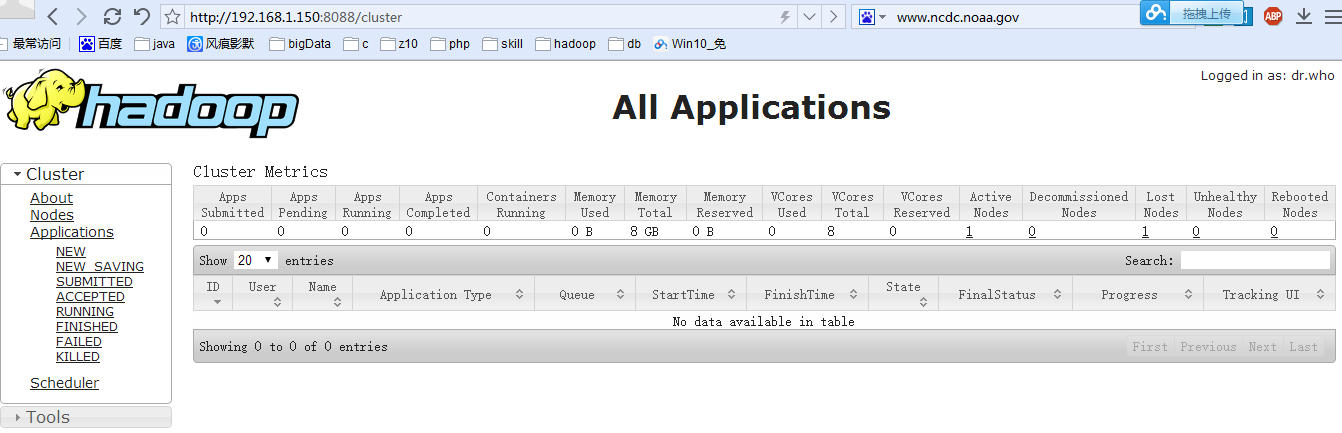
在經過幾天的環境搭建,終於搭建成功,其中對於hadoop的具體設定倒是沒有碰到很多問題,反而在hadoop各節點之間的通訊遇到了問題,而且還反覆了很多遍,光虛擬機器就重新安裝了4、5次,但是當明白了問題之後才發現這都是無用功,有了問題應該找具體的解決方案,並不是完全的重灌,這樣不會明白問題是怎麼解決的,除了費時費力沒有多大的用處,接下來就把搭建的過程詳細敘述一下。
環境配置:
計算機:
CPU-I7 2630QM
6G記憶體
256G SSD
虛擬機器:
vmware workstation 11
系統:
ubuntu 14.04 LTS
節點:
192.168.1.150 master
192.168.1.151 slave1
192.168.1.151 slave2
參考:
http://www.aboutyun.com/thread-7684-1-1.html
http://my.oschina.net/u/2285247/blog/354449
http://www.aboutyun.com/thread-5738-1-1.html
http://www.aboutyun.com/thread-6446-1-1.html
安裝步驟:
1、安裝虛擬機器系統(安裝1個即可,其餘的可以通過克隆),並進行準備工作
2、安裝JDK,並配置環境變數
3、克隆虛擬機器系統,並修改hosts、hostname
4、配置虛擬機器網路,使虛擬機器系統之間以及和host主機之間可以通過相互ping通。
5、配置ssh,實現節點間的無密碼登入
6、master配置hadoop,並將hadoop檔案傳輸到slave節點
7、配置環境變數,並啟動hadoop,檢查是否安裝成功
1、安裝虛擬機器系統,並進行準備工作
安裝虛擬機器系統不用贅述,安裝vmware——新建虛擬機器——典型——選擇映象——設定賬戶密碼——安裝位置——配置——安裝。
當虛擬機器安裝成功後,預設的是nat模式,不要立即將網路模式切換到橋接模式下,這時nat模式下應該可以聯網,先安裝幾個軟體,以後需要用到,當然在橋接模式下也可以聯網,但是橋接模式是要設定成靜態IP的,侷限性比較大,下載安裝完以後,接下來就不用聯網了。
#切換到root模式下
#剛開始root是預設不開啟的,可以利用如下命令對root密碼進行設定
sudo passwd root
#現在在root模式先安裝vim,命令如下:
apt-get install vim
#安裝ssh
apt-get install ssh
#這個步驟是可選的,用於更新,以及將ssh相關都安裝
apt-get install openssh*
apt-get update
2、安裝jdk,並配置環境變數
1)從oracle下載jdk安裝包,並將安裝包拖入到虛擬機器當中
2)通過cd命令進入到安裝包的當前目錄,利用如下命令進行解壓縮。
tar -zxvf jdk.....(安裝包名稱)
3)利用如下命令將解壓後的資料夾移到/usr目錄下
#注意,這樣移動到/usr以後就沒有jdk1.8...這個目錄了,是將這個目錄下的所有檔案全部移動到/usr/java下,
mv jdk1.8...(資料夾名稱) /usr/java
4)配置環境變數
#切換到root模式下
su - root
#利用vim編輯/etc/profile(這個是對全體使用者都起作用的)
vim /etc/profile
#將一下兩句加入到其中,並儲存退出
export PATH=$PATH:/usr/java/bin:/usr/java/jre/bin
export CLASSPATH=.:/usr/java/lib:/usr/java/jre/lib
#然後使profile生效
source /etc/profile
#試驗java、javac、java -version
3、克隆虛擬機器並修改三個虛擬機器的hosts、hostname
1)克隆虛擬機器時要注意一定要選擇完整克隆
2)修改hosts(三個虛擬機器都要改)
#root下用vim開啟hosts
vim /etc/hosts
#將以下內容新增到hosts中
192.168.1.150 master
192.168.1.151 slave1
192.168.1.152 slave2
如圖:
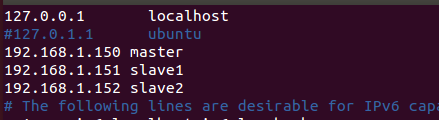
3)修改hostname(三個虛擬機器都要改)
#root下開啟hostname
vim /etc/hostname
#分別將每個虛擬機器改成對應的name(master、slave1、slave2)
4、配置虛擬機器網路
在安裝好虛擬機器後,虛擬機器有三種模式分別是nat模式、僅主機模式、橋接模式,此處對於此三種模式進行簡單介紹:
