前言
有這麼一段程式碼:
1 public class TestMain 2 { 3 public static void main(String[] args) 4 { 5 String str0 = "123"; 6 String str1 = "123"; 7 System.out.println(str0 == str1); 8 } 9 }
執行結果是什麼?答案當然是true。對,答案的確是true,但是這是為什麼呢?很多人第一反應肯定是兩個"123"的String當然相等啊,這還要想。但是"=="在Java比較的不是兩個物件的值,而是比較兩個物件的引用是否相等,和兩個String都是"123"又有什麼關係呢?或者我們把程式修改一下
1 public class TestMain 2 { 3 public static void main(String[] args) 4 { 5 String str2 = new String("234"); 6 String str3 = new String("234"); 7 System.out.println(str2 == str3); 8 } 9 }
這時候執行結果就是false了,因為儘管兩個String物件都是"234",但是str2和str3是兩個不同的引用,所以返回的false。OK,圍繞第一段程式碼返回true,第二段程式碼返回false,開始文章的內容。
為什麼String=String?
在JVM中有一塊區域叫做常量池,關於常量池,我在寫虛擬機器的時候有專門提到http://www.cnblogs.com/xrq730/p/4827590.html。常量池中的資料是那些在編譯期間被確定,並被儲存在已編譯的.class檔案中的一些資料。除了包含所有的8種基本資料型別(char、byte、short、int、long、float、double、boolean)外,還有String及其陣列的常量值,另外還有一些以文字形式出現的符號引用。
Java棧的特點是存取速度快(比堆塊),但是空間小,資料生命週期固定,只能生存到方法結束。我們定義的boolean b = true、char c = 'c'、String str = “123”,這些語句,我們拆分為幾部分來看:
1、true、c、123,這些等號右邊的指的是編譯期間可以被確定的內容,都被維護在常量池中
2、b、c、str這些等號左邊第一個出現的指的是一個引用,引用的內容是等號右邊資料在常量池中的地址
3、boolean、char、String這些是引用的型別
棧有一個特點,就是資料共享。回到我們第一個例子,第五行String str0 = "123",編譯的時候,在常量池中建立了一個常量"123",然後走第六行String str1 = "123",先去常量池中找有沒有這個"123",發現有,str1也指向常量池中的"123",所以第七行的str0 == str1返回的是true,因為str0和str1指向的都是常量池中的"123"這個字串的地址。當然如果String str1 = "234",就又不一樣了,因為常量池中沒有"234",所以會在常量池中建立一個"234",然後str1代表的是這個"234"的地址。分析了String,其實其他基本資料型別也都是一樣的:先看常量池中有沒有要建立的資料,有就返回資料的地址,沒有就建立一個。
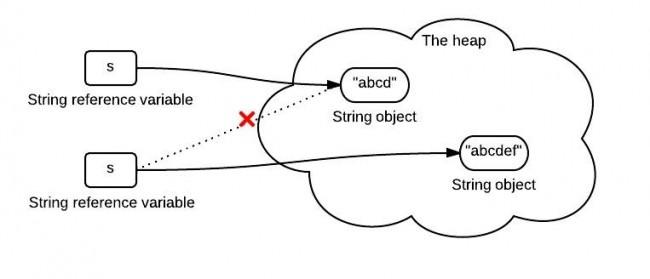
第二個例子呢?Java虛擬機器的直譯器每遇到一個new關鍵字,都會在堆記憶體中開闢一塊記憶體來存放一個String物件,所以str2、str3指向的堆記憶體中雖然儲存的是相等的"234",但是由於是兩塊不同的堆記憶體,因此str2 == str3返回的仍然是false,網上找到一張圖表示一下這個概念:
為什麼要使用StringBuilder和StringBuffer拼接字串?
