一個物件佔多少位元組?
關於物件的大小,對於C/C++來說,都是有sizeof函式可以直接獲取的,但是Java似乎沒有這樣的方法。不過還好,在JDK1.5之後引入了Instrumentation類,這個類提供了計算物件記憶體佔用量的方法。至於具體Instrumentation類怎麼用就不說了,可以參看這篇文章如何精確地測量java物件的大小。
不過有一點不同的是,這篇文章使用命令列傳入JVM引數來指定代理,這裡我通過Eclipse設定JVM引數:
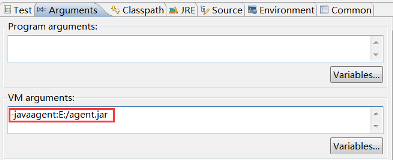
後面的是我打的agent.jar的具體路徑。剩下的就不說了,看一下測試程式碼:
1 public class JVMSizeofTest { 2 3 @Test 4 public void testSize() { 5 System.out.println("Object物件的大小:" + JVMSizeof.sizeOf(new Object()) + "位元組"); 6 System.out.println("字元a的大小:" + JVMSizeof.sizeOf('a') + "位元組"); 7 System.out.println("整型1的大小:" + JVMSizeof.sizeOf(new Integer(1)) + "位元組"); 8 System.out.println("字串aaaaa的大小:" + JVMSizeof.sizeOf(new String("aaaaa")) + "位元組"); 9 System.out.println("char型陣列(長度為1)的大小:" + JVMSizeof.sizeOf(new char[1]) + "位元組"); 10 } 11 12 }
執行結果為:
Object物件的大小:16位元組
字元a的大小:16位元組
整型1的大小:16位元組
字串aaaaa的大小:24位元組
char型陣列(長度為1)的大小:24位元組
接著,程式碼不變,加入一條虛擬機器引數"-XX:-UseCompressedOops",再執行一遍測試類,執行結果為:
Object物件的大小:16位元組
字元a的大小:24位元組
整型1的大小:24位元組
字串aaaaa的大小:32位元組
char型陣列(長度為1)的大小:32位元組
後文來詳細解釋一下原因。
Java物件大小計算方法
JVM對於普通物件和陣列物件的大小計算方式有所不同,我畫了一張圖說明:

解釋一下其中每個部分:
- Mark Word:儲存物件執行時記錄資訊,佔用記憶體大小與機器位數一樣,即32位機佔4位元組,64位機佔8位元組
- 後設資料指標:指向描述型別的Klass物件(Java類的C++對等體)的指標,Klass物件包含了例項物件所屬型別的後設資料,因此該欄位被稱為後設資料指標,JVM在執行時將頻繁使用這個指標定位到位於方法區內的型別資訊。這個資料的大小稍後說
- 陣列長度:陣列物件特有,一個指向int型的引用型別,用於描述陣列長度,這個資料的大小和後設資料指標大小相同,同樣稍後說
- 例項資料:例項資料就是8大基本資料型別byte、short、int、long、float、double、char、boolean(物件型別也是由這8大基本資料型別複合而成),每種資料型別佔多少位元組就不一一例舉了
- 填充:不定,HotSpot的對齊方式為8位元組對齊,即一個物件必須為8位元組的整數倍,因此如果最後前面的資料大小為17則填充7,前面的資料大小為18則填充6,以此類推
為了保證效率,Java編譯期在編譯Java物件的時候,通過欄位型別對Java物件的欄位會進行排序,具體順序如下表所示:
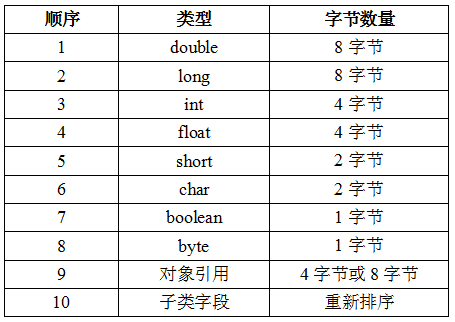
瞭解這個是很有用的,我們可以通過在欄位時間通過填充長整型變數的方式把熱點變數隔離在不同的快取行中,減少偽同步,在多核CPU中極大地提升效率,這個以後有機會寫文章專門講解。
