標籤:SQL SERVER/MSSQL SERVER/資料庫/DBA/查詢步驟
概述
查詢步驟是很基礎也挺重要的一部分,但是我還是在周圍發現有些人雖然會語法,但是對於其中的步驟不是很清楚,這裡就來分解一下其中的步驟,在技術內幕系列裡面都會有講到。
目錄
流程圖
(1)FROM <LEFT_TABLE> <JOIN_TYPE> JOIN <RIGHT_TABLE> ON <ON_PREDICATE> |<LEFT_TABLE> <APPLY_TYPE> APPLY <RIGHT_TABLE_EXPRESSION> AS <alias> |<LEFT_TABLE> pivot(<pivot_specification>) AS <alias> |<LEFT_TABLE> UNPIVOT(<unpivot_specification>) AS <alias> (2)WHERE<where_predicate> (3)GROUP BY<group_by_specification> (4)HAVING<having_predicate> (5)SELECT <DISTINCT> <TOP> <select_list> (6)ORDER BY<order_by_list>
步驟分解
測試資料
--建立測試表 --建立顧客表 CREATE TABLE Customers (custid INT NOT NULL PRIMARY KEY, city NVARCHAR(20) NOT NULL ) go INSERT INTO Customers VALUES(1,'深圳'),(2,'廣州'),(3,'武漢'),(4,'上海'),(5,'北京') --建立訂單表 CREATE TABLE Orders (orderid INT NOT NULL PRIMARY KEY IDENTITY(1000,1), custid INT NOT NULL, orderdate DATETIME NOT NULL ) GO INSERT INTO Orders(custid,orderdate)values(1,'2013-10-1 00:00:00'),(1,'2013-10-2 00:00:00'),(1,'2013-10-3 00:00:00'),(1,'2013-10-4 00:00:00'),(2,'2013-10-1 00:00:00'),(2,'2013-10-3 00:00:00'),(2,'2013-10-5 00:00:00'),(3,'2013-10-3 00:00:00'),(3,'2013-10-7 00:00:00'),(4,'2013-10-1 00:00:00') --建立訂單明細表 CREATE TABLE [OrderDetails]( [orderid] [int] NOT NULL, [productid] [int] NOT NULL, [unitprice] [money] NOT NULL, [qty] [smallint] NOT NULL CONSTRAINT [PK_OrderDetails] PRIMARY KEY CLUSTERED ( [orderid] ASC, [productid] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO INSERT INTO OrderDetails VALUES(1000,10,5.00,1),(1000,14,6.00,2),(1001,10,5.31,3),(1001,11,5.22,1),(1001,12,3.20,3),(1001,13,4.10,2),(1002,11,7.00,1),(1003,12,8.00,5),(1004,13,8.41,1),(1004,11,6.65,1),(1005,18,7.41,1),(1006,17,10.00,1)
--查詢深圳、廣州每一個顧客每筆金額大於10的訂單,並按訂單價格倒序排序 SELECT TA.custid,TB.orderid,SUM(tc.unitprice*tc.qty) AS price FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid LEFT JOIN OrderDetails TC ON TB.orderid=tc.orderid WHERE TA.city IN('深圳','廣州') GROUP BY TA.custid,TB.orderid HAVING SUM(tc.unitprice*tc.qty)>10 ORDER BY price DESC
第一步:FROM階段
這一步是一個T-SQL語句的開始,一般緊接著FROM的這個表被稱作左表,例如a inner join b inner join c,首先a作為左表然後關聯b,a和b關聯的結果作為下一個運算的左表關聯c。在FROM階段涉及的表運算會有JOIN(LEFT JOIN,RIGHT JOIN,FULL JOIN),APPLY(CROSS APPLY,OUTER APPLY),PIVOT,UNPIVOT
對於上面的查詢例子:FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid的左連線的分解是這樣的
