1. List的實現類主要有: LinkedList, ArrayList, Vector, Stack。
(01) LinkedList是雙向連結串列實現的雙端佇列;它不是執行緒安全的。僅僅適用於單執行緒。
(02) ArrayList是陣列實現的佇列,它是一個動態陣列。它也不是執行緒安全的,僅僅適用於單執行緒。
(03) Vector是陣列實現的向量佇列,它也一個動態陣列;只是和ArrayList不同的是。Vector是執行緒安全的,它支援併發。
(04) Stack是Vector實現的棧;和Vector一樣,它也是執行緒安全的。
2. Set的實現類主要有: HastSet和TreeSet。
(01) HashSet是一個沒有反覆元素的集合,它通過HashMap實現的;HashSet不是執行緒安全的。僅僅適用於單執行緒。
(02) TreeSet也是一個沒有反覆元素的集合,只是和HashSet不同的是,TreeSet中的元素是有序的。它是通過TreeMap實現的。TreeSet也不是執行緒安全的,僅僅適用於單執行緒。
3.Map的實現類主要有: HashMap,WeakHashMap, Hashtable和TreeMap。
(01) HashMap是儲存“鍵-值對”的雜湊表;它不是執行緒安全的,僅僅適用於單執行緒。
(02) WeakHashMap是也是雜湊表。和HashMap不同的是,HashMap的“鍵”是強引用型別,而WeakHashMap的“鍵”是弱引用型別,也就是說當WeakHashMap 中的某個鍵不再正常使用時,會被從WeakHashMap中被自己主動移除。WeakHashMap也不是執行緒安全的,僅僅適用於單執行緒。
(03) Hashtable也是雜湊表。和HashMap不同的是。Hashtable是執行緒安全的,支援併發。
(04) TreeMap也是雜湊表。只是TreeMap中的“鍵-值對”是有序的,它是通過R-B Tree(紅黑樹)實現的;TreeMap不是執行緒安全的。僅僅適用於單執行緒。
1. List和Set
JUC集合包中的List和Set實現類包含: CopyOnWriteArrayList, CopyOnWriteArraySet和ConcurrentSkipListSet。
ConcurrentSkipListSet稍後在說明Map時再說明,CopyOnWriteArrayList 和 CopyOnWriteArraySet的框架例如以下圖所看到的:
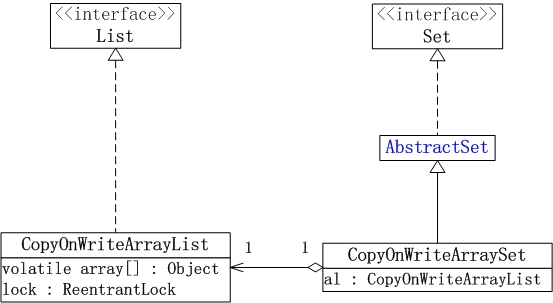
(01) CopyOnWriteArrayList相當於執行緒安全的ArrayList。它實現了List介面。
CopyOnWriteArrayList是支援高併發的。
(02) CopyOnWriteArraySet相當於執行緒安全的HashSet,它繼承於AbstractSet類。CopyOnWriteArraySet內部包括一個CopyOnWriteArrayList物件,它是通過CopyOnWriteArrayList實現的。
2. Map
JUC集合包中Map的實現類包含: ConcurrentHashMap和ConcurrentSkipListMap。它們的框架例如以下圖所看到的:

(01) ConcurrentHashMap是執行緒安全的雜湊表(相當於執行緒安全的HashMap)。它繼承於AbstractMap類。而且實現ConcurrentMap介面。ConcurrentHashMap是通過“鎖分段”來實現的,它支援併發。
(02) ConcurrentSkipListMap是執行緒安全的有序的雜湊表(相當於執行緒安全的TreeMap); 它繼承於AbstractMap類,而且實現ConcurrentNavigableMap介面。
ConcurrentSkipListMap是通過“跳錶”來實現的,它支援併發。
(03) ConcurrentSkipListSet是執行緒安全的有序的集合(相當於執行緒安全的TreeSet)。它繼承於AbstractSet,並實現了NavigableSet介面。ConcurrentSkipListSet是通過ConcurrentSkipListMap實現的。它也支援併發。
