0x00 預先準備和時間規劃
1.因為要用到visual studio 2013,準備學習C#,預計一天時間能基本使用。
3.瞭解需求並設計基本資料結構與大致流程 20min
2.根據提議實現simple mode 30min
3.擴充套件simple mode的功能完成extend mode 1h
0x01 實際用時和實現過程
1.關於C#的學習,看了一下基本模式和C++、Java差不多,而且在寫程式碼的過程中能更快地熟悉語言,實際只准備了20分鐘就提刀上陣了。
2.瞭解需求並瞭解需求並設計基本資料結構與大致流程。
1) 需求分析很快,核心功能是字串的處理,詞頻統計,其中需要注意的是大小寫的處理、排序、單詞長度和單詞的模式("^[a-zA-z][0-9]*");
2)最開始面臨的問題是檔案的遞迴掃描,利用如下程式碼即可得到所有滿足要求的檔名稱。
Directory.GetFiles(path, "*.*", SearchOption.AllDirectories).Where(s => s.EndsWith(".txt") || s.EndsWith(".cpp") || s.EndsWith(".h") || s.EndsWith(".cs"));
3)接下來是字串的處理,詞頻統計這一功能是很容易實現的,利用容器Dictionary來儲存鍵值對即可。由於要處理大小寫,這裡用到了兩個Dictionary。
static Dictionary<string, int> wordtable = new Dictionary<string, int>(); static Dictionary<string, string> word = new Dictionary<string, string>();
4)其中wordtable的key是單詞的小寫形式,value是頻度;word的key是單詞的小寫形式,value是優先順序最高的單詞形式,(如word["file"] = "File"; wordtable["file"] = 1;),再考慮到排序是先value在key,即可完成simple mode;
