閱讀目錄:
- 1.開篇介紹
- 2.NET平行計算基本介紹
- 3.並行迴圈使用模式
- 3.1並行For迴圈
- 3.2並行ForEach迴圈
- 3.3並行LINQ(PLINQ)
1】開篇介紹
最近這幾天在搗鼓平行計算,發現還是有很多值得分享的意義,因為我們現在很多人對它的理解還是有點不準確,包括我自己也是這麼覺得,所以整理一些文章分享給在使用.NET平行計算的朋友和將要使用.NET平行計算的朋友;
NET並行程式設計推出已經有一段時間了,在一些專案程式碼裡也時不時會看見一些眼熟的平行計算程式碼,作為熱愛技術的我們怎能視而不見呢,於是搗鼓了一番跟自己的理解恰恰相反,看似一段能提高處理速度的並行程式碼為能起效果,跟直接使用手動建立的後臺執行緒處理差不多,這不太符合我們對.NET並行的強大技術的理解,所以自己搞了點資料看看,實踐了一下,發現在使用.NET並行技術的時候需要注意一些細節,這些細節看程式碼是看不出來的,所以我們看到別人這麼用我們就模仿這麼用,我們需要自己去驗證一下到底能提高多少處理速度和它的優勢在哪裡;要不然效率上不去反而還低下,檢視程式碼也不能很好的斷定哪裡出了問題,所以還是需要系統的學習總結才行;
現在的系統已經不在是以前桌面程式了,也不是簡單的WEB應用系統,而是大型的網際網路社群、電子商務等大型系統,具有高併發,大資料、SOA這些相關特性的複雜體系的綜合性開放平臺;.NET作為市場佔有率這麼高的開發技術,有了一個很強大的並行處理技術,目的就是為了能在高併發的情況下提高處理效率,提高了單個併發的處理效率也就提高了總體的系統的吞吐量和併發數量,在單位時間內處理的資料量將提高不是一個係數兩個係數;一個處理我們提高了兩倍到三倍的時間,那麼在併發1000萬的頂峰時時不時很客觀;
2】.NET平行計算基本介紹
既然是.NET平行計算,那麼我們首先要弄清楚什麼叫平行計算,與我們以前手動建立多執行緒的平行計算有何不同,好處在哪裡;我們先來了解一下什麼是平行計算,其實簡單形容就是將一個大的任務分解成多個小任務,然後讓這些小任務同時的進行處理,當然純屬自己個人理解,當然不是很全面,但是我們使用者來說足夠了;
在以前單個CPU的情況下只能靠提高CPU的時脈頻率,但是畢竟是有極限的,所以現在基本上是多核CPU,個人筆記本都已經基本上是4核了,伺服器的話都快上20了;在這樣一個有利的計算環境下,我們的程式在處理一個大的任務時為了提高處理速度需要手動的將它分解然後建立Thread來處理,在.NET中我們一般都會自己建立Thread來處理單個子任務,這大家都不陌生,但是我們面臨的問題就是不能很好的把握建立Thread的個數和一些引數的控制,畢竟.NET並行也是基於以前的Thread來寫的,如何在多執行緒之間控制引數,如何互斥的執行的執行緒順序等等問題,導致我們不能很好的使用Thread,所以這個時候.NET並行框架為我們提供了一個很好的並行開發平臺,畢竟大環境就是多核時代;
下面我們將接觸.NET平行計算中的第一個使用模式,有很多平行計算場景,歸結起來是一系列使用模式;
3】並行迴圈模式
並行迴圈模式就是將一個大的迴圈任務分解成多個同時並行執行的小迴圈,這個模式很實用;我們大部分處理程式的邏輯都是在迴圈和判斷之間,並行迴圈模式可以適當的改善我們在操作大量迴圈邏輯的效率;
我們看一個簡單的例子,看到底提升了多少CPU利用率和執行時間;


1 using System; 2 using System.Collections.Generic; 3 using System.Threading.Tasks; 4 using System.Diagnostics; 5 6 namespace ConsoleApplication1.Data 7 { 8 public class DataOperation 9 { 10 private static List<Order> orders = new List<Order>(); 11 12 static DataOperation() 13 { 14 for (int i = 0; i < 9000000; i++) 15 { 16 orders.Add(new Order() { Oid = Guid.NewGuid().ToString(), OName = "OrderName_" + i.ToString() }); 17 } 18 } 19 20 public void Operation() 21 { 22 Console.WriteLine("Please write start keys:"); 23 Console.ReadLine(); 24 25 Stopwatch watch = new Stopwatch(); 26 watch.Start(); 27 orders.ForEach(order => 28 { 29 order.IsSubmit = true; 30 int count = 0; 31 for (int i = 0; i < 2000; i++) 32 { 33 count++; 34 } 35 }); 36 watch.Stop(); 37 Console.WriteLine(watch.ElapsedMilliseconds); 38 } 39 40 public void TaskOperation() 41 { 42 Console.WriteLine("Please write start keys:"); 43 Console.ReadLine(); 44 45 Stopwatch watch = new Stopwatch(); 46 watch.Start(); 47 Parallel.ForEach(orders, order => 48 { 49 order.IsSubmit = true; 50 int count = 0; 51 for (int i = 0; i < 2000; i++) 52 { 53 count++; 54 } 55 }); 56 watch.Stop(); 57 Console.WriteLine(watch.ElapsedMilliseconds); 58 } 59 } 60 }