第一步交叉連線、SELECT * FROM Customers TA CROSS JOIN Orders TB---首先進行交叉連線得到的行數是5*10=50行
第二步ON篩選、將TA.custid=TB.custid以外的結果排除,可以等價於SELECT * FROM Customers TA CROSS JOIN Orders TB WHERE TA.custid=TB.custid
第三步、將主表(左邊的表)不在第二步的行加上,可以等價於 SELECT * FROM Customers TA CROSS JOIN Orders TB WHERE TA.custid=TB.custid union all SELECT * FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid WHERE TB.custid IS NULL
所以其它幾個表運算只要大家知道怎麼使用就可以了,大家只要明白它在T-SQL語句中的位置就行。
這裡要注意一點:大家理解了JEFT JOIN的原理之後就明白"on"篩選對查詢的刪除不是最終的,在上面的第三步會把主表的一些行又新增上來,所以我們有時候寫LEFT JOIN的時候有的人不太明白為什麼ON 後面加AND和把AND放在WHERE裡面的得到的結果不一樣,就是這個原理了,WHERE操作對查詢的刪除才是最終的。
第二步:WHERE階段
當然後面的有些階段都是可選的也就是有的查詢不一定會用到,但是這裡為了講述整個過程,所以就一步一步的來講,在FROM 階段結束之後會生成一張虛擬表,進入第二階段也就是WHERE階段,在WHERE階段是對前一階段(FROM階段)結果返回行進行篩選,例如上面的查詢篩選城市是‘深圳’,‘廣州’的顧客
所以為什麼把select步驟裡面生成的列寫在where裡面無法識別就是因為where在select操作之前。
第三步:GROUP BY階段
GROUP BY 操作是分組操作,確保進行分組的屬性集每一個組都是唯一的,GROUP BY 操作的資料是WHERE階段篩選之後的資料,例如上面的查詢例子是將custid,orderid作為一行來進行分組,上面的例子是每一個顧客每一筆訂單的消費金額。
第四步:HAVING階段
HAVING階段是在GOUP BY 階段返回TURE之後才會有這步操作,HAVING是對上一步的分組之後的資料進行篩選的步驟,例如篩選消費訂單金額大於10的顧客訂單
第五步:SELECT階段
select階段是返回上一步操作得到的虛擬表的資料列,所以也就是為什麼存在group by的分組查詢,select裡面的列跟group by 的分組列需要一致的原因了,聚會函式生成的列除外,因為select查詢的基礎列就是來源於前面的步驟,select階段會涉及到去重複distinct當然如果前面存在分組也就不存在重複了,TOP操作,還有一些欄位之間的演算法運算,子查詢等等。
第六步:ORDER BY階段
這一步是整個過程的最後一步操作,因為它在SELECT階段之後,所以對於SELECT裡面生成的欄位別名在ORDER BY 中可以使用別名,對於一張表,表代表的是集合,集合是沒有順序的,當一個查詢帶有ORDER BY時我們可以把它理解成遊標,遊標是有特定的排序,所以為什麼一個查詢加上ORDER BY 操作之後會變的很慢了,因為它需要進行排序操作。
---當查詢沒有排序時 SELECT * FROM Orders
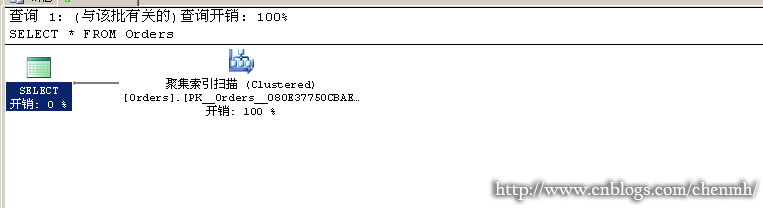
---當查詢有排序時 SELECT * FROM Orders ORDER BY CUSTID
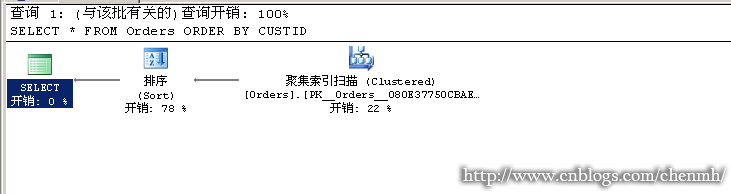
TOP於ORDER BY的關係
order by 是保證結果排序順序,top是一個邏輯運算操作
對於一個沒有外部查詢的語句,order by 操作既能保證結果根據制定條件的排序,又能滿足TOP的邏輯運算(查詢最小的三個orderid) SELECT TOP (3) * FROM Orders ORDER BY ORDERID
對於存在外部查詢時,order by在作用僅僅是保證top的邏輯結果的正確輸出,而不能保證查詢結果的排序,雖然我們可能查詢出的結果是按照這個方式排序。 ---當不指定TOP時報錯 SELECT * FROM(SELECT custid,orderid,orderdate FROM Orders ORDER BY orderdate DESC) AS A ---當指定 SELECT * FROM(SELECT TOP (3) custid,orderid,orderdate FROM Orders ORDER BY orderdate DESC) AS A
總結
理解完了整個查詢的過程,也就能能理解為什麼SQLServer這麼耗記憶體了,每一步的操作都是生成一張虛擬表進入下一步操作,理解了整個查詢過程 之後對我們理解T-SQL語法很有幫助,同時也有利於分析語句。
如果文章對大家有幫助,希望大家能給個贊,謝謝!!!
|
備註: 作者:pursuer.chen 部落格:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結,否則保留追究責任的權利。 《歡迎交流討論》 |