標籤:SQL SERVER/MSSQL SERVER/資料庫/DBA/表分割槽
概述
在很多業務場景下我們需要對一些記錄量比較大的表進行分割槽,同時為了保證效能需要將一些舊的資料進行歸檔。在分割槽表很多的情況下如果每一次歸檔都需要人工干預的話工程量是比較大的而且也容易發生紕漏。接下來分享一個自己編寫的自動歸檔分割槽資料的指令碼,原理是分割槽表和歸檔表使用相同的分割槽方案,迴圈利用當前的檔案組。
一、建立測試資料
----01建立檔案組 USE [master] GO ALTER DATABASE [chenmh] ADD FILEGROUP [Group1] GO ALTER DATABASE [chenmh] ADD FILEGROUP [Group2] GO ALTER DATABASE [chenmh] ADD FILEGROUP [Group3] GO ALTER DATABASE [chenmh] ADD FILEGROUP [Group4] GO USE [master] GO ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile1', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile1.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group1] GO ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile2', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile2.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group2] GO ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile3', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile3.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group3] GO ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile4', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile4.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group4] GO ----02建立分割槽函式 USE [chenmh] GO CREATE PARTITION FUNCTION [Pt_Range](BIGINT) AS RANGE RIGHT FOR VALUES (1000000, 2000000, 3000000) GO ----03建立分割槽方案,分割槽方案對應的檔案組數是分割槽函式指定的數量+1 CREATE PARTITION SCHEME Ps_Range AS PARTITION Pt_Range TO (Group1, Group2, Group3, Group4); ---04建立表,指定的分割槽列的資料型別一定要和分割槽函式指定的列型別一致。 CREATE TABLE [dbo].[News]( [id] [bigint] NOT NULL, [status] [int] NULL, CONSTRAINT [PK_News] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Ps_Range](id) ) ON [Ps_Range](id) -----建立歸檔分割槽表 CREATE TABLE [dbo].[NewsArchived]( [id] [bigint] NOT NULL, [status] [int] NULL, CONSTRAINT [PK_NewsArchived] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Ps_Range](id) ) ON [Ps_Range](id) ----插入測試資料 DECLARE @id INT SET @id=1 WHILE @id<5001000 BEGIN INSERT INTO News VALUES(@id,@id%2) SET @id=@id+1 END

可以看到當前總共有4個分割槽,每一個分割槽定義的範圍區間是100萬,分割槽4我故意多插入了200多萬的資料來驗證自動歸檔分割槽。
二、自動歸檔分割槽指令碼
CREATE PROCEDURE Pro_Partition_AutoArchiveData (@PartitionTable VARCHAR(300), @SwitchTable VARCHAR(300) ) AS BEGIN DECLARE @FunName VARCHAR(100),@SchemaName VARCHAR(100),@MaxPartitionValue sql_variant ---根據歸檔表查詢對應的分割槽方案、分割槽函式、最小分割槽數、最大分割槽範圍值 SELECT DISTINCT @FunName=MAX(pf.name), @SchemaName=MAX(ps.name), @MaxPartitionValue=max(isnull(prv.value,0)) FROM sys.partitions p inner join sys.indexes i ON p.object_id=i.object_id and p.index_id=i.index_id inner join sys.partition_schemes ps ON i.data_space_id=ps.data_space_id inner join sys.destination_data_spaces dds ON ps.data_space_id=dds.partition_scheme_id and dds.destination_id=p.partition_number inner join sys.data_spaces ds ON dds.data_space_id=ds.data_space_id inner join sys.partition_functions pf ON ps.function_id=pf.function_id LEFT join sys.partition_range_values prv ON pf.function_id=prv.function_id AND prv.boundary_id=p.partition_number-pf.boundary_value_on_right LEFT join sys.partition_parameters pp ON prv.function_id=pp.function_id and prv.parameter_id=pp.parameter_id LEFT join sys.types t ON pp.system_type_id=t.system_type_id and pp.user_type_id=t.user_type_id WHERE OBJECT_NAME(p.OBJECT_ID)=@PartitionTable DECLARE @MaxId BIGINT,@MinId BIGINT,@Sql NVARCHAR(MAX),@GroupName VARCHAR(100),@MinPartitionNumber INT SET @Sql= N'SELECT @MaxId=MAX(id),@MinId=Min(id) FROM '+@PartitionTable EXEC sp_executesql @Sql,N'@MaxId BIGINT out,@MinId BIGINT out',@MaxId OUT,@MinId OUT SELECT @FunName AS FunName,@SchemaName AS SchemaName,@MaxPartitionValue AS MaxPartitionValue ,@MaxId AS MaxId,@MinId AS MinId ---判斷當前表的最大的id是否已經在最大的分割槽中 IF @MaxId>=@MaxPartitionValue BEGIN ----歸檔分割槽資料,根據表的最小值找到它所屬的分割槽. SET @Sql= N'SELECT @MinPartitionNumber=$PARTITION.'+@FunName+N'('+CONVERT(VARCHAR(30),@MinId)+N')'; EXEC sp_executesql @Sql,N'@MinPartitionNumber INT out',@MinPartitionNumber OUT SET @Sql=N'ALTER TABLE ' +@PartitionTable+ N' SWITCH PARTITION '+CONVERT(VARCHAR(10),@MinPartitionNumber)+ N' TO ' +@SwitchTable+ N' PARTITION ' +CONVERT(VARCHAR(10),@MinPartitionNumber); --PRINT @Sql EXEC (@Sql) ---修改分割槽方案,增加新的分割槽對應的檔案組,根據最小的分割槽id找到對應的檔案組。 SELECT DISTINCT @GroupName=ds.name FROM sys.partitions p inner join sys.indexes i ON p.object_id=i.object_id and p.index_id=i.index_id inner join sys.partition_schemes ps ON i.data_space_id=ps.data_space_id inner join sys.destination_data_spaces dds ON ps.data_space_id=dds.partition_scheme_id and dds.destination_id=p.partition_number inner join sys.data_spaces ds ON dds.data_space_id=ds.data_space_id inner join sys.partition_functions pf ON ps.function_id=pf.function_id WHERE pf.name=@FunName AND ps.name=@SchemaName AND p.partition_number=@MinPartitionNumber SET @Sql=N'ALTER PARTITION SCHEME '+@SchemaName+N' NEXT USED '+@GroupName --PRINT @Sql EXEC (@Sql) ---修改分割槽函式,增加新的分割槽,增加新的分割槽範圍值,在現有的最大的值的基礎上加100萬(需要和現有的分割槽函式的範圍保持一致) SET @MaxPartitionValue=CONVERT(BIGINT,@MaxPartitionValue)+1000000 SET @Sql=N'ALTER PARTITION FUNCTION '+@FunName+N'('+N')'+N' SPLIT RANGE ('+CONVERT(VARCHAR(30),@MaxPartitionValue)+N')' --PRINT @Sql EXEC (@Sql) END END
三、自動歸檔分割槽資料
1.首次測試
EXEC Pro_Partition_AutoArchiveData 'news','NewsArchived';
注意:每呼叫一次歸檔一個最小分割槽的資料。