5)對於extend mode,字串處理的方法是先從檔案中得到形如“word1 wrod2 ... wordn”形式的長字串,再對這個字串不斷匹配符合要求的“word1 word2”(或“word1 word2 word3”)形式的字串,把它當作wordtable中的key,其他方法和simple mode中的一樣。
整個過程,大概花了7h左右的時間,主要是C#語言許多方法不熟悉,以及在程式設計過程中遇到了許多技術問題。其中,為了高效地完成匹配,在正規表示式的學習上就花了不少時間,還有從Simple mode到extend mode的過程中進行了許多嘗試、debug。
0x10效能分析及程式碼優化
1.Word_frequency.exe D:\test 316ms
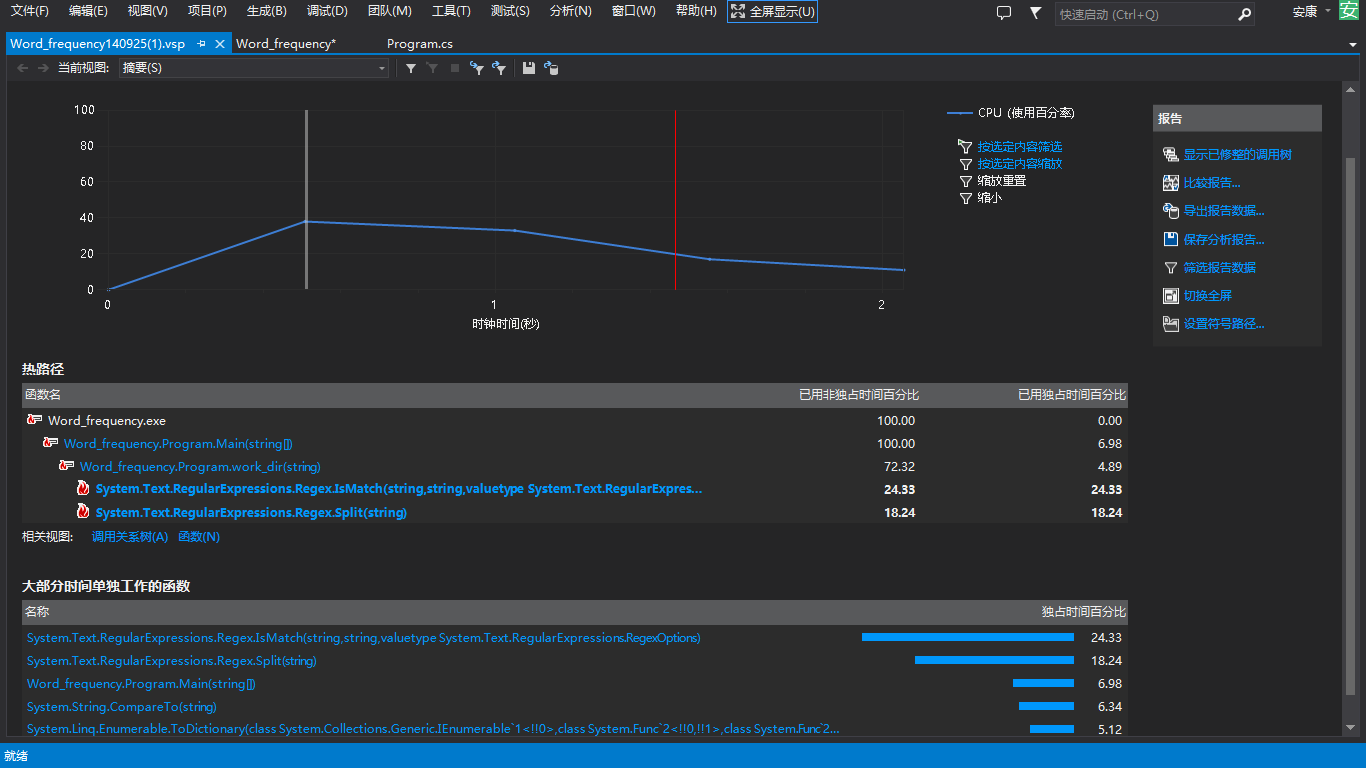
2.Word_frequency.exe -e2 D:\test 475ms
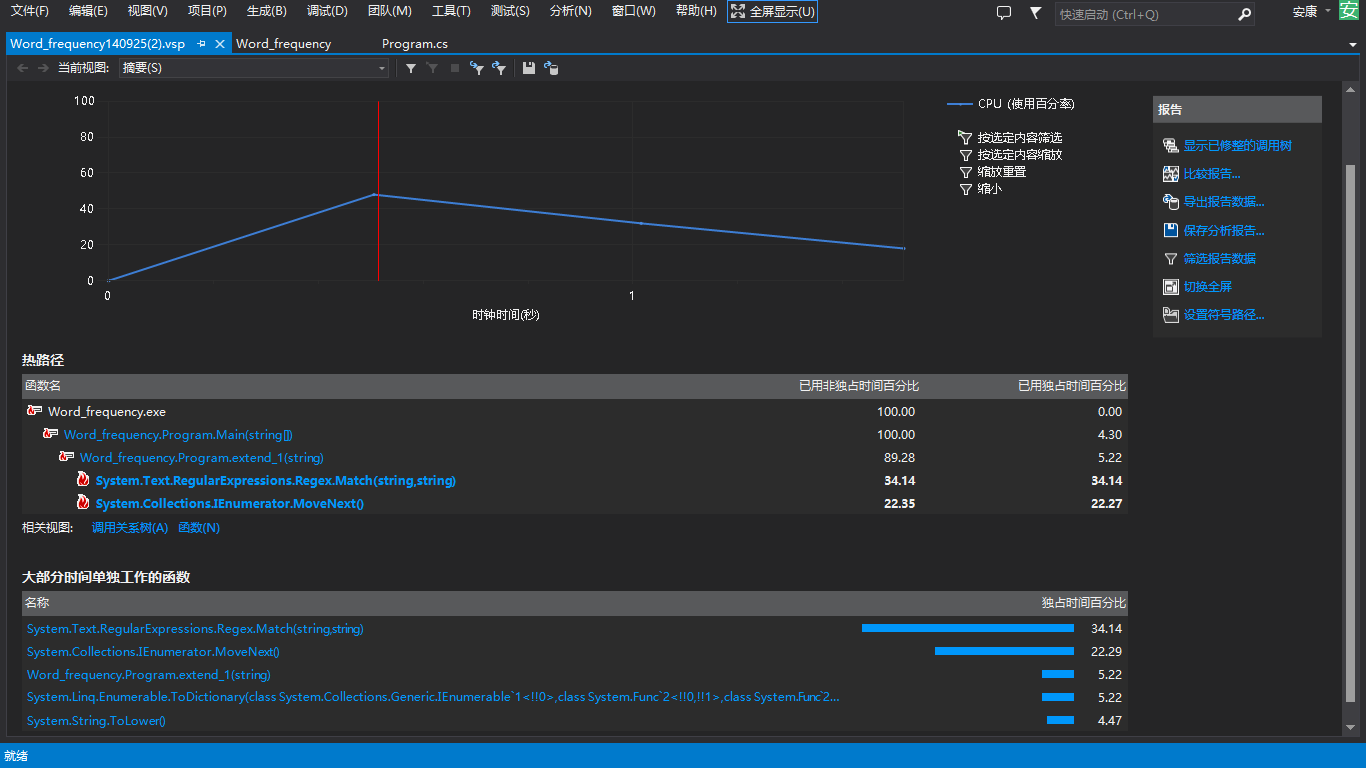
3.Word_frequency.exe -e3 D:\test 559ms

由此可見,程式執行的效能主要取決於正則匹配的效能,三次測試時間的變化主要源於匹配的單詞的複雜度的提升,但這方面是沒有跟多優化空間的,顆星的提升效能的辦法就是採用多執行緒,同時對多個檔案進行處理,可以有效減少程式執行時間,犧牲部分記憶體提升效能。
0x11事後諸葛亮總結
1) 萬萬沒想到,終於還是在deadlin前完成了。這次作業雖然完成了全部的功能,但從程式效能還是自己程式碼風格,都沒做到很好。C#才接觸,多執行緒實現有心無力,雖然對於少量檔案來說沒什麼影響,但在大量檔案測試線表現平平;程式碼中有很多可以複用的程式碼段,但我可恥得選擇了ctrl C+V,使得程式碼冗餘度很高,希望在下一次專案中能儘量避免。
2)專案過程中的不足:
.對於常用類、方法的認識嚴重不足,查詢一個引數都花了很長世間;
.在碼程式碼的過程中老是想著有現成的方法可以用,演算法思想都去哪了?!
.還是沒寫出多執行緒。。。
3) 收穫還是不小,c#使用熟練度上上升了好幾個百分點,也終於學到了聽起來很厲害的正規表示式,對程式測試的大致流程也有了較多瞭解。