實現 vector 的四則運算
這裡假設 vector 的運算定義為對運算元 vector 中相同位置的元素進行運算,最後得到一個新的 vector。具體來說就是,假如 vector<int> d1{1, 2, 3}, d2{4, 5, 6};則, v1 + v2 等於 {5, 7, 9}。實現這樣的運算看起來並不是很難,一個非常直觀的做法如下所示:
vector<int> operator+(const vector<int>& v1, const vector<int>& v2) {
// 假設 v1.size() == v2.size()
vector<int> r;
r.reserve(v1.size());
for (auto i = 0; i < v1.size(); ++i) {
r.push_back(v1[i] + v2[i]);
}
return r;
}
// 同理,需要過載其它運算子我們針對 vector 過載了每種運算子,這樣一來,vector 的運算就與一般簡單型別無異,實現也很直白明瞭,但顯然這個直白的做法有一個嚴重的問題:效率不高。效率不高的原因在於整個運算過程中,每一步的運算都產生了中間結果,而中間結果是個 vector,因此每次都要分配記憶體,如果參與運算的 vector 比較大,然後運算又比較長的話,效率會比較低,有沒有更好的做法?
既然每次運算產生中間結果會導致效率問題,那能不能優化掉中間結果?回過頭來看,這種 vector 的加減乘除與普通四則運算並無太大差異,在編譯原理中,對這類表示式進行求值通常可以通過先把表示式轉為一棵樹,然後通過遍歷這棵樹來得到最後的結果,結果的計算是一次性完成的,並不需要儲存中間狀態,比如對於表示式:v1 + v2 * v3,我們通常可以先將其轉化為如下樣子的樹:

因此求值就變成一次簡單的中序遍歷,那麼我們的 vector 運算是否也可以這樣做呢?
表示式模板
要把中間結果去掉,關鍵是要推遲對錶達式的求值,但 c++ 語言成面上不支援 lazy evaluation,因此需要想辦法把表示式的這些中間步驟以及狀態,用一個輕量的物件儲存起來,具體來說,就是需要能夠將表示式的中間步驟的運算元以及操作型別封裝起來,以便在需要時能動態的執行這些運算得到結果,為此需要定義類似如下這樣一個類:
enum OpType {
OT_ADD,
OT_SUB,
OT_MUL,
OT_DIV,
};
class VecTmp {
int type_;
const vector<int>& op1_;
const vector<int>& op2_;
public:
VecTmp(int type, const vector<int>& op1, const vector<int>& op2)
: type_(type), op1_(op1), op2_(op2) {}
int operator[](const int i) const {
switch(type_) {
case OT_ADD: return op1_[i] + op2_[i];
case OT_SUB: return op1_[i] - op2_[i];
case OT_MUL: return op1_[i] * op2_[i];
case OT_DIV: return op1_[i] / op2_[i];
default: throw "bad type";
}
}
};
有了這個類,我們就可以把一個簡單的運算表示式的結果封裝到一個物件裡面去了,當然,我們得先將加法操作符(以及其它操作符)過載一下:
VecTmp operator+(const vector<int>& op1, const vector<int>& op2) {
return VecTmp(OT_ADD, op1, op2);
}這樣一來,對於 v1 + v2,我們就得到了一個非常輕量的 VecTmp 物件,而該物件可以很輕鬆地轉化為 v1 + v2 的結果(遍歷一遍 VecTmp 中儲存的運算元)。但上面的做法還不能處理 v1 + v2 * v3 這樣的套嵌的複雜表示式:v2 * v3 得到一個 VecTmp,那 v1 + VecTmp 怎麼搞呢?
