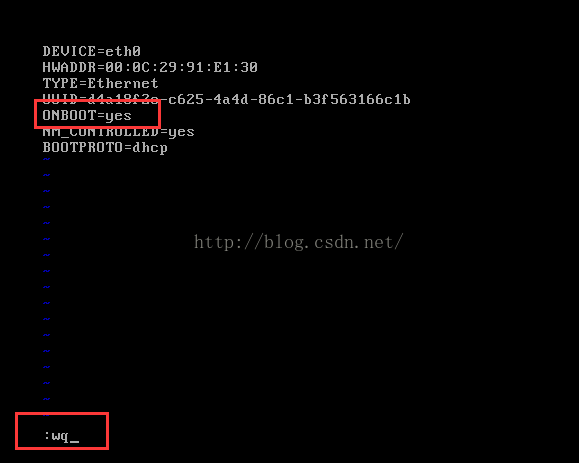
5、修改網路卡的配置檔案

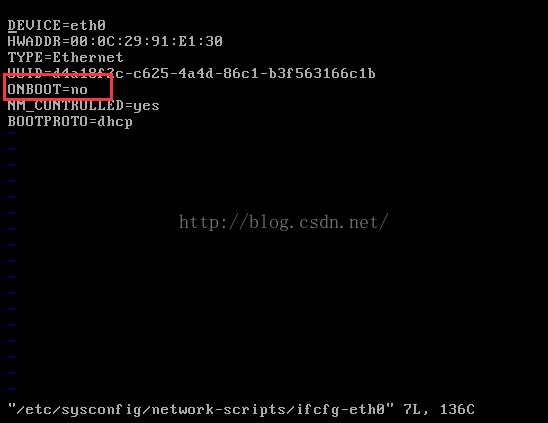
可以看到虛擬機器網路卡沒有開啟,因此修改ONBOOT=yes,然後儲存退出(按Esc鍵,然後輸入:wq)
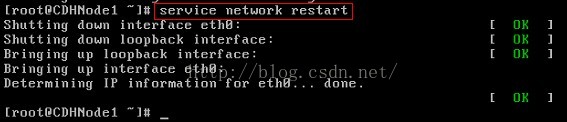
6、重啟網路服務
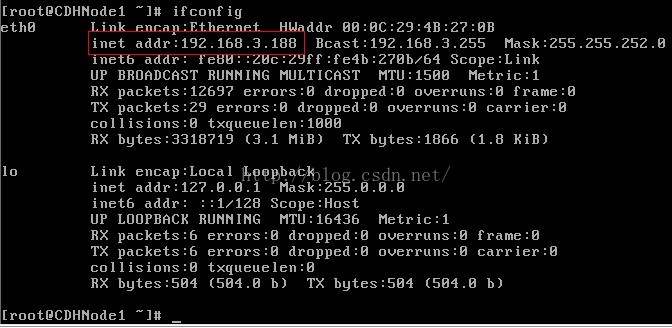
7、再次輸入ifconfig命令,檢視ip地址。
注意:我的虛擬機器設定的是橋接模式,所以ip地址是192.168.2.X網段,或192.168.3.X網段;因為橋接模式是直接使用物理網路卡,而我的物理主機的閘道器是192.168.0.1,子網掩碼是255.255.252.0,所以我的虛擬機器ip地址可以在192.168.0.2-192.168.3.255之間任意選擇(除了物理主機的ip)。若你的虛擬機器是使用nat模式,可能就是,如:以我的虛擬機器為例,nat閘道器是192.168.117.2,子網掩碼為255.255.255.0,所以虛擬機器的ip地址可以在192.168.117.3-192.168.117.255之間任意選擇。
此時網路卡已經成功開啟。
8.再次ping步驟4的ip或域名,檢視具體情況
檢查本機網路協議
檢查網路卡鏈路
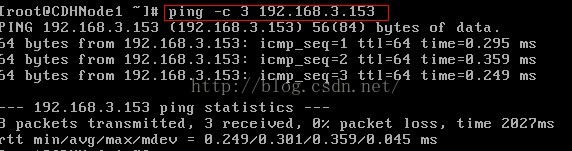
檢查Nat閘道器
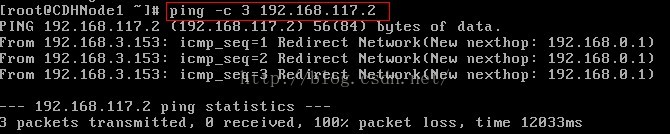
檢查外網
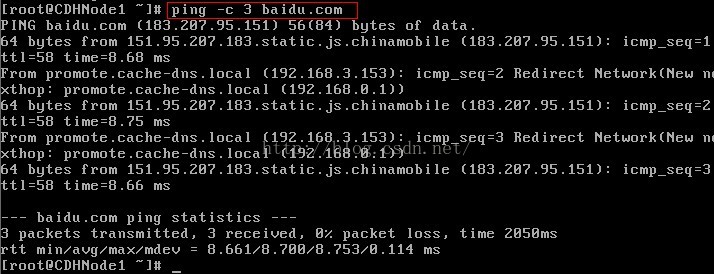
此時虛擬機器連線網際網路成功,但使用dhcp(動態主機配置協議)配置ip地址,此時的IP地址時動態生成的,不方便以後hadoop叢集環境的搭建。所以我們還需要配置靜態Ip地址,配置詳情,下面細說。
9、使用ifconfig命令可以檢視動態ip地址為192.168.3.188,所以接下來我們把此ip作為CDHNode1的靜態ip地址。注:你可以使用你的動態ip作為你當前主機的靜態ip。然後後面幾臺IP地址可以緊跟著設定成,如192.168.3.189。DHCP生成ip地址是隨機的,你可具體問題具體分析。
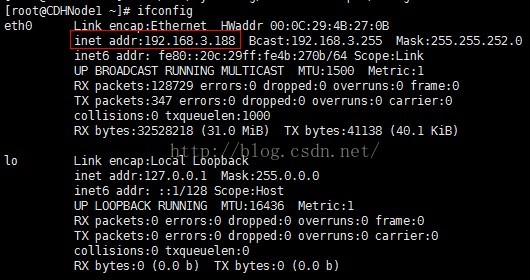
10、修改網路卡配置資訊,把BOOTPROTO=dhcp修改為BOOTPROTO=static,並且新增上設定的ip地址,子網掩碼,和閘道器。