分割槽表的News分割槽1的資料被歸檔到了NewsArchived表中,且建立了分割槽5,分割槽5使用的是已歸檔的分割槽1的檔案組,達到了迴圈利用檔案組的效果。
2.再呼叫一次歸檔分割槽指令碼
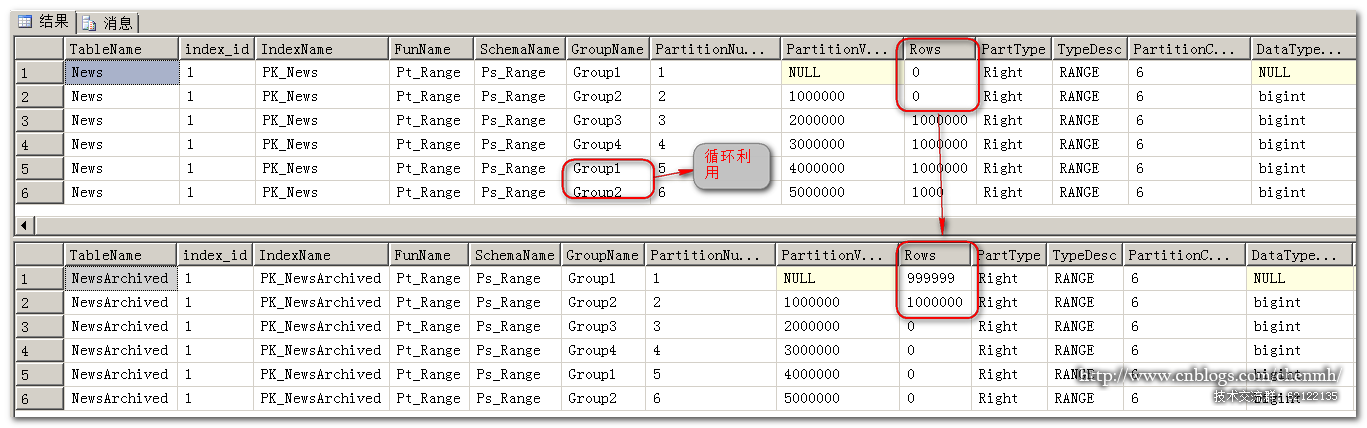
當分割槽表最大的id小於最大的分割槽值時自動歸檔分割槽指令碼就不會生效。所以當前的測試表資料還可以再歸檔分割槽3的資料。
3.經過一段時間的執行歸檔資料可能是這樣的效果

Group1→Group4→Group1→.......
四、指令碼注意事項
1.@PartitionTable和@SwitchTable表必須使用同名的分割槽方案和分割槽函式,否則@SwitchTable就需要單獨修改分割槽方案和函式,且表結構完全一致。
2.歸檔的表分割槽列資料型別必須是INT型別,且值是自增規律.
3.分割槽歸檔作業在備份作業後執行
4.建議使用Right分割槽,Left分割槽會出現有的最後一個分割槽檔案組不會迴圈替換,一直處於分割槽的最後,比如Group1,Group2,Group3,Group1,Group2,Group3,Group1,Group4。期望的應該是Group1,Group2,Group3,Group4,Group1,Group2,Group3,Group4,Group1
5.注意我當前的每個分割槽大小是100萬和分割槽函式保持一致,如果範圍值不同,需要修改最末尾程式碼的"修改分割槽函式"處程式碼.
總結
當前自動歸檔分割槽指令碼如果要拷貝去用還是得能完全理解每一段程式碼,根據自己的業務做適當的修改,畢竟資料是無價的!!!。最後只需要建立一個作業定期跑作業就行,重複執行也不影響。
|
備註: 作者:pursuer.chen 部落格:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結,否則保留追究責任的權利。 《歡迎交流討論》 |