最後再說說後設資料指標的大小。後設資料指標是一個引用型別,因此正常來說64位機後設資料指標應當為8位元組,32位機後設資料指標應當為4位元組,但是HotSpot中有一項優化是對後設資料型別指標進行壓縮儲存,使用JVM引數:
- -XX:+UseCompressedOops開啟壓縮
- -XX:-UseCompressedOops關閉壓縮
HotSpot預設是前者,即開啟後設資料指標壓縮,當開啟壓縮的時候,64位機上的後設資料指標將佔據4個位元組的大小。換句話說就是當開啟壓縮的時候,64位機上的引用將佔據4個位元組,否則是正常的8位元組。
Java物件記憶體大小計算
有了上面的理論基礎,我們就可以分析JVMSizeofTest類的執行結果及為什麼加入了"-XX:-UseCompressedOops"這條引數後同一個物件的大小會有差異了。
首先是Object物件的大小:
- 開啟指標壓縮時,8位元組Mark Word + 4位元組後設資料指標 = 12位元組,由於12位元組不是8的倍數,因此填充4位元組,物件Object佔據16位元組記憶體
- 關閉指標壓縮時,8位元組Mark Word + 8位元組後設資料指標 = 16位元組,由於16位元組正好是8的倍數,因此不需要填充位元組,物件Object佔據16位元組記憶體
接著是字元'a'的大小:
- 開啟指標壓縮時,8位元組Mark Word + 4位元組後設資料指標 + 1位元組char = 13位元組,由於13位元組不是8的倍數,因此填充3位元組,字元'a'佔據16位元組記憶體
- 關閉指標壓縮時,8位元組Mark Word + 8位元組後設資料指標 + 1位元組char = 17位元組,由於17位元組不是8的倍數,因此填充7位元組,字元'a'佔據24位元組記憶體
接著是整型1的大小:
- 開啟指標壓縮時,8位元組Mark Word + 4位元組後設資料指標 + 4位元組int = 16位元組,由於16位元組正好是8的倍數,因此不需要填充位元組,整型1佔據16位元組記憶體
- 關閉指標壓縮時,8位元組Mark Word + 8位元組後設資料指標 + 4位元組int = 20位元組,由於20位元組正好是8的倍數,因此填充4位元組,整型1佔據24位元組記憶體
接著是字串"aaaaa"的大小,所有靜態欄位不需要管,只關注例項欄位,String物件中例項欄位有"char value[]"與"int hash",由此可知:
- 開啟指標壓縮時,8位元組Mark Word + 4位元組後設資料指標 + 4位元組引用 + 4位元組int = 20位元組,由於20位元組不是8的倍數,因此填充4位元組,字串"aaaaa"佔據24位元組記憶體
- 關閉指標壓縮時,8位元組Mark Word + 8位元組後設資料指標 + 8位元組引用 + 4位元組int = 28位元組,由於28位元組不是8的倍數,因此填充4位元組,字串"aaaaa"佔據32位元組記憶體
最後是長度為1的char型陣列的大小:
- 開啟指標壓縮時,8位元組的Mark Word + 4位元組的後設資料指標 + 4位元組的陣列大小引用 + 1位元組char = 17位元組,由於17位元組不是8的倍數,因此填充7位元組,長度為1的char型陣列佔據24位元組記憶體
- 關閉指標壓縮時,8位元組的Mark Word + 8位元組的後設資料指標 + 8位元組的陣列大小引用 + 1位元組char = 25位元組,由於25位元組不是8的倍數,因此填充7位元組,長度為1的char型陣列佔據32位元組記憶體
Mark Word
Mark Word前面已經看到過了,它是Java物件頭中很重要的一部分。Mark Word儲存的是物件自身的執行資料,如雜湊碼(HashCode)、GC分代年齡、鎖狀態標識、執行緒持有的鎖、偏向執行緒ID、偏向時間戳等等。