注意:由於我是在兩臺pc上配置叢集環境,所以我使用的是橋接模式。若你是在一臺主機上建議你使用Nat(網路地址轉換)模式。因為nat模式的閘道器在不同的電腦上虛擬機器VMWare虛擬出來的網段是不同的。不方便使用Xshell連線。
下面是橋接模式的配置,IPADDR是設定ip地址,NETMASK(子網掩碼)與GATEWAY(閘道器)可以設定成與物理主機一樣的NETMASK(子網掩碼)與GATEWAY(閘道器)。注:物理主機ip配置具體檢視,看上面的步驟4。
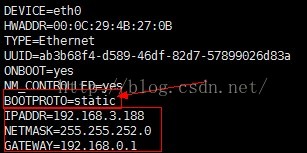
下面是Nat模式的配置,IPADDR是設定ip地址,NETMASK(子網掩碼)與GATEWAY(閘道器)可以設定成與物理主機一樣的NETMASK(子網掩碼)與GATEWAY(閘道器)。注:Nat模式ip配置具體檢視,看上面的步驟4。
上面步驟中我們可以看到Nat模式的閘道器是192.168.117.2,子網掩碼為255.255.255.0
所以具體可配置成
BOOTPROTO=static
IPADDR=192.168.117.40
NETMASK=255.255.255.0
GATEWAY=192.168.117.2
最後按Esc,然後:wq儲存退出。(注意編輯按i或a即可進入編輯模式,具體操作檢視vi命令的使用說明)
11、重啟網路服務

至此網路配置完畢。
下載必備軟體
注:1、在CDHNode1節點上安裝,使用yum命令 ,引數-y表示,下載過程中的自動回答yes,有興趣的話,可以試試不加的情況;install表示從網上下載安裝。
2、使用yum命令安裝軟體必須是root使用者。
1、安裝lrzsz,可以方便在Xshell上,上傳和下載檔案,輸入rz命令,可以上傳檔案,sz命令可以從遠端主機上下載檔案到本地。

2、安裝ssh伺服器。
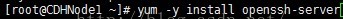
3、安裝ssh客戶端。

使用者建立戶
1、使用useradd命令新增使用者hadoop,並同時建立使用者的home目錄,關於useradd的引數使用可以使用 useradd -h檢視引數

2、可以切換到/home目錄下檢視,是否建立成功
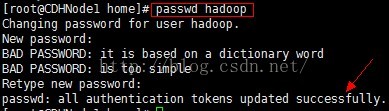
3、為hadoop使用者建立密碼,這是為了接下來使用XShell軟體遠端連線CDHNode1節點做準備,出現successfully表示建立密碼成功,注意:密碼建立必須是root使用者。
4、可以切換到hadoop使用者,使用 su命令,可以看到,此時root@CDHNode1已經改成hadoop@CDHNode1。

5、從hadoop使用者退出,使用exit命令
克隆虛擬機器
由於我們使用VMware建立的Centos虛擬機器,所以我們可以直接克隆虛擬機器,就減少了安裝的時間,提高效率。
若你是在一臺pc機上配置叢集環境,就可以按照以下步驟連續克隆出四個虛擬機器分別是CDHNode2、CDHNode3、CDHNode4、CDHNode5;我是在兩個pc機上配置的所以,我就需要在另一臺pc上重新按照第一臺pc機上安裝CDHNode1一樣,再安裝CDHNode2,然後從CDHNode2克隆CDHNode4、CDHNode5。
下面我以在CDHNode2上克隆出CDHNode5虛擬機器為例,演示以下克隆的步驟。
1、右鍵CDHNode2虛擬機器--》快照--》拍攝快照
2、點選拍攝快照,快照拍攝成功

