breakpad 是什麼
breakpad 是一個包含了一系列庫檔案和工具的開源工具包,使用它可以幫助我們在程式崩潰後進行一系列的後續處理,如現場的儲存(core dump),及事後分析(重建 call stack )等,它提供了非常有效且易用的工具來幫助開發者處理程式的異常崩潰。該專案由 google 所開發維護並開源,程式碼託管在 google code 上。
breakpad 具有跨平臺的特性,支援 window, linux, mac 三大平臺,可以執行於一系列架構的 cpu 上,現在已經被廣泛運用在 google 的一系列產品及其它公司的桌面程式上,如 chrome,piscal,firefox 等。 這篇文章主要介紹一下其在 linux 下結構,breakpad 主要包括三大主件:
1) client.
2) symbol dumper.
3) processor.
各個模組
(1) client module.
client 模組作為一個靜態庫將會與使用者的程式編譯在一塊。它的主要作用是在程式崩潰後,接管程式的異常處理,具體來說,它主要做了兩方面的事情:
a) 響應程式崩潰時接收到的 signal,包括:SIGSEGV,SIGABRT,SIGFPE,SIGILL,SIGBUS。(另外兩個 SIGSTOP 和 SIGKILL 無法處理)
b) 獲取程式崩潰那一刻的執行時資訊,儲存為一個 mini dump 格式的檔案(可以想像為一個特殊格式的 core dump)
下圖描述了 client module 中幾個類的關係及工作的流程:
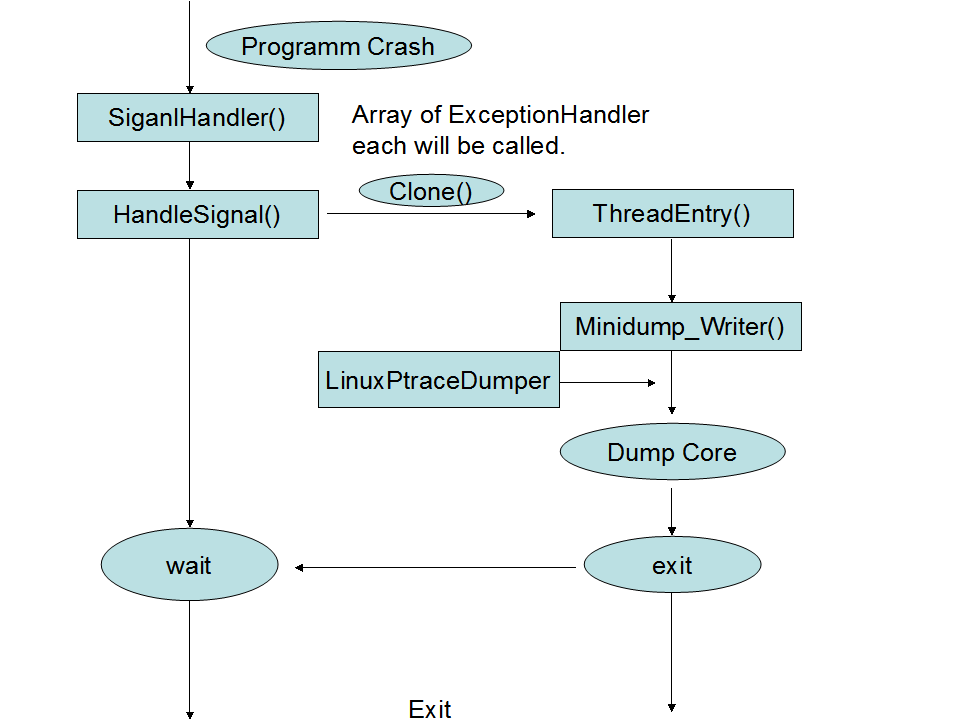
如上,breakpad 通過提供訊號處理函式來響應程式的崩潰,然後在訊號處理函式中,儲存程式崩潰時的現場資訊,在這裡有幾點需要說明:
a) 程式崩潰後,整個程式空間已經處於一個不穩定的狀態,在這樣的不穩定狀態下,再進行記憶體的分配,和呼叫動態庫裡的函式,都是不安全的。之所以說處在不穩定狀態,主要是指如果當前的崩潰是由 SIGSEGV 引起的,那麼此時程式的記憶體可能已經被破壞了(heap,stack,資料段),而引用動態庫是需要查詢一堆資料段裡的表項(plt,got),這些資料很可能已經被破壞,因此沒法正確載入動態庫,至於不能 malloc 那是基本同理的,heap 可能已經被破壞了,malloc 內部維護的資料未必還正常,也就無法保證還能正確進行 malloc。
b) 訊號處理函式會 clone 出一個新的程式,dump core 這件事情則是在這個 clone 出來的子程式中進行的,子程式通過 ptrace 來與父程式進行互動,從而讀取父程式的相關資訊。
c) breakpad 的 exception handling 有兩種模式,一種是 in process,一種是 out of process。但在 Linux 平臺上,暫時只有 in process 這種模式,in process 的實現相對簡單些,流程很清楚明瞭,out of process 相對就複雜了。按照開發者的設計意想,是為每一個登陸 Linux 的登陸使用者起一個 deamon 程式執行於後臺,當該使用者的其它程式崩潰後,崩潰程式通過與這個 deamon 程式進行互動,從而儲存 core dump。其中,互動方面將通過 socket 按照client/server 的模式進行,但是至今為止,這種模式還未可用。
在上圖中,MinidumpWriter 這個類是一個包裝,提供一些與 write dump 相關的介面函式給上層的函式處理函式進行呼叫,真正與 linux process 相關的操作都放在 LinuxPtraceDump 這個類中進行。client 程式崩潰之後中,dump 出來的內容主要包含以下幾個內容:
a) 各個執行緒相關的執行時資訊。如 stack pointer,context,mapping 等,以一個執行緒為單位儲存在一個陣列中(list)。