nat模式:這是通nat地址轉換共享主機Ip的模式,在安裝好虛擬機器後會發現有vmnet8虛擬網路卡,這個網路卡預設是nat模式,這時nat模式下的虛擬機器相當於又組成一個區域網,而vmnet8相當於這個區域網的閘道器,在這種模式下,虛擬機器之間可以相互ping通,但是不能與主機通訊,因為主機與虛擬機器之間有有一個vmnet8網路卡。當然通過配置vmnet8網路卡可以實現通訊。
僅主機模式:這種模式沒有地址轉換能力,各個虛擬機器之間是相互獨立的,不能相互訪問,每個虛擬機器只能與主機通訊。
橋接模式:這種模式是將虛擬網路卡直接繫結到物理網路卡上,可以繫結多個地址,這裡是將網路卡設定成混雜模式,然後實現可以收發多個地址的訊息。
本人搭建環境採用的是橋接模式,這種模式擬真性更強一些,雖然有些麻煩。
注意:要將三個虛擬機器的ip與主機都處於同一個網段,然後實驗是否可以Ping通
5、配置ssh,實現節點間的無密碼登入 (注意關閉防火牆 ufw disable)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2)匯入authorized_keys
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3)試驗看是否安裝成功
#檢視是否有sshd程式
ps -e | grep ssh
#嘗試登入本地
ssh localhost
4)遠端無密碼登入
#進入master的.ssh目錄
scp authorized_keys u0@slave1:~/.ssh/authorized_keys_master
#u0是我的使用者名稱
#進入slave1、slave2的.ssh目錄
cat authorized_keys_master >> authorized_keys
注意:第四步要在slave上重複,要使三者都能夠無密碼相互登入,重複完後可以利用如下命令試驗,第一次需要輸入密碼繫結
ssh salve1(slave2)
注意:我的主機是連線的路由無線網路,我遇到了一個問題,就是在虛擬機器網路重連後master可以登入slave2,但是過一會後就發現老是connection refused,就因為這個問題我還重新安裝了幾次,網路上的方法都試了也不管用,後來發現,原來是我的虛擬機器ip與路由區域網中的其他機器Ip衝突,千萬要保證區域網內的Ip不要和虛擬機器的ip衝突
6、master配置hadoop,並將hadoop檔案傳輸到slave節點
1)解包移動
#解壓hadoop包
tar -zxvf hadoop...
#將安裝包移到/usr目錄下
mv hadoop... /usr/hadoop
2)新建資料夾
#在/usr/hadoop目錄下新建如下目錄(root)
mkdir /dfs
mkdir /dfs/name
mkdir /dfs/data
mkdir /tmp
3)配置檔案:hadoop-env.sh(檔案都在/usr/hadoop/etc/hadoop中)
修改JAVA_HOME值(export JAVA_HOME=/usr/java)
5)配置檔案:slaves
將內容修改為:
slave1
slave2
6)配置檔案:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.u0.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.u0.groups</name>
<value>*</value>
</property>
</configuration>
7)配置檔案:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
8)配置檔案:mapred-site.xml
<configuration> <property>
<name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
9)配置檔案:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
10)將hadoop傳輸到slave1和slave2根目錄
scp -r /usr/hadoop u0@slave1:~/
7、配置環境變數,並啟動hadoop,檢查是否安裝成功
1)配置環境變數
#root模式編輯/etc/profile
vim /etc/profile
#以上已經新增過java的環境變數,在後邊新增就可以
export PATH=$PATH:/usr/java/bin:/usr/java/jre/bin:/usr/hadoop/bin:/usr/hadoop/sbin
2)啟動hadoop
#注意最後單詞帶‘-’
hadoop namenode -format
start-all.sh
3)檢視啟動程式