如何不斷擴充資料中心的資料規模,提升資料探勘的價值,這是我們思考的問題,資料一方面來自於內部生產,一部分資料可以來自於網際網路,網際網路上的資料體量龐大,形態多樣,之前blog裡很多FMEer已經提出了方案,比如json,xml,正規表示式等等,但對於比較鬆散的HTML如何進行資料解析提取呢?我問了一下度娘,貌似沒有FME下的文章,恰逢今天有時間,就寫一點關於HTML提取的東東,算是自己做的筆記吧!
這次我要提取的範例資料來自國土資源局土地招拍掛系統,我要提取上面的交易結果以及地塊資訊,樣式如下圖:

圖1:交易結果列表

圖2:地塊資訊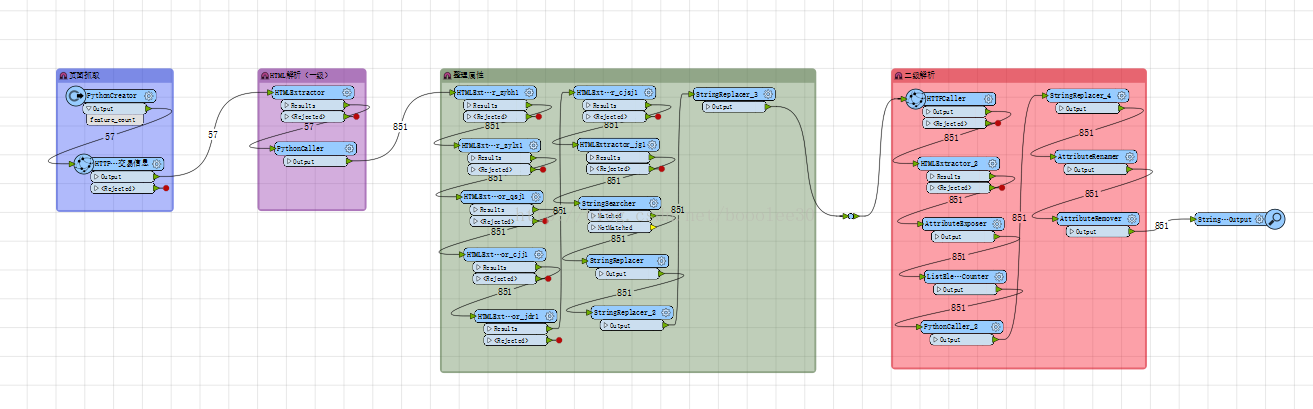
圖3:轉換工程
圖4:提取後的資料
在這個轉換工程裡,用到了幾個轉換器,它們是:pythonCreator,HTTPCaller,HTMLExtractor、PythonCaller、StringSearcher、StringReplacer、AttributeExposer、AttributeRenamer、AttributeRemover
本文重點介紹一下HTMLExtractor,轉換器的引數如下圖:
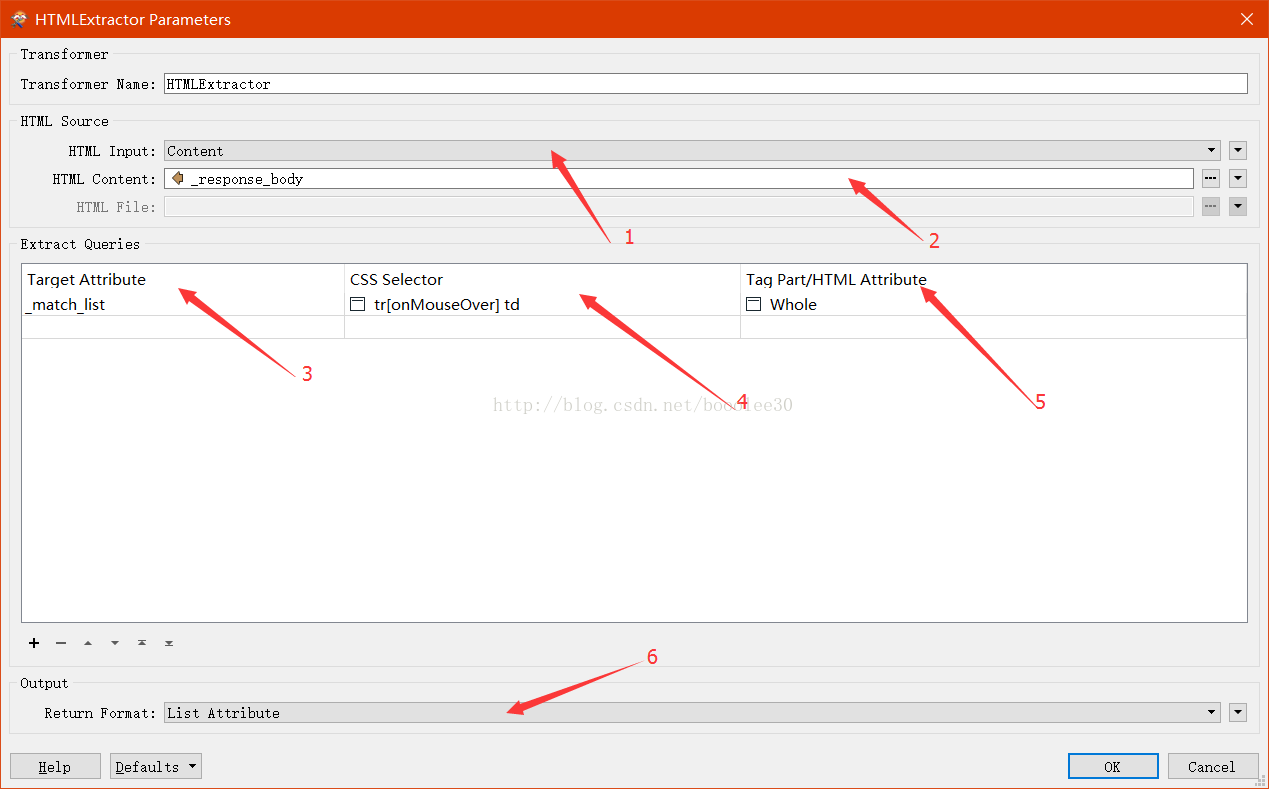
圖5:HTMLExtractor引數
圖上標註的引數依次是:
1、 HTML Input:HTML的內容來源,可以是content,表示來源於傳入的屬性、引數等,也可以是File,表示來源於一個已存在的HTML檔案。
2、 HTML Content:本案例用的是content作為源,與HttpCaller連用,HTML存放於_response_body屬性中。如果是File作為源,則需要設定HTML File為檔案路徑。
3、 Target Attribute:設定一個屬性(列表)名稱,這個屬性名稱將包含HTML解析的結果。
4、 CSS Selector:設定CSS選擇器,類似正規表示式,但用起來更簡單,特別適合解析HTML。
5、 Tag Part/HTML Attribute:可以設定為Value(匹配標籤裡的值)、Whole(匹配的標籤和值)、或者輸入匹配標籤擁有的一個屬性名稱,比如<a>標記的href屬性。
6、 Return Format:可以設定為List Attribute,則將所有匹配的內容作為一個list返回,如果為First Match,則僅返回第一個匹配的內容。