不過由於物件需要儲存的執行時資料很多,其實已經超出了32位、64位Bitmap結構所能記錄的限度,但是物件頭是與物件自身定義的資料無關的額外儲存成本,考慮到虛擬機器的空間效率,Mark Word被設計成一個非固定的資料結構以便在極小的空間記憶體儲儘量多的資訊。例如在32位的HotSpot虛擬機器中物件未被鎖定的狀態下,Mark Word的32個Bits空間中的25Bits用於儲存物件雜湊碼(HashCode),4Bits用於儲存物件分代年齡,2Bits用於儲存鎖標識位,1Bit固定位0。在其他狀態(輕量級鎖定、重量級鎖定、GC標記、可偏向)下物件的儲存內容如下圖所示:

這裡要特別關注的是鎖狀態,後文將對鎖狀態及鎖狀態的變化進行研究。
鎖的升級
如上圖所示,鎖的狀態共有四種:無鎖態、偏向鎖、輕量級鎖和重量級鎖,其中偏向鎖和輕量級鎖是JDK1.6開始為了減少獲得鎖和釋放鎖帶來的效能消耗而引入的。
四種鎖的狀態會隨著競爭情況逐漸升級,鎖可以升級但是不能降級,意味著偏向鎖可以升級為輕量級鎖但是輕量級鎖不能降級為偏向鎖,目的是為了提高獲得鎖和釋放鎖的效率。用一張圖表示這種關係:

偏向鎖
HotSpot作者經過以往的研究發現大多數情況下鎖不僅不存在多執行緒競爭,而且總是由同一執行緒多次獲得,為了讓執行緒獲得鎖的程式碼更低因此引入了偏向鎖。偏向鎖的獲取過程為:
- 訪問Mark Word中偏向鎖的標識是否設定為1,所標誌位是否為01----確認為可偏向狀態
- 如果為可偏向狀態,則測試執行緒id是否指向當前執行緒,如果是,執行(5),否則執行(3)
- 如果執行緒id併為指向當前執行緒,通過CAS操作競爭鎖。如果競爭成功,則將Mark Word中的執行緒id設定為當前執行緒id,然後執行(5);如果競爭失敗,執行(4)
- 如果CAS獲取偏向鎖失敗,則表示有競爭。當達到全域性安全點(safepoint)時獲得偏向鎖的執行緒被掛起,偏向鎖升級為輕量級鎖(因為偏向鎖是假設沒有競爭,但是這裡出現了競爭,要對偏向鎖進行升級),然後被阻塞在安全點的執行緒繼續往下執行同步程式碼
- 執行同步程式碼
有獲取就有釋放,偏向鎖的釋放點在於上述的第(4)步,只有遇到其他執行緒嘗試競爭偏向鎖時,持有偏向鎖的執行緒才會釋放鎖,執行緒不會主動去釋放偏向鎖。偏向鎖的釋放過程為:
- 需要等待全域性安全點(在這個時間點上沒有位元組碼正在執行)
- 它會首先暫停擁有偏向鎖的執行緒,判斷鎖物件是否處於被鎖定狀態
- 偏向鎖釋放後恢復到未鎖定(標識位為01)或輕量級鎖(標識位為00)狀態
輕量級鎖
輕量級鎖的加鎖過程為:
- 在程式碼進入同步塊的時候,如果同步物件鎖狀態為無鎖狀態,JVM首先將在當前執行緒的棧幀中建立一個名為鎖記錄(Lock Record)的空間,用於儲存鎖物件目前的Mark Word的拷貝,官方稱之為Displaced Mark Word,此時執行緒堆疊與物件頭的狀態如圖所示

- 拷貝物件頭中的Mark Word複製到鎖記錄中
- 拷貝成功後,JVM將使用CAS操作嘗試將物件的Mark Word更新為指向Lock Record的指標,並將Lock Record裡的owner指標指向Object Mark Word,如果更新成功,則執行步驟(4),否則執行步驟(5)
- 如果更新動作成功,那麼當前執行緒就擁有了該物件的鎖,並且物件Mark Word的鎖標識位設定為00,即表示此物件處於輕量級鎖狀態,此時線堆疊與物件頭的狀態如圖所示
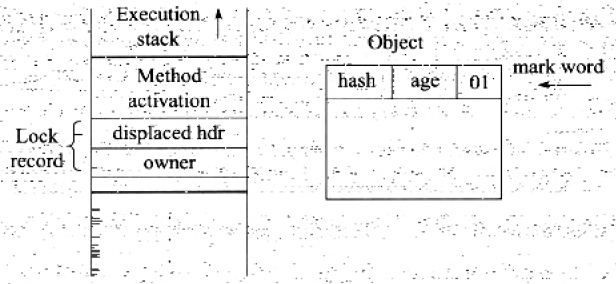
- 如果更新動作失敗,JVM首先會檢查物件的Mark Word是否指向當前執行緒的棧幀,如果是就說明當前執行緒已經擁有了這個物件的鎖,那就可以直接進入同步塊繼續執行。否則說明多個執行緒競爭鎖,輕量級鎖就要膨脹為重量級鎖,鎖標識的狀態值變為10,Mark Word中儲存的就是指向重量級鎖的指標,後面等待鎖的執行緒也要進入阻塞狀態。而當前執行緒變嘗試使用自旋來獲取鎖,自旋就是為了不讓執行緒阻塞,而採用迴圈去獲取鎖的過程
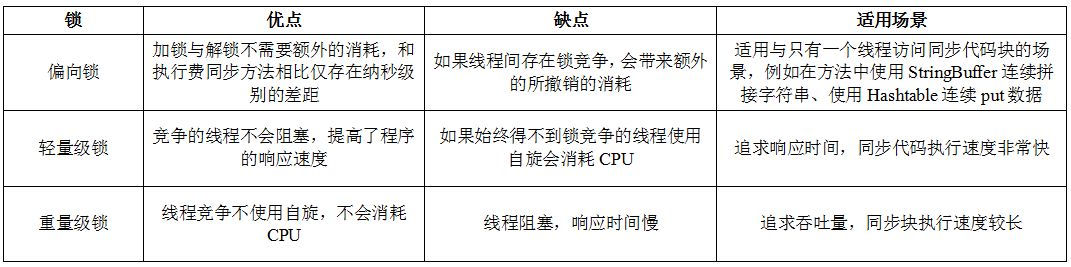
偏向鎖、輕量級鎖與重量級鎖的對比
下面用一張表格來對比一下偏向鎖、輕量級鎖與重量級鎖,網上看到的,我覺得寫得非常好,為了加深記憶我自己又手打了一遍: