介紹
本篇文章主要介紹在插入資料到表中遇到鍵重複避免插入重複值的處理方法,主要涉及到IGNORE,ON DUPLICATE KEY UPDATE,REPLACE;接下來就分別看看這三種方式的處理辦法。
IGNORE
使用ignore當插入的值遇到主鍵(PRIMARY KEY)或者唯一鍵(UNIQUE KEY)重複時自動忽略重複的記錄行,不影響後面的記錄行的插入,
建立測試表
CREATE TABLE Tignore (ID INT NOT NULL PRIMARY KEY , NAME1 INT )default charset=utf8;

正常的插入如果插入的記錄中存在鍵重複會報錯,整個語句都會執行失敗

使用IGNORE如果插入的記錄中存在重複值會忽略重複值的該記錄行,不影響其它行的插入。
REPLACE
使用replace當插入的記錄遇到主鍵或者唯一鍵重複時先刪除表中重複的記錄行再插入。
REPLACE INTO Treplace() VALUES(1,1),(1,2),(2,2);
建立測試表
DROP TABLE IF EXISTS Treplace; CREATE TABLE Treplace (ID INT NOT NULL PRIMARY KEY , NAME1 INT )default charset=utf8;
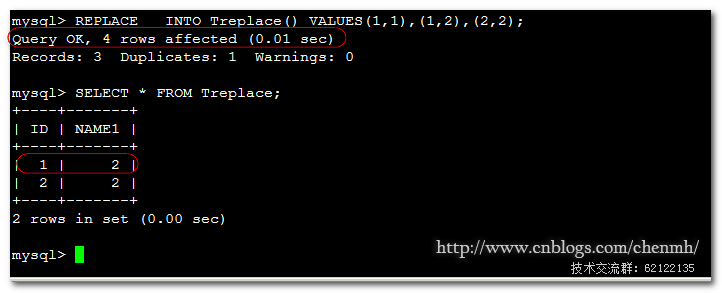
從輸出的資訊可以看到是4行受影響,說明它是先插入了(1,1)然後又刪除了(1,1)
ON DUPLICATE KEY UPDATE
當插入的記錄遇到主鍵或者唯一鍵重複時,會執行後面定義的UPDATE操作。
相當於先執行Insert 操作,再根據主鍵或者唯一鍵執行update操作。
建立測試表
DROP TABLE IF EXISTS Tupdate; CREATE TABLE Tupdate (ID INT NOT NULL PRIMARY KEY , NAME1 INT UNIQUE KEY )default charset=utf8;
INSERT INTO Tupdate() VALUES(1,1),(1,2) ON DUPLICATE KEY UPDATE NAME1=NAME1+1; INSERT INTO Tupdate() VALUES(1,1),(1,2) ON DUPLICATE KEY UPDATE NAME1=VALUES(NAME1)+1;
第一條語句相當於執行:
INSERT INTO Tupdate() VALUES(1,1) UPDATE Tupdate SET NAME1=NAME1+1 WHERE ID=1;
第二條語句相當於執行:
INSERT INTO Tupdate() VALUES(1,1) UPDATE Tupdate SET NAME1=2+1 WHERE ID=1;
在ON DUPLICATE KEY UPDATE後面使用VALUES指的就是插入的記錄的值,而不使用VALUES指的是表的自身值。
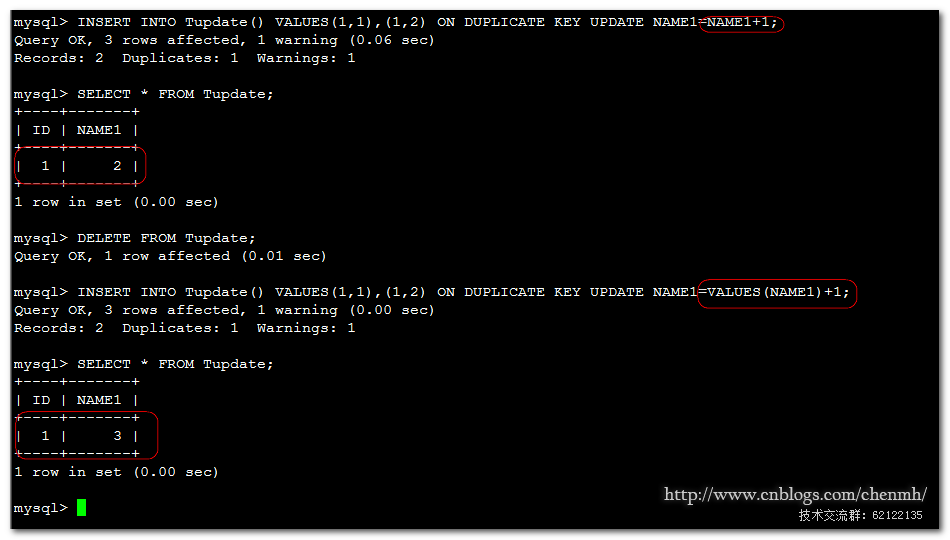
注意: ON DUPLICATE KEY UPDATE的後面執行的UPDATE更新的記錄是WHERE重複的主鍵或者唯一鍵的ID,這點非常重要。
比如下面這種情況:
INSERT INTO Tupdate() VALUES(1,1),(2,1) ON DUPLICATE KEY UPDATE NAME1=VALUES(ID)+1;
它是唯一鍵NAME1重複但是主鍵不重複,執行的語句是這樣的:
INSERT INTO Tupdate() VALUES(1,1) UPDATE Tupdate SET NAME1=2+1 WHERE ID=1;
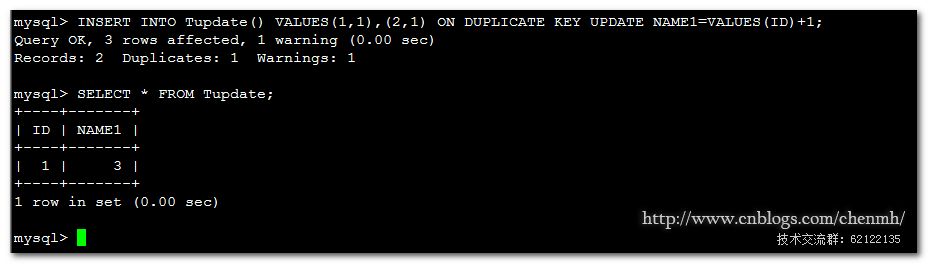
不要認為會插入主鍵ID=2的記錄進去。
總結
上面的三種處理重複值的方法都支援標準的INSERT語法,包括INSERT INTO...VALUES, INSERT INTO ....SET ,INSERT INTO..... SELECT。
|
備註: 作者:pursuer.chen 部落格:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結。 《歡迎交流討論》 |