b) 當前程式的各種記憶體對映(Mapping)
c) 使用者指定的記憶體區域(application-provided memory regions)
d) 異常資訊(crash address, signal, thread id, context)
e) 當前系統的資訊 (cpu, os info)
上述的內容會以 minidump 的格式組織起來儲存為一個二進位制檔案,minidump 格式是一種簡單的流格式,由微軟所設計,具體可看下圖:

上圖中,_MINIDUMP_DIRECTOR 就是各種流的 container,流的型別不同,它所包含的資料形式就有所不同。具體各個流的資料格式是怎樣的,可以參考一下 MSDN 的說明:http://msdn.microsoft.com/en-us/library/windows/desktop/ms680394(v=vs.85).aspx
(2) symbol dumper.
這個模組主要是用來從可執行程式中提取與符號相關的資訊,並儲存為一種特定格式的檔案。為什麼要提取符號資訊? 根據前面的介紹,client 模組在程式崩潰時儲存了一個 core dump 檔案,但這個 core dump 出於簡單及實用考慮,儲存的都是些二進位制的資料,只通過這些資料,我們根本無法重建出可讀的 call stack. 因此 symbol dumper 就是用來產生一個可與 core dum p配合起來使用的符號檔案。
編譯非 release 版本的程式時(如,gcc 開了-g 選項),編譯器通常會將帶有符號相關的資訊以某種格式(DWARF,STABS)組織起來,存放在可執行檔案的某個段位裡。breakpad 的 symbol dumper 就是要從這些段位裡提取出它認為有用的資訊。
下面具體來說一下這個 symbol file:
1)symbol file 中全部內容都是ascii文字。
2)symbol file 的內容以行單位,每一行稱作一條記錄,每條記錄中有多個欄位,每個欄位以空格分開。
3)每條記錄的開頭是一個串字元,這個字元標記這條記錄是什麼型別的記錄。但 Line record 除外,這種型別的記錄,預設省略掉標記符,也就是如果有一行沒有標記型別,這一行就是一個Line record.
4)記錄中有些欄位是10進位制或16進位制的字串,16進位制也沒有以0x開頭,要分清某個數字具體是哪種進位制,就要看這些數字是在哪種記錄裡,屬於哪個欄位,這些都是規定死了的。
記錄的型別主要有以下幾種:
- MODULE: 這種記錄用來描述當前這個可執行檔案。這條記錄是 symbol file 的第一條記錄。
- FILE: 這種記錄用來記錄原始檔,包含有檔名及路徑資訊。這個型別的記錄會被分配一個整形符號來作標記,然後在別的記錄中可能會引用它。
- FUNC: 這種記錄用來描述一個函式,包含函式名,函式在可執行檔案中的地址等資訊。
- 行記錄: 這種記錄用來描述,一個給定範圍的機器指令對應哪個原始檔的哪一行。行記錄總是跟在FUNC記錄後面,從而描述每個函式裡的指令對應在原始碼裡的位置。
- PUBLIC: 這種記錄用來描述每一個連結符號的地址,如彙編函式裡的各個入口點。
- STACK WIN: 這種記錄用來描述函式呼叫時,函式幀(stack frame)的佈局。有了這個記錄,給定一特定的函式幀 F,就可以找到哪個函式幀呼叫了F。
- STACK CFI: CFI,就是 Call Frame Info,這種記錄用來表述當執行到某條指令的時候,怎樣去檢視當前的函式呼叫棧。
上面主要講了 symbol file 中的內容是怎樣組織的,這裡並不管其中的 symbol 是來自 DWARF,還是 STABS,這也正是 breakpad 定製自己的 symbol 格式的意義所在。
(3) processor module.