3. Queue
JUC集合包中Queue的實現類包含: ArrayBlockingQueue, LinkedBlockingQueue, LinkedBlockingDeque, ConcurrentLinkedQueue和ConcurrentLinkedDeque。
它們的框架例如以下圖所看到的:
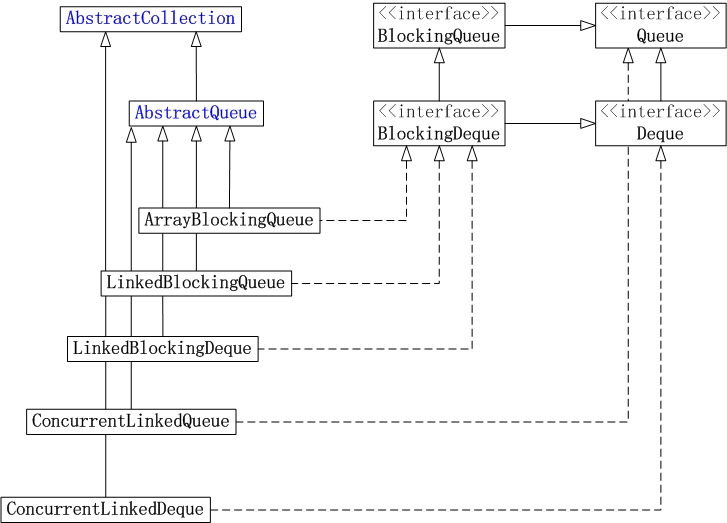
(01) ArrayBlockingQueue是陣列實現的執行緒安全的有界的堵塞佇列。
(02) LinkedBlockingQueue是單向連結串列實現的(指定大小)堵塞佇列。該佇列按 FIFO(先進先出)排序元素。
(03) LinkedBlockingDeque是雙向連結串列實現的(指定大小)雙向併發堵塞佇列,該堵塞佇列同一時候支援FIFO和FILO兩種操作方式。
(04) ConcurrentLinkedQueue是單向連結串列實現的無界佇列。該佇列按 FIFO(先進先出)排序元素。
(05) ConcurrentLinkedDeque是雙向連結串列實現的無界佇列,該佇列同一時候支援FIFO和FILO兩種操作方式。
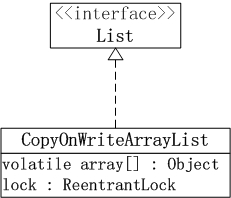
CopyOnWriteArrayList
CopyOnWriteArrayList與ArrayList相比具有的特性例如以下:
1.
它最適合於具有下面特徵的應用程式:List 大小通常保持非常小,僅僅讀操作遠多於可變操作,須要在遍歷期間防止執行緒間的衝突。
2. 它是執行緒安全的。
3. 由於通常須要複製整個基礎陣列,所以可變操作(add()、set() 和 remove() 等等)的開銷非常大。
4. 迭代器支援hasNext(), next()等不可變操作,但不支援可變 remove()等操作。
5. 使用迭代器進行遍歷的速度非常快,而且不會與其它執行緒發生衝突。在構造迭代器時,迭代器依賴於不變的陣列快照。
// 建立一個空列表。 CopyOnWriteArrayList() // 建立一個按 collection 的迭代器返回元素的順序包括指定 collection 元素的列表。 CopyOnWriteArrayList(Collection<?extends E> c) // 建立一個儲存給定陣列的副本的列表。
CopyOnWriteArrayList(E[] toCopyIn)// 將指定元素加入到此列表的尾部。 boolean add(E e) // 在此列表的指定位置上插入指定元素。 void add(int index, E element) // 依照指定 collection 的迭代器返回元素的順序,將指定 collection 中的全部元素加入此列表的尾部。 boolean addAll(Collection<?extends E> c) // 從指定位置開始,將指定 collection 的全部元素插入此列表。 boolean addAll(int index, Collection<? extends E> c) // 依照指定 collection 的迭代器返回元素的順序,將指定 collection 中尚未包括在此列表中的全部元素加入列表的尾部。
int addAllAbsent(Collection<? extends E> c) // 加入元素(假設不存在)。 boolean addIfAbsent(E e) // 從此列表移除全部元素。 void clear() // 返回此列表的淺表副本。 Object clone() // 假設此列表包括指定的元素。則返回 true。 boolean contains(Object o) // 假設此列表包括指定 collection 的全部元素。則返回 true。