同理,我們還是得把 v1 + VecTmp 放到一個輕量的物件裡,因此最好我們的 VecTmp 中儲存的運算元也能是 VecTmp 型別的,有點遞迴的味道。。。用模板就可以了,於是得到如下程式碼:
#include <vector>
#include <iostream>
using namespace std;
enum OpType {
OT_ADD,
OT_SUB,
OT_MUL,
OT_DIV,
};
template<class T1, class T2>
class VecSum {
OpType type_;
const T1& op1_;
const T2& op2_;
public:
VecSum(int type, const T1& op1, const T2& op2): type_(type), op1_(op1), op2_(op2) {}
int operator[](const int i) const {
switch(type_) {
case OT_ADD: return op1_[i] + op2_[i];
case OT_SUB: return op1_[i] - op2_[i];
case OT_MUL: return op1_[i] * op2_[i];
case OT_DIV: return op1_[i] / op2_[i];
default: throw "bad type";
}
}
};
template<class T1, class T2>
VecSum<T1, T2> operator+(const T1& t1, const T2& t2) {
return VecSum<T1, T2>(OT_ADD, t1, t2);
}
template<class T1, class T2>
VecSum<T1, T2> operator*(const T1& t1, const T2& t2) {
return VecSum<T1, T2>(OT_MUL, t1, t2);
}
int main() {
std::vector<int> v1{1, 2, 3}, v2{4, 5, 6}, v3{7, 8, 9};
auto r = v1 + v2 * v3;
for (auto i = 0; i < r.size(); ++i) {
std::cout << r[i] << " ";
}
}
上面的程式碼漂亮地解決了前面提到的效率問題,擴充套件性也很好(能夠方便地增加對其它運算型別的支援),而且對 vector 來說還是非侵入性的,當然了,實現上乍看起來可能就不是很直觀了,除此也還有些小問題可以更完善:
- 操作符過載那裡很可能會影響別的型別,因此最好限制一下,只針對
vector<int>和VecTmp<>進行過載,這裡可以用 SFINAE 來處理。 VecTmp<>的 operator[] 函式中的 switch 可以優化掉,VecTmp<>模板只需增加一個引數,然後對各種運算型別進行偏特化就可以了。VecTmp<>對運算元的型別是有隱性要求的,只能是vector<int>或者是VecTmp<>,這裡也應該用 SFINAE 強化一下限制,使得用錯時出錯資訊可以好看些。
現在我們來重頭再看看這一小段奇怪的程式碼,顯然關鍵在於 VecTmp<> 這個模板,我們可以發現,它的介面其實很簡單直白,但它的型別卻可以是那麼地複雜,比如說對於 v1 + v2 * v3 這個表示式,它的結果的型別是這樣的: VecTmp<vector<int>, VecTmp<vector<int>, vector<int>>>,可以想象如果表示式再複雜些,它的型別也會跟著更復雜,如果你看仔細點,是不是還發現這東西和哪裡很像?像一棵樹,一棵型別的樹:
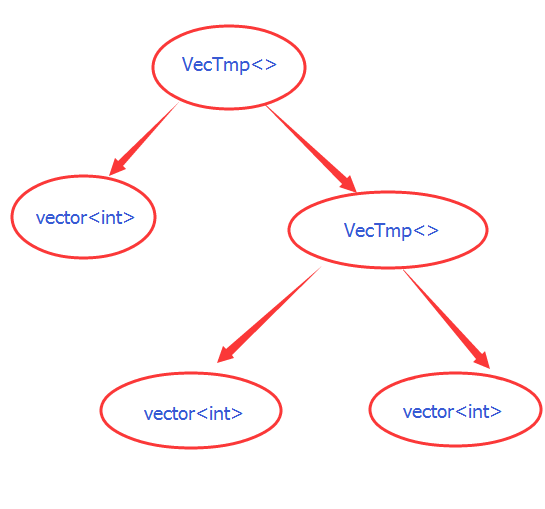
這棵樹看起來是不是還很眼熟,每個葉子結點都是 vector<int>,而每個內部結點則是由 VecTmp<> 例項化的:這是一棵型別的樹,在編譯時就確定了。這種通過表示式在編譯時得到的複雜型別有一個學名叫: Expression template。在 c++ 中每一個表示式必產生一個結果,而結果必然有型別,型別是編譯時的東西,結果卻是執行時的。像這種運算表示式,它的最終型別是由表示式中每一步運算所產生的結果所對應的型別組合起來所決定的,型別確定的過程其實和表示式的識別是一致的。
而 VecTmp 物件在邏輯上其實也是一棵樹,它的成員變數 op1_, op2_ 分別是左右兒子結點,樹的內部結點代表一個運算,一個動作,左右兒子為其運算元,葉子結點則代表直接數(或 terminal),一遍中序遍歷下來,得到的就是整個表示式的值。
神奇的 boost::proto
expression template 是個好東西(就正如 expression SFINAE 一樣),它能幫助你根據給定的表示式,在編譯時建立非常複雜好玩的型別(從而實現很多高階玩意,主要是函式式,EDSL 等)。但顯然如果什麼東西都需要自己從頭開始寫,這個技術用起來還是很麻煩痛苦的,好在模板超程式設計實在是個太好玩的東西,已經有很多人做了很多先驅性的工作,看看 boost proto 吧,在 c++ 的世界裡再開啟一扇通往奇怪世界的大門。