前面所介紹的兩個模組,分別輸出了 coredump,及 symbol file。這裡要介紹的 processor 模組,它的作用就是根據 coredump 及 symbol file,構建出可讀的 call stack. stackwalking 從 MinidumpProcessor 這個類開始,入口函式 MinidumpProcessor::Process() 以 symbol file,minidump file 為引數。
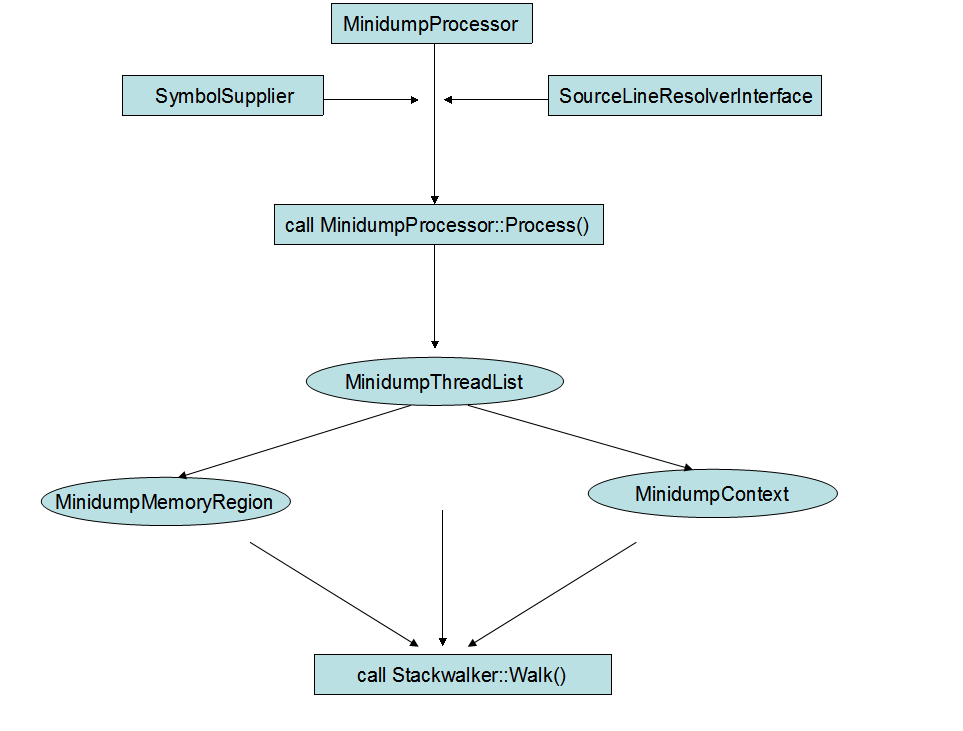
需要說明的是,stack walking 是針對每一個執行緒進行的。minidump 中儲存了每個執行緒執行時的相關資訊,這些資訊都會在 Process()函式中被提取出來。MinidumpMemoryRegion 包含著執行緒的呼叫棧,MinidumpContext 包含著執行緒的 cpu context。stackwalking 開始時,Stackwalker::Walk() 根據不同的cpu,構建出當前執行緒的 top frame,也就是函式呼叫的最頂一層。然後從 top frame 開始,對整個呼叫棧的棧幀進行解析,解析的過程,包含有幾方面的內容:
(a) 查詢模組
根據當前幀的 eip(x86) 來呼叫 CodeModules::GetModuleForAddress() 返回當前 frame 所屬的模組資訊。
(b) 定位符號
前面找到模組後,找到只是二進位制相關的資訊。要找到這個模組相應的名字及模組裡其它函式,變數的名字等,還需要用到之前 symbole file.這裡需要注意的是,symbol file 可能不止一個,因此需要能夠根據當前的模組來定位到,與這個模組相關的 symbol file 是哪個。SimpleSymbolSupplier 這個類就是用來做這個事情,它會結合當前模組的資訊,定位到與當前 module 相關的 symbol file。
(c) 查詢符號
前面一步找到了 symbol file。這裡就需要根據 symbol file 來輸出具體的符號。SourceLineResolverInterface 這個類的 LoadModuleUsingMemoryBuffer() 用來把 symbol file 載入進記憶體,並解析。BasicSourceLineResolver 這個類則是提供對外的介面,用於根據某個地址,查詢出對應的符號名字,如,輸入一個函式地址,返回函式的名字。
(d) 查詢出當前幀的呼叫幀
當前幀解析完後,需要繼續去解析呼叫當前幀的父幀。要做到這件事情,必須要有 symbol file 的支援。回憶一下,symbol file 中有二種記錄型別:stack win,stack cfi。這兩種型別的記錄完整的描述了各類函式呼叫的棧幀佈局,因此藉助這些記錄理論上就可以找回當前幀的呼叫幀。SourceLineResolverInterface就是用來做這些事情。具體可以檢視它的成員函式,FindWindowsFrameInfo() 及FindCFIFrameInfo()。
總結
工欲善其事必先利其器,對程式開發來說,尤其如此,好的工具常常能對我們的工作起到事半工倍的作用,而對於工具的使用我們不應僅僅滿足於知道怎麼用,知其然也要能知其所以然,學習和分析別人的工具是怎麼做出來的,不僅能幫助我們更好地理解和使用這些工具,更重要的是能幫助我們開闊視野和增長知識。前文對 breakpad 在 linux 平臺下的實現做了簡單介紹,從中我們可以看出一個完善的工具鏈實現起來是一項浩大的工程,涉及到許多方方面面的知識,裡面可以學習的東西很多,需要完善的東西也很多,breakpad 作為一個開源專案,現在仍處在開發和完善的過程中,回饋開源的最好方式就是加入其中貢獻你的力量,希望本文能對有興趣的讀者有幫助。