boolean containsAll(Collection<?> c) // 比較指定物件與此列表的相等性。 boolean equals(Object o) // 返回列表中指定位置的元素。 E get(int index) // 返回此列表的雜湊碼值。 int hashCode() // 返回第一次出現的指定元素在此列表中的索引。從 index 開始向前搜尋,假設沒有找到該元素,則返回 -1。 int indexOf(E e, int index) // 返回此列表中第一次出現的指定元素的索引。假設此列表不包括該元素,則返回 -1。
int indexOf(Object o) // 假設此列表不包括不論什麼元素,則返回 true。 boolean isEmpty() // 返回以恰當順序在此列表元素上進行迭代的迭代器。 Iterator<E> iterator() // 返回最後一次出現的指定元素在此列表中的索引,從 index 開始向後搜尋,假設沒有找到該元素,則返回 -1。 int lastIndexOf(E e, int index) // 返回此列表中最後出現的指定元素的索引。假設列表不包括此元素,則返回 -1。 int lastIndexOf(Object o) // 返回此列表元素的列表迭代器(按適當順序)。 ListIterator<E> listIterator() // 返回列表中元素的列表迭代器(按適當順序),從列表的指定位置開始。 ListIterator<E> listIterator(int index) // 移除此列表指定位置上的元素。
E remove(int index) // 從此列表移除第一次出現的指定元素(假設存在)。
boolean remove(Object o) // 從此列表移除全部包括在指定 collection 中的元素。
boolean removeAll(Collection<?> c) // 僅僅保留此列表中包括在指定 collection 中的元素。 boolean retainAll(Collection<?> c) // 用指定的元素替代此列表指定位置上的元素。
E set(int index, E element) // 返回此列表中的元素數。 int size() // 返回此列表中 fromIndex(包括)和 toIndex(不包括)之間部分的檢視。 List<E> subList(int fromIndex, int toIndex) // 返回一個按恰當順序(從第一個元素到最後一個元素)包括此列表中全部元素的陣列。
Object[] toArray() // 返回以恰當順序(從第一個元素到最後一個元素)包括列表全部元素的陣列;返回陣列的執行時型別是指定陣列的執行時型別。 <T> T[] toArray(T[] a) // 返回此列表的字串表示形式。 String toString()
CopyOnWriteArraySet
CopyOnWriteArraySet和HashSet一樣都繼承了AbstractSet,可是HashSet是通過雜湊表HashMap來實現的。而CopyOnWriteArraySet是通過動態陣列CopyOnWriteArrayList來實現的。
所以CopyOnWriteArraySet和CopyOnWriteArrayList一樣有例如以下特性:
1. 它最適合於具有下面特徵的應用程式:List 大小通常保持非常小,僅僅讀操作遠多於可變操作,須要在遍歷期間防止執行緒間的衝突。
2. 它是執行緒安全的。
3. 由於通常須要複製整個基礎陣列,所以可變操作(add()、set() 和 remove() 等等)的開銷非常大。
4. 迭代器支援hasNext(), next()等不可變操作,但不支援可變 remove()等操作。
5. 使用迭代器進行遍歷的速度非常快,而且不會與其它執行緒發生衝突。在構造迭代器時。迭代器依賴於不變的陣列快照。

2. CopyOnWriteArraySet包括CopyOnWriteArrayList物件,它是通過CopyOnWriteArrayList實現的。而CopyOnWriteArrayList本質是個動態陣列佇列,所以CopyOnWriteArraySet相當於通過通過動態陣列實現的“集合”!