大家在開發中一定有一個原則是"利用StringBuilder和StringBuffer拼接字串",但是為什麼呢?用一段程式碼來分析一下:
1 public class StringTest { 2 3 @Test 4 public void testStringPlus() { 5 String str = "111"; 6 str += "222"; 7 str += "333"; 8 System.out.println(str); 9 } 10 11 }
這段程式碼,我們找到編譯後的StringTest.class檔案,使用"javap -verbose StringTest"或者"javap -c StringTest"都可以,反編譯一下class獲取到對應的位元組碼:
public void testStringPlus(); Code: 0: ldc #17 // String 111 2: astore_1 3: new #19 // class java/lang/StringBuilder 6: dup 7: aload_1 8: invokestatic #21 // Method java/lang/String.valueOf:(Ljava/lang/Object;)L java/lang/String; 11: invokespecial #27 // Method java/lang/StringBuilder."<init>":(Ljava/lang/S tring;)V 14: ldc #30 // String 222 16: invokevirtual #32 // Method java/lang/StringBuilder.append:(Ljava/lang/Str ing;)Ljava/lang/StringBuilder; 19: invokevirtual #36 // Method java/lang/StringBuilder.toString:()Ljava/lang/ String; 22: astore_1 23: new #19 // class java/lang/StringBuilder 26: dup 27: aload_1 28: invokestatic #21 // Method java/lang/String.valueOf:(Ljava/lang/Object;)L java/lang/String; 31: invokespecial #27 // Method java/lang/StringBuilder."<init>":(Ljava/lang/S tring;)V 34: ldc #40 // String 333 36: invokevirtual #32 // Method java/lang/StringBuilder.append:(Ljava/lang/Str ing;)Ljava/lang/StringBuilder; 39: invokevirtual #36 // Method java/lang/StringBuilder.toString:()Ljava/lang/ String; 42: astore_1 43: getstatic #42 // Field java/lang/System.out:Ljava/io/PrintStream; 46: aload_1 47: invokevirtual #48 // Method java/io/PrintStream.println:(Ljava/lang/String ;)V 50: return }
這段位元組碼不用看得很懂,大致上能明白就好,意思很明顯:編譯器每次碰到"+"的時候,會new一個StringBuilder出來,接著呼叫append方法,在呼叫toString方法,生成新字串。
那麼,這意味著,如果程式碼中有很多的"+",就會每個"+"生成一次StringBuilder,這種方式對記憶體是一種浪費,效率很不好。
在Java中還有一種拼接字串的方式,就是String的concat方法,其實這種方式拼接字串也不是很好,具體原因看一下concat方法的實現:
public String concat(String str) { int otherLen = str.length(); if (otherLen == 0) { return this; } int len = value.length; char buf[] = Arrays.copyOf(value, len + otherLen); str.getChars(buf, len); return new String(buf, true); }
意思就是通過兩次字串的拷貝,產生一個新的字元陣列buf[],再根據字元陣列buf[],new一個新的String物件出來,這意味著concat方法呼叫N次,將發生N*2次陣列拷貝以及new出N個String物件,無論對於時間還是空間都是一種浪費。
根據上面的解讀,由於"+"拼接字串與String的concat方法拼接字串的低效,我們才需要使用StringBuilder和StringBuffer來拼接字串。以StringBuilder為例:
1 public class TestMain 2 { 3 public static void main(String[] args) 4 { 5 StringBuilder sb = new StringBuilder("111"); 6 sb.append("222"); 7 sb.append("111"); 8 sb.append("111"); 9 sb.append("444"); 10 System.out.println(sb.toString()); 11 } 12 }
StringBuffer和StringBuilder原理一樣,無非是在底層維護了一個char陣列,每次append的時候就往char陣列裡面放字元而已,在最終sb.toString()的時候,用一個new String()方法把char陣列裡面的內容都轉成String,這樣,整個過程中只產生了一個StringBuilder物件與一個String物件,非常節省空間。StringBuilder唯一的效能損耗點在於char陣列不夠的時候需要進行擴容,擴容需要進行陣列拷貝,一定程度上降低了效率。
StringBuffer和StringBuilder用法一模一樣,唯一的區別只是StringBuffer是執行緒安全的,它對所有方法都做了同步,StringBuilder是執行緒非安全的,所以在不涉及執行緒安全的場景,比如方法內部,儘量使用StringBuilder,避免同步帶來的消耗。
另外,StringBuffer和StringBuilder還有一個優化點,上面說了,擴容的時候有效能上的損耗,那麼如果可以估計到要拼接的字串的長度的話,儘量利用建構函式指定他們的長度。
真的不能用"+"拼接字串?
雖然說不要用"+"拼接字串,因為會產生大量的無用StringBuilder物件,但也不是不可以,比如可以使用以下的方式:
1 public class TestMain 2 { 3 public static void main(String[] args) 4 { 5 String str = "111" + "222" + "333" + "444"; 6 System.out.println(str); 7 } 8 }
就這種連續+的情況,實際上編譯的時候JVM會只產生一個StringBuilder並連續append等號後面的字串。
不過上面的例子要注意一點,因為"111"、"222"、"333"、"444"都是編譯期間即可得知的常量,因為第5行的程式碼JVM在編譯的時候並不會生成一個StringBuilder而是直接生成字串"111222333444"。
但是這麼寫得很少,主要原因有兩點:
1、例子比較簡單,但實際上大量的“+”會導致程式碼的可讀性非常差
2、待拼接的內容可能從各種地方獲取,比如呼叫介面、從.properties檔案中、從.xml檔案中,這樣的場景下儘管用多個“+”的方式也不是不可以,但會讓程式碼維護性不太好