GALAXY: tcp connection live migration with CRIU
Galaxy is fascinating.

Program: simple client/server, loopback
Tools: CRIU does checkpoint/restore work
ps -ef
liuqius+ 20052 2464 0 22:00 pts/6 00:00:00 ./server 7022
liuqius+ 20053 2464 0 22:00 pts/6 00:00:00 ./client 127.0.0.1 7022
SIGCHLD:
When I start server and client, and then use CRIU to do checkpoint:
root@liuqiushan-K43SA:/home/liuqiushan/BCMatrix/criu/deps/criu-x86_64#
criu dump -D checkpoint -t 20052 –shell-job –tcp-established
Though it can generate the checkpoint image files, but some errors happen:
Error (parasite-syscall.c:389): si_code=1 si_pid=20114 si_status=0
Error (parasite-syscall.c:389): si_code=1 si_pid=20119 si_status=0
So let’s see parasite-syscall.c:
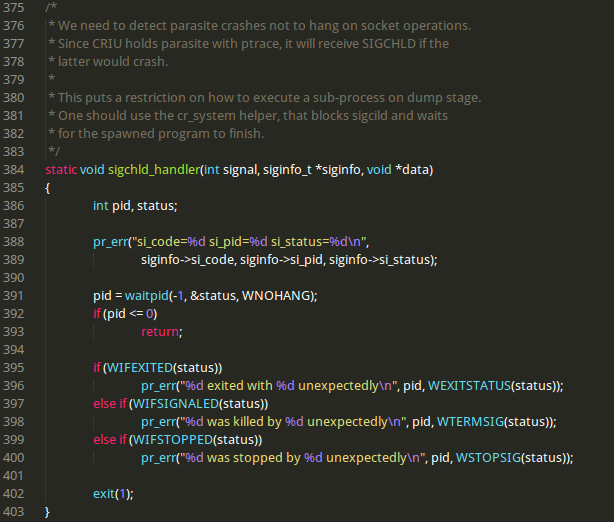
I think we can ignore the Error, because it uses SIGCHLD to do exit.
Continue.
We finish the dump work on server and client respectively. If we restore them at once, then it will succeed. But if we reboot the laptop, we will encounter the following Errors:
root@liuqiushan-K43SA:/home/liuqiushan/BCMatrix/criu/deps/criu-x86_64#
criu restore -d -D checkpoint –shell-job –tcp-established
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
Can’t read socket: Connection reset by peer
root@liuqiushan-K43SA:/home/liuqiushan/BCMatrix/criu/deps/criu-x86_64# criu restore -d -D checkpoint_client –shell-job –tcp-established
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
PP 26 -> -1
Pay attention to :
iptables: Bad rule (does a matching rule exist in that chain?).
And also through util.c and netfilter.c, we can focus on the problem of iptables.
More importantly, the server can restore successfully, but the client, it seems that:
the client also restores, but after ‘PP 26->-1 (above)’, it exit abnormally.
We should pay attention to these information:
- iptables: Bad rule (does a matching rule exist in that chain?).
- Can’t read socket: Connection reset by peer
- PP 26 -> -1
According to SIGCHLD mentioned above, I try such work:
first dump client. then server,
and restore server, then client
Also failed.
A little confusing.
iptables rule:
Now we care about:
Can’t read socket: Connection reset by peer
It’s fatal.
“Connection reset by peer” is the TCP/IP equivalent of slamming the
phone back on the hook. It’s more polite than merely not replying,
leaving one hanging. But it’s not the FIN-ACK expected of the truly
polite TCP/IP converseur.
So now the question is: who causes ‘Connection reset by peer’ ?
when do dump, CRIU does?
or
after reboot machine, iptables changed?
First, need more details about iptables.
Let us see: http://everything2.com/title/Connection+reset+by+peer
And I try this work:
make client build connection via while(1), so that it can rebuild a
connection after a connection reset by peer.
Failed. After reboot, the client still be terminated.