CopyOnWriteArrayList中同意有反覆的元素。可是。CopyOnWriteArraySet是一個集合。它不能有反覆集合。
因此。CopyOnWriteArrayList額外提供了addIfAbsent()和addAllAbsent()這兩個加入元素的API,通過這些API來加入元素時。僅僅有當元素不存在時才執行加入操作。
// 建立一個空 set。 CopyOnWriteArraySet() // 建立一個包括指定 collection 全部元素的 set。 CopyOnWriteArraySet(Collection<? extends E> c) // 假設指定元素並不存在於此 set 中。則加入它。 boolean add(E e) // 假設此 set 中沒有指定 collection 中的全部元素,則將它們都加入到此 set 中。 boolean addAll(Collection<? extends E> c) // 移除此 set 中的全部元素。 void clear() // 假設此 set 包括指定元素,則返回 true。 boolean contains(Object o) // 假設此 set 包括指定 collection 的全部元素。則返回 true。 boolean containsAll(Collection<?> c) // 比較指定物件與此 set 的相等性。 boolean equals(Object o) // 假設此 set 不包括不論什麼元素。則返回 true。 boolean isEmpty() // 返回依照元素加入順序在此 set 中包括的元素上進行迭代的迭代器。
Iterator<E> iterator() // 假設指定元素存在於此 set 中,則將其移除。 boolean remove(Object o) // 移除此 set 中包括在指定 collection 中的全部元素。
boolean removeAll(Collection<?> c) // 僅保留此 set 中那些包括在指定 collection 中的元素。 boolean retainAll(Collection<?> c) // 返回此 set 中的元素數目。 int size() // 返回一個包括此 set 全部元素的陣列。 Object[] toArray() // 返回一個包括此 set 全部元素的陣列。返回陣列的執行時型別是指定陣列的型別。 <T> T[] toArray(T[] a)
多執行緒對同一個片段的訪問。是相互排斥的;可是,對於不同片段的訪問,卻是能夠同步進行的。
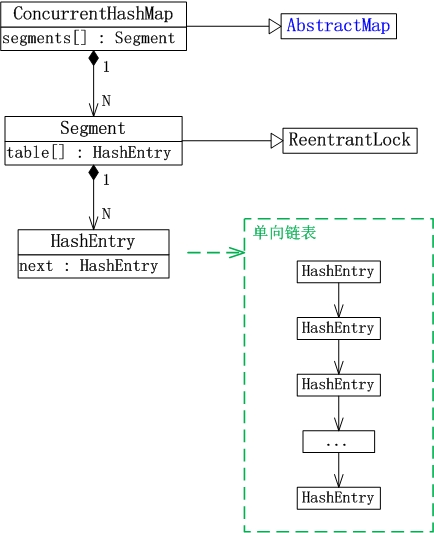

(01) ConcurrentHashMap繼承於AbstractMap抽象類。
(02) Segment是ConcurrentHashMap中的內部類。它就是ConcurrentHashMap中的“鎖分段”相應的儲存結構。ConcurrentHashMap與Segment是組合關係。1個ConcurrentHashMap物件包括若干個Segment物件。在程式碼中。這表現為ConcurrentHashMap類中存在“Segment陣列”成員。
(03) Segment類繼承於ReentrantLock類。所以Segment本質上是一個可重入的相互排斥鎖。
(04) HashEntry也是ConcurrentHashMap的內部類。是單向連結串列節點,儲存著key-value鍵值對。Segment與HashEntry是組合關係,Segment類中存在“HashEntry陣列”成員,“HashEntry陣列”中的每一個HashEntry就是一個單向連結串列。
對於多執行緒訪問對一個“雜湊表物件”競爭資源。Hashtable是通過一把鎖來控制併發。而ConcurrentHashMap則是將雜湊表分成很多片段。對於每個片段分別通過一個相互排斥鎖來控制併發。
ConcurrentHashMap對併發的控制更加細膩,它也更加適應於高併發場景。
ConcurrentHashMap的原始碼:
ConcurrentHashMap相關屬性:
/** * 用於分段 */ // 依據這個數來計算segment的個數,segment的個數是僅小於這個數且是2的幾次方的一個數(ssize) static final int DEFAULT_CONCURRENCY_LEVEL = 16; // 最大的分段(segment)數(2的16次方) static final int MAX_SEGMENTS = 1 << 16; /** * 用於HashEntry */ // 預設的用於計算Segment陣列中的每個segment的HashEntry[]的容量,可是並非每個segment的HashEntry[]的容量 static final int DEFAULT_INITIAL_CAPACITY = 16; // 預設的載入因子(用於resize) static final float DEFAULT_LOAD_FACTOR = 0.75f; // 用於計算Segment陣列中的每個segment的HashEntry[]的最大容量(2的30次方) static final int MAXIMUM_CAPACITY = 1 << 30; /** * segments陣列 * 每個segment元素都看做是一個HashTable */ final Segment<K, V>[] segments; /** * 用於擴容 */ final int segmentMask;// 用於依據給定的key的hash值定位到一個Segment final int segmentShift;// 用於依據給定的key的hash值定位到一個SegmentSegment類(ConcurrentHashMap的內部類):