3、再右鍵CDHNode2虛擬機器--》管理--》克隆
4、下一步
5、選擇現有快照--》下一步
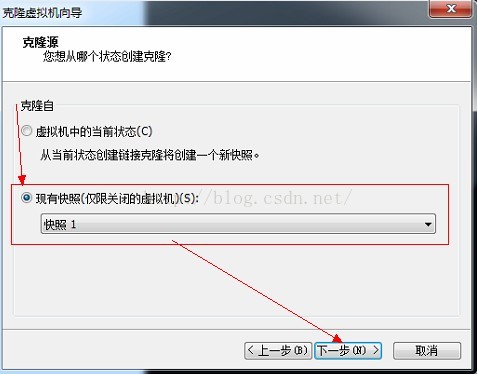
6、選擇建立完整克隆--》下一步
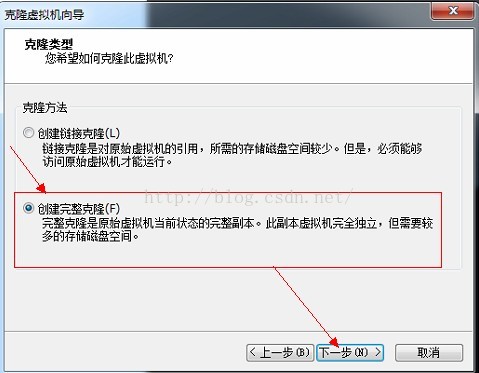
7、輸入虛擬機器名稱,點選完成,等待克隆完成。
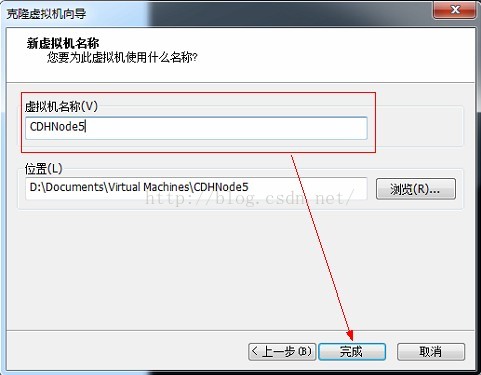
8、至此我們完成了克隆虛擬機器的任務
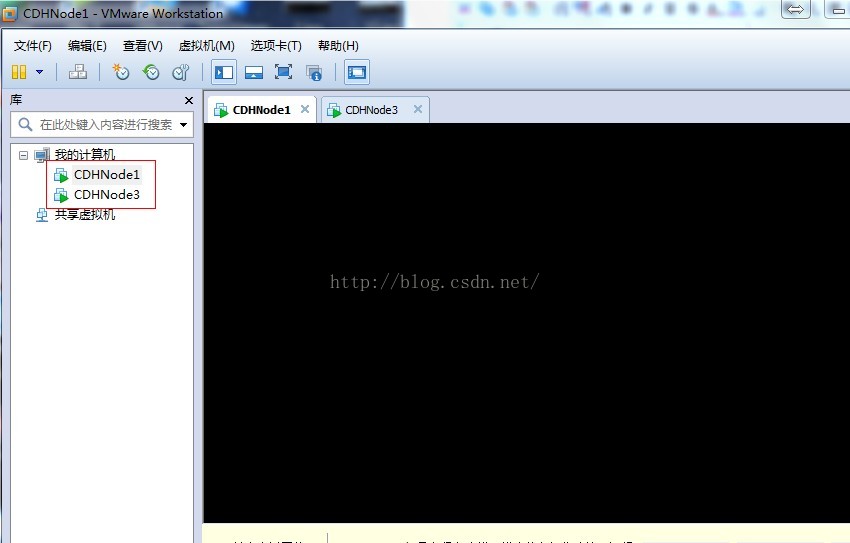
9、接下來是修改配置虛擬機器的網路卡資訊,下面我們在CDHNode5為例,其他節點自己按照下面的自行配置。
首先開啟CDHNode5,此時顯示的主機名稱為CDHNode2,因為CDHNode5是從CDHNode2克隆來的,所以主機名稱還是CDHNode2。
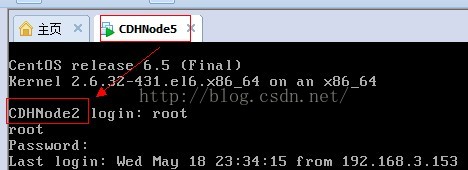
10、暫時不該主機名,我們先檢視一下,此時顯示沒有網路卡

