前言
平時我們在Java記憶體中的物件,是無法進行IO操作或者網路通訊的,因為在進行IO操作或者網路通訊的時候,人家根本不知道記憶體中的物件是個什麼東西,因此必須將物件以某種方式表示出來,即儲存物件中的狀態。一個Java物件的表示有各種各樣的方式,Java本身也提供給了使用者一種表示物件的方式,那就是序列化。換句話說,序列化只是表示物件的一種方式而已。OK,有了序列化,那麼必然有反序列化,我們先看一下序列化、反序列化是什麼意思。
序列化:將一個物件轉換成一串二進位制表示的位元組陣列,通過儲存或轉移這些位元組資料來達到持久化的目的。
反序列化:將位元組陣列重新構造成物件。
預設序列化
序列化只需要實現java.io.Serializable介面就可以了。序列化的時候有一個serialVersionUID引數,Java序列化機制是通過在執行時判斷類的serialVersionUID來驗證版本一致性的。在進行反序列化,Java虛擬機器會把傳過來的位元組流中的serialVersionUID和本地相應實體類的serialVersionUID進行比較,如果相同就認為是一致的實體類,可以進行反序列化,否則Java虛擬機器會拒絕對這個實體類進行反序列化並丟擲異常。serialVersionUID有兩種生成方式:
1、預設的1L
2、根據類名、介面名、成員方法以及屬性等來生成一個64位的Hash欄位
如果實現java.io.Serializable介面的實體類沒有顯式定義一個名為serialVersionUID、型別為long的變數時,Java序列化機制會根據編譯的.class檔案自動生成一個serialVersionUID,如果.class檔案沒有變化,那麼就算編譯再多次,serialVersionUID也不會變化。換言之,Java為使用者定義了預設的序列化、反序列化方法,其實就是ObjectOutputStream的defaultWriteObject方法和ObjectInputStream的defaultReadObject方法。看一個例子:
1 public class SerializableObject implements Serializable 2 { 3 private static final long serialVersionUID = 1L; 4 5 private String str0; 6 private transient String str1; 7 private static String str2 = "abc"; 8 9 public SerializableObject(String str0, String str1) 10 { 11 this.str0 = str0; 12 this.str1 = str1; 13 } 14 15 public String getStr0() 16 { 17 return str0; 18 } 19 20 public String getStr1() 21 { 22 return str1; 23 } 24 }
1 public static void main(String[] args) throws Exception 2 { 3 File file = new File("D:" + File.separator + "s.txt"); 4 OutputStream os = new FileOutputStream(file); 5 ObjectOutputStream oos = new ObjectOutputStream(os); 6 oos.writeObject(new SerializableObject("str0", "str1")); 7 oos.close(); 8 9 InputStream is = new FileInputStream(file); 10 ObjectInputStream ois = new ObjectInputStream(is); 11 SerializableObject so = (SerializableObject)ois.readObject(); 12 System.out.println("str0 = " + so.getStr0()); 13 System.out.println("str1 = " + so.getStr1()); 14 ois.close(); 15 }
先不執行,用一個二進位制檢視器檢視一下s.txt這個檔案,並詳細解釋一下每一部分的內容。

第1部分是序列化檔案頭
◇AC ED:STREAM_MAGIC序列化協議
◇00 05:STREAM_VERSION序列化協議版本
◇73:TC_OBJECT宣告這是一個新的物件
第2部分是要序列化的類的描述,在這裡是SerializableObject類
◇72:TC_CLASSDESC宣告這裡開始一個新的class
◇00 1F:十進位制的31,表示class名字的長度是31個位元組
◇63 6F 6D ... 65 63 74:表示的是“com.xrq.test.SerializableObject”這一串字元,可以數一下確實是31個位元組
◇00 00 00 00 00 00 00 01:SerialVersion,序列化ID,1
◇02:標記號,宣告該物件支援序列化
◇00 01:該類所包含的域的個數為1個
第3部分是物件中各個屬性項的描述
◇4C:字元"L",表示該屬性是一個物件型別而不是一個基本型別
◇00 04:十進位制的4,表示屬性名的長度
◇73 74 72 30:字串“str0”,屬性名
◇74:TC_STRING,代表一個new String,用String來引用物件
第4部分是該物件父類的資訊,如果沒有父類就沒有這部分。有父類和第2部分差不多
◇00 12:十進位制的18,表示父類的長度
◇4C 6A 61 ... 6E 67 3B:“L/java/lang/String;”表示的是父類屬性
◇78:TC_ENDBLOCKDATA,物件塊結束的標誌
◇70:TC_NULL,說明沒有其他超類的標誌
第5部分輸出物件的屬性項的實際值,如果屬性項是一個物件,這裡還將序列化這個物件,規則和第2部分一樣
◇00 04:十進位制的4,屬性的長度
◇73 74 72 30:字串“str0”,str0的屬性值