這裡的程式碼其實很簡單,在靜態建構函式中我初始化了九百萬條測試資料,其實就是Order型別的例項,這在我們實際應用中也很常見,只不過不是一次性的讀取這麼多資料而已,但是處理的方式基本上差不多的;然後有兩個方法,一個是Operation,一個是TaskOperation,前者順序執行,後者並行執行;
在迴圈的內部我加上了一個2000的簡單空迴圈邏輯,為什麼要這麼做後面會解釋介紹(小迴圈並行模式不會提升效能反而會降低效能);這裡是為了讓模擬場景更真實一點;
我們來看一下測試相關的資料:i5、4核測試環境,執行時間為42449毫秒,CPU使用率為25%左右,4核中只使用了1和3的,而其他的都屬於一般處理狀態;
圖1:

我們再來看一下使用平行計算後的相關資料:i5、4核測試環境,執行時間為19927毫秒,CPU利用率為100%,4核中全部到達頂峰;
圖2:
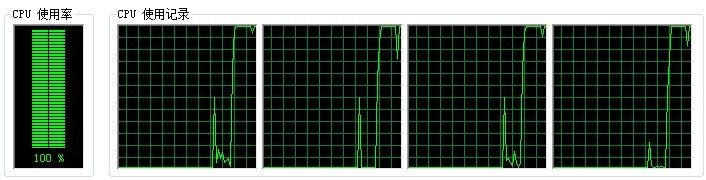
這一個簡單的測試例子,當然我只測試了兩三組資料,基本上平行計算的速度要快於單執行緒的處理速度的2.1倍以上,當然還有其他因素在裡面這裡就不仔細分析了,起到拋磚引玉的作用;
3.1】並行For迴圈
在使用for迴圈的時候有相應的Parallel方式使用for迴圈,我們直接看一下示例程式碼,還是以上面的測試資料為例;
1 Parallel.For(0, orders.Count, index => 2 { 3 // 4 });
第一個引數是索引的開始,第二個引數是迴圈總數,第三個是執行體,引數是索引值;使用起來其實很簡單的;
3.2】並行ForEach迴圈
同樣ForEach也是很簡單的,還是使用上面的測試資料為例;
1 Parallel.ForEach(orders, order => 2 { 3 order.IsSubmit = true; 4 int count = 0; 5 for (int i = 0; i < 2000; i++) 6 { 7 count++; 8 } 9 });
在Parallel類中有ForEach方法,第一個引數是迭代集合,第二個是每次迭代的item;
其實Parallel為我們封裝了一個簡單的呼叫入口,其實是依附於後臺的Task框架的,因為我們常用的就是迴圈比較多,畢竟迴圈是任務的入口呼叫,所以我們使用並行迴圈的時候還是很方便的;
3.3】並行LINQ(PLINQ)
首先PLINQ是隻針對Linq to Object的,所以不要誤以為它也可以使用於Linq to Provider,當然自己可以適當的封裝;現在LINQ的使用率已經很高了,我們在做物件相關的操作時基本上都在使用LINQ,很方便,特別是Select、Where非常的常用,所以.NET並行迴圈也在LINQ上進行了一個封裝,讓我們使用LINQ的時候很簡單的使用並行特性;
LINQ核心原理的文章:http://www.cnblogs.com/wangiqngpei557/category/421145.html
根據LINQ的相關原理,知道LINQ是一堆擴充套件方法的鏈式呼叫,PLINQ就是擴充套件方法的集合,位於System.Linq.ParallelEnumerable靜態類中,擴充套件於ParallelQuery<TSource>泛型類;
System.Linq.ParallelQuery<TSource>:
1 using System.Collections; 2 using System.Collections.Generic; 3 4 namespace System.Linq 5 { 6 // 摘要: 7 // 表示並行序列。 8 // 9 // 型別引數: 10 // TSource: 11 // 源序列中的元素的型別。 12 public class ParallelQuery<TSource> : ParallelQuery, IEnumerable<TSource>, IEnumerable 13 { 14 // 摘要: 15 // 返回迴圈訪問序列的列舉數。 16 // 17 // 返回結果: 18 // 迴圈訪問序列的列舉數。 19 public virtual IEnumerator<TSource> GetEnumerator(); 20 } 21 }
System.Linq.ParallelEnumerable:
1 // 摘要: 2 // 提供一組用於查詢實現 ParallelQuery{TSource} 的物件的方法。 這是 System.Linq.Enumerable 的並行等效項。 3 public static class ParallelEnumerable {}
我們在用的時候只需要將它原本的型別轉換成ParallelQuery<TSource>型別就行了;
1 var items = from item in orders.AsParallel() where item.OName.Contains("1") select item;
Linq 的擴充套件性真的很方便,可以隨意的封裝任何跟查詢相關的介面;
作者:王清培
出處:http://www.cnblogs.com/wangiqngpei557/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。