11、克隆後的網路卡變成了eth1,如果想改回eth0,則需要修改配置檔案70-persistent-net.rules配置檔案

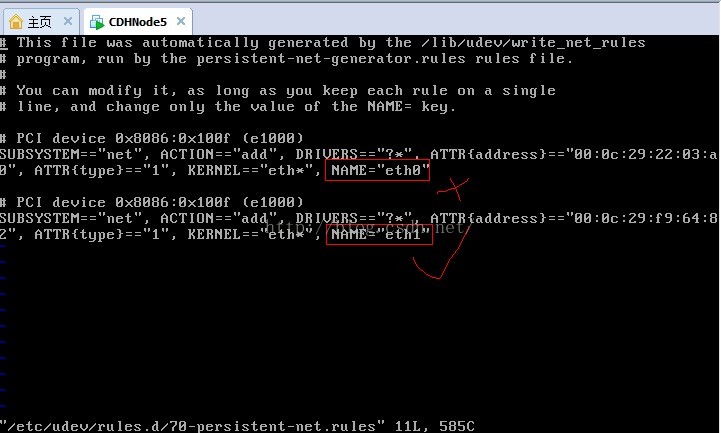
11、我們先設定行號輸入:set number,我們需要修改第8行和第11行,然後輸入i或a進入編輯模式,使用#註釋第8行,並把第10行的eth1改為eth0,可以記一下第二個網路卡的mac硬體地址
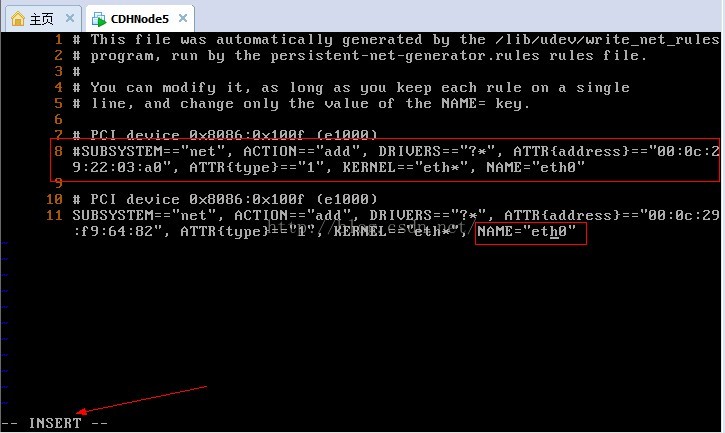
12、我們先移除網路卡e1000,使用modprobe -r e1000命令
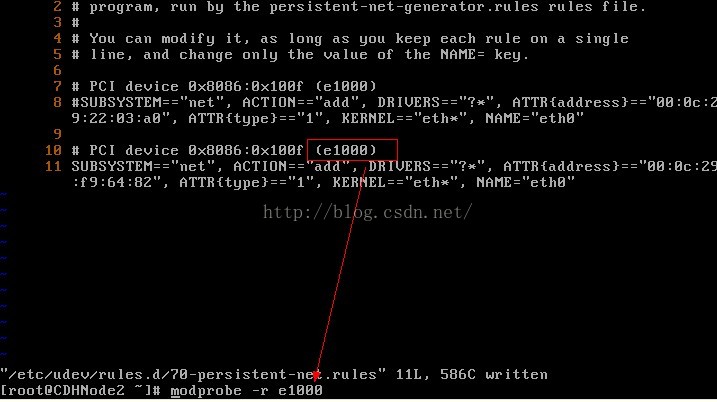
13、重新安裝網路卡e000

14、修改網路卡配置資訊

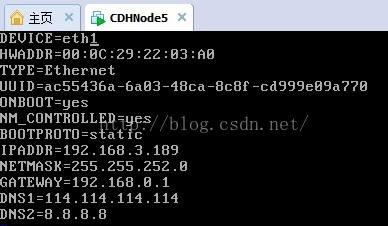
15、把裝置號修改為DEVICE=eth0,先註釋掉mac地址(硬體地址),在修改ip地址。

16、重啟網路服務

注意:如果不正確,ip已經被使用,可以重新設定成其他的ip地址,按照以上方式配置。
17、接下來是修改主機名,把CDHNode2改成CDHNode5


18、重啟主機後,就可以看到主機名的變成CDHNode5。


19、由於我們註釋了mac地址,所以我們開改成新的mac地址,首先使用ifconfig檢視新的mac地址,記住下面地址,

20、進入ifcfg-eth0檔案,修改HWaddr,改為剛才檢視的mac地址

再使用service network restart命令重啟網路服務。至此配置完畢,最後按Esc,然後:wq儲存退出。
接下來在其他節點上進行相應的配置。
配置host檔案
在5個節點上分別配置hosts檔案,注意使用root使用者配置


最後按Esc,然後:wq儲存退出。
關閉防火牆
在所有節點上使用root使用者,關閉防火牆。由於要使用ssh協議來進行主機間的無密碼訪問,所以需要關閉防火牆。
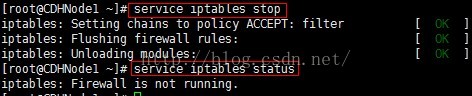
1、首先檢視防火牆的狀態,顯示防火牆正在執行

2、然後永久關閉防火牆,使用chkconfig iptables off命令,此時當前虛擬機器的防火牆還沒有關閉。只有在關機重啟後才能生效。
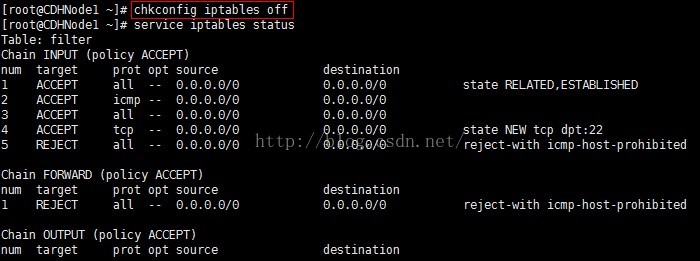
3、關閉ipv6的防火牆