Pay attention to iptables and link above.
who sends RST?
But we should notice that though the tcp connection can not recover, the server can still restore, while the client is terminated. Care about the server side: why can it restore?
Pay attention to:
iptables: Bad rule (does a matching rule exist in that chain?)
I try to modify the source code of CRIU:
netfilter.c
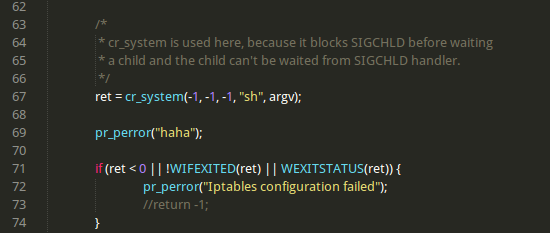
Because by reading its code, I think CRIU has restored the iptables rule related to the tcp connection, unless the rule is wrong.
No reboot: tcp checkpoint
And even though we don’t reboot the machine, we can do restore successfully only for the first time.
For the second time:
root@liuqiushan-K43SA:/home/liuqiushan/BCMatrix/criu/deps/criu-x86_64# criu restore -d -D checkpoint –shell-job –tcp-established
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
But it can restore successfully, the client and the server recover tcp connection.
But for the third time:
root@liuqiushan-K43SA:/home/liuqiushan/BCMatrix/criu/deps/criu-x86_64# criu restore -d -D checkpoint –shell-job –tcp-established
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
Can’t read socket: Connection reset by peer
Event though the server process recover, but its child process doesn’t recover.
Let us see the restore of the client:
root@liuqiushan-K43SA:/home/liuqiushan/BCMatrix/criu/deps/criu-x86_64# criu restore -d -D checkpoint_client –shell-job –tcp-established
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
iptables: Bad rule (does a matching rule exist in that chain?).
Error (util.c:580): exited, status=1
Error (netfilter.c:69): Iptables configuration failed: No such file or directory
PP 31 -> -1
It is obvious that the client process doesn’t recover, let alone tcp connection.
Important: The server proposes error: Can’t read socket: Connection reset by peer
And its child process which used for communicating with the client also doesn’t recover.
And also after the third time, the error always happens.
If we can restore the child process of the server process, it is likely to restore the client successfully.
Good news: it is easier for us to use google to search something, the keywords:
criu tcp checkpoint
I think we are getting closer to the truth.
RST packet:
The FIN packet causes the remote client to have a normal “connection closed” response from the socket API. The RST packet is what causes sockets to get the “connection reset by peer” response.
What’s ‘TCP connection repair’ ?
Migrating a running container from one physical host, through it, we can recover the connection.
So it is our only hope. The question is whether do we need to set it
by hand or it has been used by CRIU automatically?
CRIU uses it automatically.
However,
The TCP connection repair patches do not represent a complete solution
to the problem of checkpointing and restoring containers, but they are
an important step in that direction.
And, please see the following:
One thing to note here — while the socket is closed between dump and restore the connection should be “locked”, i.e. no packets from peer should enter the stack, otherwise the RST will be sent by a kernel. In order to do so a simple netfilter rule is configured that drops all the packets from peer to a socket we’re dealing with. This rule sits in the host netfilter tables after the criu dump command finishes and it should be there when you issue the criu restore one.
Conclusion:
So far, I think we can’t restore successfully after reboot. And event
though not reboot, we can only succeed for the first time restoring.
Because we should make the stack not changed. As mentioned above, ‘no packets from peer should enter the stack’
Verification:
To verify the reason, I have done so:
- on my laptop, start server and client.
- dump the serve, and then dump the client.
- only restore the server, we could see that the server process and its child process which is responsible for socket connection with the client both recover.