/** * 一個特殊的HashTable */ static final class Segment<K, V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; transient volatile int count;// 該Segment中的包括的全部HashEntry中的key-value的個數 transient int modCount;// 併發標記 /* * 元素個數超出了這個值就擴容 threshold==(int)(capacity * loadFactor) * 值得注意的是,僅僅是當前的Segment擴容,所以這是Segment自己的一個變數,而不是ConcurrentHashMap的 */ transient int threshold; transient volatile HashEntry<K, V>[] table;// 連結串列陣列 final float loadFactor; /** * 這裡要注意一個非常不好的程式設計習慣,就是小寫l,easy與數字1混淆,所以最好不要用小寫l。能夠改為大寫L */ Segment(int initialCapacity, float lf) { loadFactor = lf;//每一個Segment的載入因子 setTable(HashEntry.<K, V> newArray(initialCapacity)); } /** * 建立一個Segment陣列,容量為i */ @SuppressWarnings("unchecked") static final <K, V> Segment<K, V>[] newArray(int i) { return new Segment[i]; } /** * Sets table to new HashEntry array. Call only while holding lock or in * constructor. */ void setTable(HashEntry<K, V>[] newTable) { threshold = (int) (newTable.length * loadFactor);// 設定擴容值 table = newTable;// 設定連結串列陣列 }HashEntry類(ConcurrentHashMap的內部類):
/** * Segment中的HashEntry節點 類比HashMap中的Entry節點 */ static final class HashEntry<K, V> { final K key;// 鍵 final int hash;//hash值 volatile V value;// 實現執行緒可見性 final HashEntry<K, V> next;// 下一個HashEntry HashEntry(K key, int hash, HashEntry<K, V> next, V value) { this.key = key; this.hash = hash; this.next = next; this.value = value; } /* * 建立HashEntry陣列。容量為傳入的i */ @SuppressWarnings("unchecked") static final <K, V> HashEntry<K, V>[] newArray(int i) { return new HashEntry[i]; } }ConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel):
1 /** 2 * 建立ConcurrentHashMap 3 * @param initialCapacity 用於計算Segment陣列中的每個segment的HashEntry[]的容量。 可是並非每個segment的HashEntry[]的容量 4 * @param loadFactor 5 * @param concurrencyLevel 用於計算Segment陣列的大小(能夠傳入不是2的幾次方的數,可是依據下邊的計算,終於segment陣列的大小ssize將是2的幾次方的數) 6 * 7 * 步驟: 8 * 這裡以預設的無參構造器引數為例,initialCapacity==16,loadFactor==0.75f,concurrencyLevel==16 9 * 1)檢查各引數是否符合要求 10 * 2)依據concurrencyLevel(16),計算Segment[]的容量ssize(16)與擴容移位條件sshift(4) 11 * 3)依據sshift與ssize計算將來用於定位到對應Segment的引數segmentShift與segmentMask 12 * 4)依據ssize建立Segment[]陣列,容量為ssize(16) 13 * 5)依據initialCapacity(16)與ssize計算用於計算HashEntry[]容量的引數c(1) 14 * 6)依據c計算HashEntry[]的容量cap(1) 15 * 7)依據cap與loadFactor(0.75)為每個Segment[i]都例項化一個Segment 16 * 8)每個Segment的例項化都做以下這些事兒: 17 * 8.1)為當前的Segment初始化其loadFactor為傳入的loadFactor(0.75) 18 * 8.2)建立一個HashEntry[]。容量為傳入的cap(1) 19 * 8.3)依據建立出來的HashEntry的容量(1)和初始化的loadFactor(0.75),計算擴容因子threshold(0) 20 * 8.4)初始化Segment的table為剛剛建立出來的HashEntry 21 */ 22 public ConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel) { 23 // 檢查引數情況 24 if (loadFactor <= 0f || initialCapacity < 0 || concurrencyLevel <= 0) 25 throw new IllegalArgumentException(); 26 27 if (concurrencyLevel > MAX_SEGMENTS) 28 concurrencyLevel = MAX_SEGMENTS; 29 30 /** 31 * 找一個能夠正好小於concurrencyLevel的數(這個數必須是2的幾次方的數) 32 * eg.concurrencyLevel==16==>sshift==4,ssize==16 33 * 當然,假設concurrencyLevel==15也是上邊這個結果 34 */ 35 int sshift = 0; 36 int ssize = 1;// segment陣列的長度 37 while (ssize < concurrencyLevel) { 38 ++sshift; 39 ssize <<= 1;// ssize=ssize*2 40 } 41 42 segmentShift = 32 - sshift;// eg.segmentShift==32-4=28 