4、也可以使用service iptables stop命令,暫時關閉當前主機的防火牆。
5、關閉selinux


將其SELINUX=enforcing設定為SELINUX=disabled

最後按Esc,然後:wq儲存退出。
時間同步
當我們每一次啟動叢集時,時間基本上是不同步的,所以需要時間同步。要求所以節點保持一致的時間。
注意:使用root使用者修改,5個節點同時修改
1、我們先使用date命令檢視當前系統時間

如果系統時間與當前時間不一致,可以按照如下方式修改
2、檢視時區設定是否正確。我們設定的統一時區為Asia/Shanghai,如果時區設定不正確,可以按照如下步驟把當前時區修改為上海。

3、下面我們使用ntp(網路時間協議)同步時間。如果ntp命令不存在,則需要線上安裝ntp

4、安裝ntp後,我們可以使用ntpdate命令進行聯網時間同步。

5、最後我們在使用date命令檢視,時間是否同步成功。
注意:在橋接模式下,上述同步時鐘的方法行不通。換一下方法,我們使用手動配置時間,在xshell中,全部xshell會話的方式的方式同時更改所有節點。
a、使用date檢視時間
b、設定日期,比如設定成2016年5月20日

c、設定時間,比如設定成下午1點48分45秒

d、最後將當前時間和日期寫入BIOS,避免重啟後失效

使用Xshell遠端連線centos系統
由於在centos中複製修改等操作方便,我們使用windows上的一款遠端連線工具Xshell,下面簡單講一下連線步驟。你需要先從網上下載安裝Xshell和Xftp(可以用來視覺化的檔案傳輸)這兩款工具。
連線步驟如下,以連線CDHNode1為例。
1、首先點選新建按鈕,如下;在新建會話屬性對話方塊中輸入名稱和需要連線的主機ip地址。

2、接下來點選左側的使用者身份驗證,輸入要登入主機的使用者名稱和密碼,點選確定,此時建立成功。

3、在開啟會話對話方塊中選中剛建立的CDHNode1,然後點選連線

4、此時連線成功,即可進行遠端操作

5、為了以後方便開啟遠端主機,我們可以把當前連線的主機新增到連結欄中,只需點選新增到連結欄按鈕即可新增
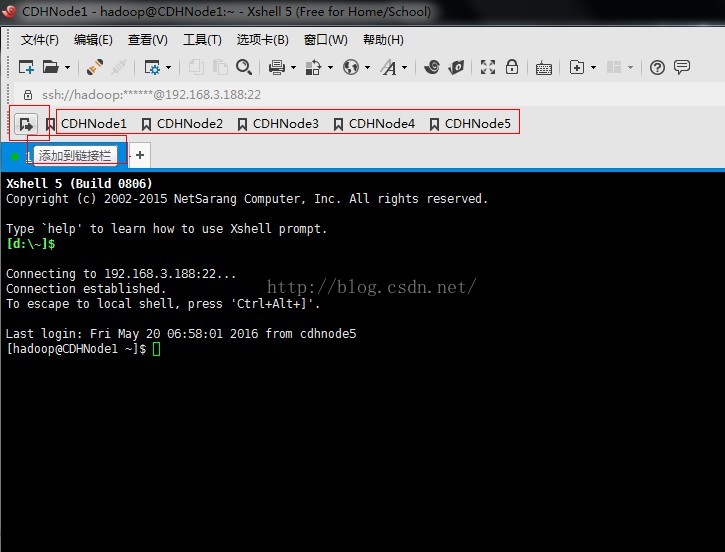
6、為了防止一個命令在多個主機中輸入,我們也可以使用撰寫欄,快速的把一個命令傳送到所以開啟的會話框。提示:撰寫欄可以在檢視選單欄中開啟。

配置免密碼登入ssh
接上面的配置,我們已經使用Xshell遠端登入上五個節點。下面我們就配置免密碼登入hadoop使用者,如果你使用root使用者登入的,需要先切換到hadoop使用者,使用 su hadoop命令切換。步驟如下:
1、首先切換到hadoop的家目錄下,使用cd /home/hadoop命令來切換。然後在hadoop家目錄下建立 .ssh目錄。