- then kill the two processes: kill -9 the child process, then kill -9 the server process
- wait for several minutes (otherwise, the port will be in use; after several minutes, the occupation will be lifted)
- only restore the serve for the second time, the two processes also both recover
- then kill the two processes
- restore the server for the third time, the two processes also both recover, and then restore the client:
Good News: TCP connection between the serve and the client recovers
Solution:
Now we can do restore successfully for the first time. Before you do restore for the second time, you should execute the command first:
iptables -A OUTPUT -p tcp --tcp-flags RST RST -s 127.0.0.1 -j DROP
Then restore the server, you will see the server process(including its child process which is responsible for the tcp connection with the client) recovers.
IMPORTANT: We should not restore the client at once, but we should wait for about 1 minute, then restore the client, you will see the client recovers successfully, including the socket between the server and the client.
You want to do the restore for the third time, do just like the second time:
first restore the server,
then wait for about 1 minute
finally restore the client, successfully!
The forth time , the fifth time, also like so.
The reason to wait: If we don’t wait for such time, restore the client
at once, although the client process recovers, but the tcp socket
connection will not recover. Only by waiting for such time before
restore the client, then restore the client successfully. I think the
server side needs such time (1 minute) to recover
something about the tcp connection between the serve and the client.
相關文章
- ascp: Failed to open TCP connection for SSH, exiting. Session Stop (Error: Failed to open TCP connection for SSH)AITCPSessionError
- http keep-alive與tcp keep-aliveHTTPKeep-AliveTCP
- PostgreSQL DBA(187) - TCP keepaliveSQLTCP
- 嚴重 [RMI TCP Connection(3)-127.0.0.1]TCP127.0.0.1
- 1 Million TCP Connection 問題解決TCP
- 聊聊TCP Keepalive、Netty和DockerTCPNettyDocker
- 對付Reset流氓干擾:TCP keepaliveTCP
- Oracle ENABLE=broken引數與TCP KeepAliveOracleTCP
- [轉載]TCP keepalive的詳解(解惑)TCP
- 轉載:有關SQL server connection KeepAlive 的FAQSQLServer
- HAproxy&keepalived 實現tcp負載均衡TCP負載
- TCP 的 Keepalive 和 HTTP 的 Keep-Alive 是一個東西嗎?TCPHTTPKeep-Alive
- 關於 Http 協議中的 keep-alive 與 Tcp keep-aliveHTTP協議Keep-AliveTCP
- 轉載:有關SQL server connection Keep Alive 的FAQ(2)SQLServer
- 轉載:有關SQL server connection Keep Alive 的FAQ(3)SQLServer
- TCP漫談之keepalive和time_waitTCPAI
- TCP KeepAlive機制理解與實踐小結TCP
- linux下使用TCP存活(keepalive)定時器LinuxTCP定時器
- oracle OGG-01232 Receive TCP params error:TCP/IP error 232(connection reset)OracleTCPError
- OGG 同步報錯 - TCP/IP error 111 (Connection refused)TCPError
- CS144 計算機網路 Lab4:TCP ConnectionCS144計算機網路TCP
- OGG-01223 TCP/IP error 79 (Connection refused)TCPError
- [20170504]Linux TCP keepalive timers.txtLinuxTCP
- HTTP 請求頭部欄位中 connection - keep-alive 的含義HTTPKeep-Alive
- 0503linux核心網路引數測試tcp_keepaliveLinuxTCP
- Laravel migration 逆向生成工具Laravel
- make:migration 的騷操作
- Row Migration和row chainedAI
- A Data Migration for Every Django ProjectDjangoProject
- Web 伺服器啟用 connection - keep-alive 的一些前置條件Web伺服器Keep-Alive
- nginx-upstream-keepalive;accept_mutex-proxy_http_version-1.1-proxy_set_header-connectionNginxMutexHTTPHeader
- [20180126]核心引數tcp_keepalive.txtTCP
- 2.3.4 Migration of an Existing ApplicationAPP
- EF Code First Migration總結
- new feature ——>mysql to oracle MigrationMySqlOracle
- 遷移執行緒migration執行緒
- Connection
- GoldenGate Pump Porcess: TCP/IP error 110 (Connection timed out)的問題解決GoTCPError