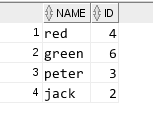
create table test1( id number, name varchar2(20) );
insert into test1 values(1,'jack'); insert into test1 values(2,'jack'); insert into test1 values(3,'peter'); insert into test1 values(4,'red');
insert into test1 values(5,'green');
insert into test1 values(6,'green');
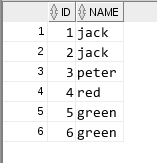
一 查詢表中重複資料
1. 使用exists
1 select a.* from test1 a 2 3 where exists 4 5 ( 6 select name from 7 ( select name ,count(*) 8 from test1 9 group by name 10 having count(*)>1 11 ) b 12 where a.name = b.name 13 );

2 join on
select a. * from test1 a join ( select name ,count(*) from test1 group by name having count(*)>1 ) b on a.name = b.name;
3 in
select a.name from test1 a where a.name in ( select name from test1 group by name having count(*)>1 );
4 使用rowid 查詢得到重複記錄裡,第一條插入記錄後面的記錄
select * from test1 a where rowid != (select min(rowid) from test1 b where b.name = a.name);
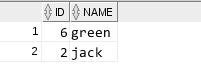
5 使用rowid查詢得到重複記錄裡,最後一條記錄之前插入的記錄
select a.* from test1 a where rowid !=(select max(rowid) from test1 b where a.name=b.name);

6 使用rowid 查詢得到 不重複的記錄和重複記錄裡最後插入的一條記錄
select a.* from test1 a where rowid =(select max(rowid) from test1 b where a.name=b.name);
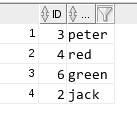
7 使用rowid 查詢得到不重複的記錄和重複記錄裡最先插入的記錄
select * from test1 a where rowid = (select min(rowid) from test1 b where b.name = a.name);
刪除 所有重複不保留任何一條
delete from test1 a where exists ( select name from (select name ,count(*) from test1 group by name having count(*)>1) b where a.name = b.name);
delete from test1 a where a.name in (select name from test1 group by name having count(*)>1);
刪除重複記錄裡,第一條重複記錄後面插入的記錄
delete from test1 a where rowid !=(select min(rowid) from test1 b where b.name = a.name);

刪除先前插入的重複記錄,保留最後插入的重複記錄
delete from test1 a where rowid !=(select max(rowid) from test1 b where a.name=b.name);