2、然後生成hadoop使用者的rsa(非對稱加密演算法),執行如下命令後,一直回車,即可生成hadoop的公鑰和私鑰

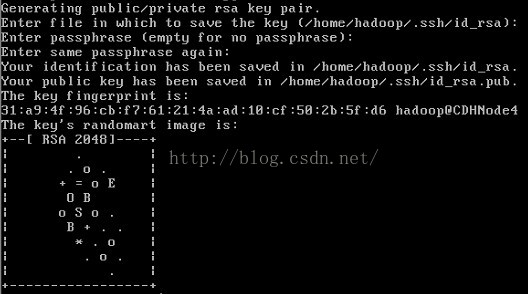
3、切換到 .ssh目錄下,即可看到已經生成的公鑰和私鑰。

4、按照上面的步驟,在所有節點上生成公鑰和私鑰,接下來需要把所有節點的公鑰發到CDHNode1節點的授權檔案。如下圖,我們使用Xshell最下方的撰寫欄向所有節點傳送ssh-copy-id CDHNode1命令。
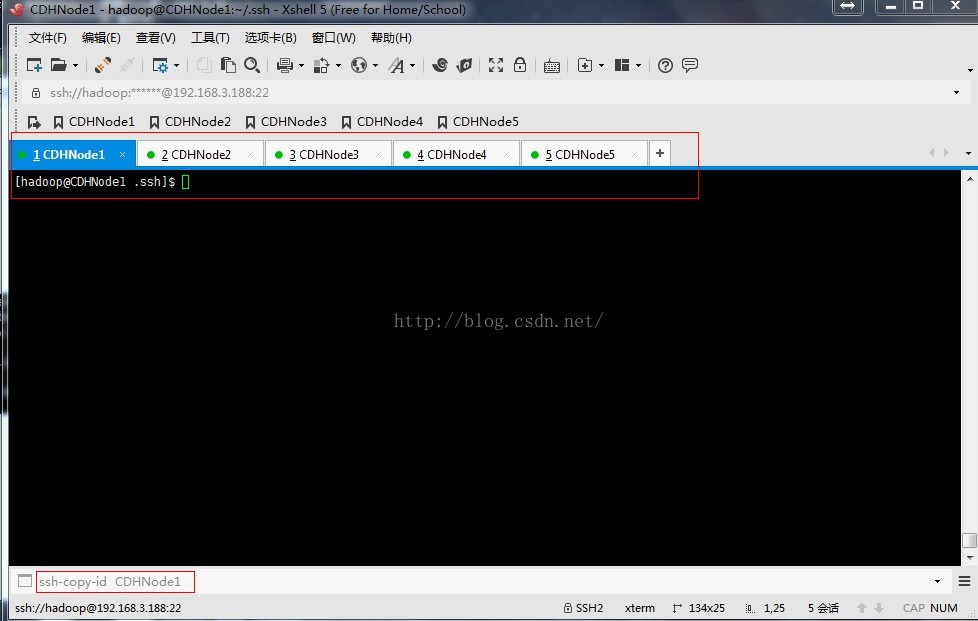
5、執行結果如下,每個節點包括CDHNode1節點,都把自己剛才生成的公鑰 id_rsa.pub檔案傳送到CDHNode1節點的授權檔案authorized_keys中。

注意:也可以在所有節點使用
cat ~/.ssh/id_rsa.pub | ssh hadoop@CDHNode1 'cat >> ~/.ssh/authorized_keys' 命令把自己的公鑰追加到CDHNode1節點的授權檔案authorized_keys中。
6、可以檢視CDHNode1節點的授權檔案authorized_keys中是否把所有節點的公鑰都新增到此檔案中,若有節點沒有加入,則可以使用上一步命令重新新增。

7、然後我們就把這個檔案拷貝到其他節點的.ssh目錄下。


8、根據下圖,可以看到CDHNode5下已經複製了一份authorized_keys檔案。下面以CDHNode5為例,修改.ssh目錄以及.ssh目錄下的檔案的許可權。其他節點按照如下步驟 一 一 修改。

9、修改好許可權後,至此ssh配置成功,可以使用ssh測試是否配置成功,第一次使用ssh連線其他節點時需要輸入yes,退出使用exit命令,在第二次登陸時,就不需要在輸入,如下圖直接登陸並顯示最後登入時間。