從以上對於序列化後的二進位制檔案的解析,我們可以得出以下幾個關鍵的結論:
1、序列化之後儲存的是物件的資訊
2、被宣告為transient的屬性不會被序列化,這就是transient關鍵字的作用
3、被宣告為static的屬性不會被序列化,這個問題可以這麼理解,序列化儲存的是物件的狀態,但是static修飾的變數是屬於類的而不是屬於物件的,因此序列化的時候不會序列化它
接下來執行一下上面的程式碼看一下
str0 = str0 str1 = null
因為str1是一個transient型別的變數,沒有被序列化,因此反序列化出來也是沒有任何內容的,顯示的null,符合我們的結論。
手動指定序列化過程
Java並不強求使用者非要使用預設的序列化方式,使用者也可以按照自己的喜好自己指定自己想要的序列化方式----只要你自己能保證序列化前後能得到想要的資料就好了。手動指定序列化方式的規則是:
進行序列化、反序列化時,虛擬機器會首先試圖呼叫物件裡的writeObject和readObject方法,進行使用者自定義的序列化和反序列化。如果沒有這樣的方法,那麼預設呼叫的是ObjectOutputStream的defaultWriteObject以及ObjectInputStream的defaultReadObject方法。換言之,利用自定義的writeObject方法和readObject方法,使用者可以自己控制序列化和反序列化的過程。
這是非常有用的。比如:
1、有些場景下,某些欄位我們並不想要使用Java提供給我們的序列化方式,而是想要以自定義的方式去序列化它,比如ArrayList的elementData、HashMap的table(至於為什麼在之後寫這兩個類的時候會解釋原因),就可以通過將這些欄位宣告為transient,然後在writeObject和readObject中去使用自己想要的方式去序列化它們
2、因為序列化並不安全,因此有些場景下我們需要對一些敏感欄位進行加密再序列化,然後再反序列化的時候按照同樣的方式進行解密,就在一定程度上保證了安全性了。要這麼做,就必須自己寫writeObject和readObject,writeObject方法在序列化前對欄位加密,readObject方法在序列化之後對欄位解密
上面的例子SerializObject這個類修改一下,主函式不需要修改:
1 public class SerializableObject implements Serializable 2 { 3 private static final long serialVersionUID = 1L; 4 5 private String str0; 6 private transient String str1; 7 private static String str2 = "abc"; 8 9 public SerializableObject(String str0, String str1) 10 { 11 this.str0 = str0; 12 this.str1 = str1; 13 } 14 15 public String getStr0() 16 { 17 return str0; 18 } 19 20 public String getStr1() 21 { 22 return str1; 23 } 24 25 private void writeObject(java.io.ObjectOutputStream s) throws Exception 26 { 27 System.out.println("我想自己控制序列化的過程"); 28 s.defaultWriteObject(); 29 s.writeInt(str1.length()); 30 for (int i = 0; i < str1.length(); i++) 31 s.writeChar(str1.charAt(i)); 32 } 33 34 private void readObject(java.io.ObjectInputStream s) throws Exception 35 { 36 System.out.println("我想自己控制反序列化的過程"); 37 s.defaultReadObject(); 38 int length = s.readInt(); 39 char[] cs = new char[length]; 40 for (int i = 0; i < length; i++) 41 cs[i] = s.readChar(); 42 str1 = new String(cs, 0, length); 43 } 44 }
直接看一下執行結果:
我想自己控制序列化的過程 我想自己控制反序列化的過程 str0 = str0 str1 = str1
看到,程式走到了我們自己寫的writeObject和readObject中,而且被transient修飾的str1也成功序列化、反序列化出來了----因為手動將str1寫入了檔案和從檔案中讀了出來。不妨再看一下s.txt檔案的二進位制:
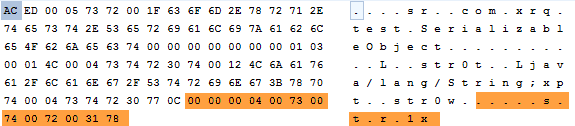
看到橘黃色的部分就是writeObject方法追加的str1的內容。至此,總結一下writeObject和readObject的通常用法:
先通過defaultWriteObject和defaultReadObject方法序列化、反序列化物件,然後在檔案結尾追加需要額外序列化的內容/從檔案的結尾讀取額外需要讀取的內容。
複雜序列化情況總結
雖然Java的序列化能夠保證物件狀態的持久儲存,但是遇到一些物件結構複雜的情況還是比較難處理的,最後對一些複雜的物件情況作一個總結:
1、當父類繼承Serializable介面時,所有子類都可以被序列化
2、子類實現了Serializable介面,父類沒有,父類中的屬性不能序列化(不報錯,資料丟失),但是在子類中屬性仍能正確序列化
3、如果序列化的屬性是物件,則這個物件也必須實現Serializable介面,否則會報錯
4、反序列化時,如果物件的屬性有修改或刪減,則修改的部分屬性會丟失,但不會報錯
5、反序列化時,如果serialVersionUID被修改,則反序列化時會失敗