舉個栗子,下面是我要匹配的交易結果HTML原始檔:
<tr class="TR2" onMouseOver="this.className='TR3';" onMouseOut="this.className='TR2';">
<td height="31" align="left" class="TD1"><img src="images/arrow_yellow.gif">2</td>
<td class="TD1" align="left">BQ2-19-87</td>
<td class="TD1" align="left">國有建設用地使用權</td>
<td class="TD1" align="left">15851.0萬元</td>
<td class="TD1" align="left">15851.0萬元</td>
<td class="TD1" align="left">西安奧達房地產開發有限責任公司</td>
<td class="TD1" align="left">2017-04-27 16:00</td>
<td class="TD1" align="center" style="color:#FF0000;cursor:pointer;" onClick="window.open('publics/ResourceFrame.jsp?id=933&lx=L','','left=10,top=10,width=890,height=650,scrollbars=yes,resizable=yes,status=yes')">已成交</td>
</tr>
我要把紅色的內容提取出來,我只需要簡單的寫一句CSS選擇器進行匹配即可,但在寫之前一般是要先整理分析一下HTML原始檔,找出可以用於匹配的特徵,提高匹配的準確度,減少其他雜質資料被提取出來。
因為HTML原始檔中有大量的<td>,所以直接匹配td是不行的,經過分析我找到了特徵,CSS選擇器為:tr[onMouseOver] td。意思是擁有onMouseOver屬性的tr標記下的td標記。
就這麼簡單,獲取的資料還有少量雜質,再用其他的轉換器清洗一下即可。
另外,最近正規表示式呼聲很高,必須承認,正規表示式非常強大,但有些工作還是有更簡單的辦法,殺雞焉用牛刀,對於HTML,通過編寫CSS選擇器應用HTMLExtractor轉換器來解析資料,更加敏捷高效!