提示:rsa非對稱加密演算法是把公鑰傳送個對方,對方使用公鑰對資料進行加密後,自己在使用私鑰對資料進行解密。
免密碼登入的原理:
- 需要依靠金鑰,也就是自己建立的一對金鑰,並把公鑰放到需要訪問的伺服器上。
- 如果你需要連線SSH伺服器,客戶端軟體就會向伺服器發出請求,請求用你的金鑰進行安全驗證。
- 伺服器收到請求後,現在該伺服器上的主目錄下尋找你的公鑰,然後把它和你傳送過來的公鑰進行比較。如果兩個金鑰一致,服務端就用公鑰加密“質詢”(challenge),並把它傳送給客戶端軟體。
- 客戶端收到“質詢”後,就用你的私鑰進行解密。再把它傳送個伺服器。
- 伺服器比較傳送來的“質詢”和原先的是否一致,如果一致則進行授權,完成建立會話的操作。
指令碼工具的使用
此處使用指令碼檔案的目的是為了簡化安裝步驟,畢竟有五個節點,如果全部使用命令一個一個操作,太費時費力了。為了簡化操作,我們使用指令碼檔案來幫助我們執行多個重複的命令。就就相當於windows的批處理,把所有的命令集中起來,一個命令完成多個操作。
下面我們在CDHNode1節點上新建三個檔案,deploy.conf(配置檔案),deploy.sh(實現檔案複製的shell指令碼檔案),runRemoteCdm.sh(在遠端節點上執行命令的shell指令碼檔案)。
1、我們把三個檔案放到/home/hadoop/tools目錄下,先建立此目錄
2、然後切換到tools目錄下
[hadoop@CDHNode1 ~]$cd tools
3、首先建立deploy.conf檔案
先解釋一下這個檔案,這個檔案就是配置在每個幾點上的功能,就是上面所講的主機規劃。比如zookeeper安裝在CDHnode1、CDHnode2、CDHnode3這三個主機上。其他的自己對比檢視。
4、建立deploy.sh檔案
5、建立 runRemoteCmd.sh 指令碼檔案
6、給指令碼檔案新增執行許可權。
7、把tools目錄新增到環境變數PATH中。
新增下面內容
8、是環境變數及時生效
9、在CDHNode1節點上,通過runRemoteCmd.sh指令碼,一鍵建立所有節點的軟體安裝目錄/home/hadoop/app。
我們先來說一下軟體的安裝步驟:
對於解壓安裝的軟體,安裝步驟為:
- 使用rz命令上傳要安裝的檔案,此命令只能在遠端連線工具xshell上執行,不能再centos虛擬機器上執行
- 使用tar -zxvf softwarename.tar.gz
- 修改配置檔案(根據需要而定,有時可省略)
- 在環境變數檔案中配置環境變數
- 使用source 是環境變數檔案即時生效。
安裝JDK
首先在CDHNode1上安裝jdk,然後複製到其他節點。
1、上傳使用rz後,找到下載的jdk檔案(jdk-7u79-linux-x64.tar.gz )即可,選擇後就可以上傳,上傳需要時間。
2、解壓jdk-7u79-linux-x64.tar.gz
3、修改jdk的名字,刪除上傳的壓縮檔案jdk-7u79-linux-x64.tar.gz
4、配置環境變數
新增
5、使環境變數檔案即時生效
6、檢視是否安裝成功,檢視Java版本
CDHNode2、CDHNode3、CDHNode4、CDHNode5加點重複CDHNode1上的jdk配置即可。就是在其他節點上從第4步開始配置。
安裝Zookeeper
首先在CDHNode1上安裝Zookeeper,然後複製到其他節點。
1、將本地下載好的zookeeper-3.4.6.tar.gz安裝包,上傳至CDHNode1節點下的/home/hadoop/app目錄下。
2、解壓zookeeper-3.4.6.tar.gz
3、修改zookeeper的名字,刪除上傳的壓縮檔案zookeeper-3.4.6.tar.gz
4、修改Zookeeper中的配置檔案。
[hadoop@CDHNode1 app]$ cd /home/hadoop/app/zookeeper/conf/
5、配置環境變數
新增
6、使環境變數檔案即時生效
7、通過遠端命令deploy.sh將Zookeeper安裝目錄拷貝到其他節點(CDHNode2、CDHNode3)上面
8、通過遠端命令runRemoteCmd.sh在所有的zookeeper節點(CDHNode1、CDHNode2、CDHNode3)上面建立目錄:
9、然後分別在CDHNode1、CDHNode2、CDHNode3上面,進入zkdata目錄下,建立檔案myid,裡面的內容分別填充為:1、2、3, 這裡我們以CDHNode1為例。
//輸入數字1
CDHNode2輸入數字2、CDHNode3輸入數字3。
10、在CDHNode2、CDHNode3上面配置Zookeeper環境變數。按照第5、6步配置。
11、使用runRemoteCmd.sh 指令碼,啟動所有節點(CDHNode1、CDHNode2、CDHNode3)上面的Zookeeper。
12、檢視所有節點上面的QuorumPeerMain程式是否啟動。
13、檢視所有Zookeeper節點狀態。
如果一個節點為leader,另2個節點為follower,則說明Zookeeper安裝成功。
注意:QuorumPeerMain可能不顯示在jps程式中,可以使用bin/zkServer.sh status 檢視狀態,無法啟動的原因可以檢視zookeeper.out檔案,檢視錯誤原因
安裝hadoop
首先在CDHNode1上安裝hadoop,然後複製到其他節點。
1、將本地下載好的hadoop-2.6.0-cdh5.4.5.tar.gz安裝包,上傳至CDHNode1節點下的/home/hadoop/app目錄下。
2、解壓hadoop-2.6.0-cdh5.4.5.tar.gz
3、修改hadoop的名字,刪除上傳的壓縮檔案hadoop-2.6.0-cdh5.4.5.tar.gz
4、配置環境變數
新增5、使環境變數檔案即時生效
6、切換到/home/hadoop/app/hadoop/etc/hadoop/目錄下,修改配置檔案。
配置HDFS
配置hadoop-env.sh
[hadoop@CDHNode1 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
配置core-site.xml
配置hdfs-site.xml
配置 slave
YARN安裝配置
配置mapred-site.xml
配置yarn-site.xml
向所有節點分發hadoop安裝包。
[hadoop@CDHNode1 app]$ deploy.sh hadoop /home/hadoop/app/ slave
