今天閱讀了一下大型網路技術架構這本蘇中的分散式快取一致性hash演算法這一節,針對大型分散式系統來說,快取在該系統中必不可少,分散式叢集環境中,會出現新增快取節點的需求,這樣需要保障快取伺服器中對快取的命中率,就有很大的要求了:
採用普通方法,將key值進行取hash後對分散式快取機器數目進行取餘,以叢集3臺分散式快取為例子:
對於資料進行取hash值然後對3其進行取餘,餘數為0則進入node 0,餘數位1則進入node1,餘數位2則進入node2.
如果增加一個節點則對4進行取餘,則會將node0中的部分,node1中的部分,node2中的部分分割到node3中,則出現了命中率為75%
如果增加2個節點的話則對5進行取餘,則只有3/5的機器被命中
普通方法的設計會導致當你的節點新增的數目越多,導致你的命中率越低導致對資料庫的操作壓力就越大
採用一致性Hash演算法:
構造一個0~2^32的整數環,然後將節點的名稱比如說node0對其進行取hash值將其分佈在該店上,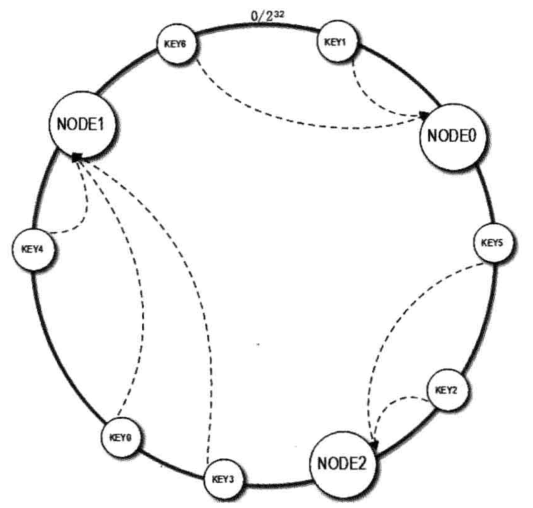
然後將key值取hash值後進行比較:
舉例:node0的hash值為432323232;node1 hash值為879798098,則如果key1的hash值為559798098,則其大於node0的hashi值,則順時針旋轉,找到了node1則將其存放在node1中的快取中。
擴容後,將三個變成4個
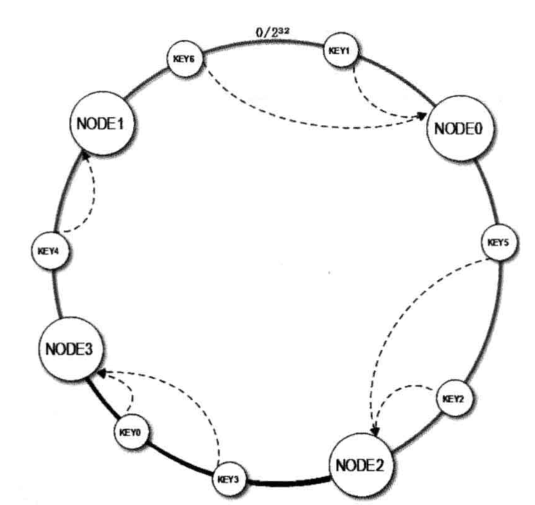
在node2和node0中插入一個node3,則導致node2到node1中中原先存放在node1中的資料分成兩半,node2-node3部分存放在node3中,node3和node1的存放在node1中,則可以看出node0-node2以及node0-node1中這段沒有改變。則也是75%但是還有問題就是node2和node0的負載數是node2的一倍,所以還是得出現解決辦法
引用虛擬的方式:將一個物理分散式快取伺服器分層n個虛擬機器,分佈在這個圓環周圍,由於hash雜湊的不規則性,他會分佈於不同的區域,見下圖,如果再次插入新伺服器之後,他會在器分佈的虛擬機器器上不規則的分佈於各個點中,則會比較均勻的分佈在各個環中,這樣影響的可以將上面的問題解決了。

根據該書說明,在實踐中,一臺物理伺服器虛擬成150個虛擬伺服器節點合適。