按照目錄的規劃建立好目錄(用於存放資料的目錄):
當你的在初始化工程中出錯,要把相關目錄的檔案刪除,然後再重新初始化
叢集初始化
1、啟動所有節點上面的Zookeeper程式
[hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
2、啟動所有節點上面的journalnode程式
[hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all
3、首先在主節點上(比如,CDHNode1)執行格式化
[hadoop@CDHNode2 hadoop]$ bin/hdfs namenode -bootstrapStandby //同步主節點和備節點之間的後設資料
5、CDHNode2同步完資料後,緊接著在CDHNode1節點上,按下ctrl+c來結束namenode程式。 然後關閉所有節點上面的journalnode程式
[hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode" all //然後停掉各節點的journalnode
7、驗證是否啟動成功
通過web介面檢視namenode啟動情況。
http://CDHNode1:50070
192.168.3.188 CDHNode1
192.168.3.189 CDHNode2
192.168.3.190 CDHNode3
192.168.3.191 CDHNode4
192.168.3.192 CDHNode5
上傳檔案至hdfs
[hadoop@CDHNode1 hadoop]$ vi a.txt //本地建立一個a.txt檔案
hadoop CDH
hello world
CDH hadoop
[hadoop@CDHNode1 hadoop]$ hdfs dfs -mkdir /test //在hdfs上建立一個檔案目錄
[hadoop@CDHNode1 hadoop]$ hdfs dfs -put djt.txt /test //向hdfs上傳一個檔案
[hadoop@CDHNode1 hadoop]$ hdfs dfs -ls /test //檢視a.txt是否上傳成功
如果上面操作沒有問題說明hdfs配置成功。
啟動YARN
1、在CDHNode1節點上執行。
[hadoop@CDHNode1 hadoop]$ sbin/start-yarn.sh
2、在CDHNode2節點上面執行。
[hadoop@CDHNode2 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
同時開啟一下web介面。
http://CDHNode1:8088
http://CDHNode2:8088
關閉其中一個resourcemanager,然後再啟動,看看這個過程的web介面變化。
3、檢查一下ResourceManager狀態
[hadoop@CDHNode1 hadoop]$ bin/yarn rmadmin -getServiceState rm1
[hadoop@CDHNode1 hadoop]$ bin/yarn rmadmin -getServiceState rm2
4、Wordcount示例測試
[hadoop@djt11 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /test/a.txt /test/out/
如果上面執行沒有異常,說明YARN安裝成功。
叢集關啟順序
關閉YARN
a、在CDHNode2節點上面執行
b、在CDHNode1節點上執行
c、關閉HDFS
d、關閉zookeeper
再次啟動叢集
a、啟動zookeeper
b、啟動HDFS
c、在CDHNode1節點上執行
d、在CDHNode2節點上面執行
後續再編寫HBase,hive等的安裝
轉載來自:http://blog.csdn.net/u010270403/article/details/51446674
相關文章
- hadoop叢集環境搭建Hadoop
- HADOOP SPARK 叢集環境搭建HadoopSpark
- Hadoop叢集安裝-CDH5(5臺伺服器叢集)HadoopH5伺服器
- Ubuntu上搭建Hadoop叢集環境的步驟UbuntuHadoop
- Linux 下 Hadoop 2.6.0 叢集環境的搭建LinuxHadoop
- Hadoop叢集之 ZooKeeper和Hbase環境搭建Hadoop
- hadoop叢集搭建——單節點(偽分散式)Hadoop分散式
- Linux下Hadoop2.6.0叢集環境的搭建LinuxHadoop
- Hadoop叢集安裝-CDH5(3臺伺服器叢集)HadoopH5伺服器
- 【環境搭建】RocketMQ叢集搭建MQ
- Hadoop框架:叢集模式下分散式環境搭建Hadoop框架模式分散式
- hadoop2.6.0版本叢集環境搭建Hadoop
- Glassfish叢集環境的搭建
- Zookeeper 叢集環境搭建
- 一個4節點Hadoop叢集的配置示例Hadoop
- hadoop之旅9-centerOS7 : hbase叢集環境搭建HadoopROS
- Linux 環境下搭建Hadoop叢集(全分佈)LinuxHadoop
- es 5.5.3叢集環境搭建
- 4.2 叢集節點初步搭建
- 從 0 開始使用 Docker 快速搭建 Hadoop 叢集環境DockerHadoop
- Mac 環境下 Redis 叢集的搭建MacRedis
- consul 多節點/單節點叢集搭建
- Redis叢集環境搭建實踐Redis
- 12. Redis叢集環境搭建Redis
- Hadoop叢集環境啟動順序Hadoop
- MongoDB叢集搭建(包括隱藏節點,仲裁節點)MongoDB
- Hadoop叢集搭建Hadoop
- Hadoop搭建叢集Hadoop
- 安裝 Hadoop:設定單節點 Hadoop 叢集Hadoop
- 高可用叢集環境搭建-留檔
- k8s——搭建叢集環境K8S
- [Hadoop踩坑]叢集分散式環境配置Hadoop分散式
- hadoop叢集多節點安裝詳解Hadoop
- linux搭建kafka叢集,多master節點叢集說明LinuxKafkaAST
- 生產環境的redis高可用叢集搭建Redis
- PC基於Linux的叢集環境搭建?Linux
- 4.4 Hadoop叢集搭建Hadoop
- Hadoop叢集搭建(一)Hadoop