用於依據給定的key的hash值定位到一個Segment 43 segmentMask = ssize - 1;// eg.segmentMask==16-1==15 用於依據給定的key的hash值定位到一個Segment 44 this.segments = Segment.newArray(ssize);// 構造出了Segment[ssize]陣列 eg.Segment[16] 45 46 /* 47 * 以下將為segment陣列中加入Segment元素 48 */ 49 if (initialCapacity > MAXIMUM_CAPACITY) 50 initialCapacity = MAXIMUM_CAPACITY; 51 int c = initialCapacity / ssize;// eg.initialCapacity==16,c==16/16==1 52 if (c * ssize < initialCapacity)// eg.initialCapacity==17,c==17/16=1,這時1*16<17,所以c=c+1==2 53 ++c;// 為了少執行這一句。最好將initialCapacity設定為2的幾次方 54 int cap = 1;// 每個Segment中的HashEntry[]的初始化容量 55 while (cap < c) 56 cap <<= 1;// 建立容量 57 58 for (int i = 0; i < this.segments.length; ++i) 59 // 這一塊this.segments.length就是ssize。為了不去計算這個值,能夠直接改成i<ssize 60 this.segments[i] = new Segment<K, V>(cap, loadFactor); 61 }ConcurrentHashMap():
/** * 建立ConcurrentHashMap */ public ConcurrentHashMap() { this(DEFAULT_INITIAL_CAPACITY, // 16 DEFAULT_LOAD_FACTOR, // 0.75f DEFAULT_CONCURRENCY_LEVEL);// 16 }
- 傳入的concurrencyLevel僅僅是用於計算Segment陣列的大小(能夠傳入不是2的幾次方的數。可是依據下邊的計算,終於segment陣列的大小ssize將是2的幾次方的數)。並非真正的Segment陣列的大小
- 傳入的initialCapacity僅僅是用於計算Segment陣列中的每個segment的HashEntry[]的容量, 可是並非每個segment的HashEntry[]的容量,而每個HashEntry[]的容量不是2的幾次方
- 很值得注意的是。在預設情況下。建立出的HashEntry[]陣列的容量為1。並非傳入的initialCapacity(16)。證實了上一點。而每個Segment的擴容因子threshold,一開始算出來是0。即開始put第一個元素就要擴容,不太理解JDK為什麼這樣做。
- 想要在初始化時擴大HashEntry[]的容量,能夠指定initialCapacity引數,且指定時最好指定為2的幾次方的一個數,這種話。在程式碼執行中可能會少執行一句"c++",詳細參看三參構造器的凝視
- 對於Concurrenthashmap的擴容而言,僅僅會擴當前的Segment,而不是整個Concurrenthashmap中的全部Segment都擴
/** * 往當前segment中加入key-value * 注意: * 1)onlyIfAbsent-->false假設有舊值存在,新值覆蓋舊值,返回舊值;true假設有舊值存在,則直接返回舊值,相當於不加入元素(不可加入反覆key的元素) * 2)ReentrantLock的使用方法 * 3)volatile僅僅能配合鎖去使用才幹實現原子性 */ V put(K key, int hash, V value, boolean onlyIfAbsent) { lock();//加鎖:ReentrantLock try { int c = count;//當前Segment中的key-value對(注意:因為count是volatile型的。所以讀的時候工作記憶體會從主記憶體又一次載入count值) if (c++ > threshold) // 須要擴容 rehash();//擴容 HashEntry<K, V>[] tab = table; int index = hash & (tab.length - 1);//按位與獲取陣列下標:與HashMap同樣 HashEntry<K, V> first = tab[index];//獲取對應的HashEntry[i]中的頭節點 HashEntry<K, V> e = first; //一直遍歷到與插入節點的hash和key同樣的節點e。若沒有,最後e==null while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue;//舊值 if (e != null) {//table中已經有與將要插入節點同樣hash和key的節點 oldValue = e.value;//獲取舊值 if (!onlyIfAbsent) e.value = value;//false 覆蓋舊值 true的話,就不加入元素了 } else {//table中沒有與將要插入節點同樣hash或key的節點 oldValue = null; ++modCount; tab[index] = new HashEntry<K, V>(key, hash, first, value);//將頭節點作為新節點的next,所以新加入的元素也是加入在鏈頭 count = c; //設定key-value對(注意:因為count是volatile型的,所以寫的時候工作記憶體會馬上向主記憶體又一次寫入count值) } return oldValue; } finally { unlock();//手工釋放鎖 } }rehash():
/** * 步驟: * 須要注意的是:同一個桶下邊的HashEntry連結串列中的每個元素的hash值不一定同樣。僅僅是hash&(table.length-1)的結果同樣 * 1)建立一個新的HashEntry陣列,容量為舊陣列的二倍 * 2)計算新的threshold * 3)遍歷舊陣列的每個元素。對於每個元素 * 3.1)依據頭節點e又一次計算將要存入的新陣列的索引idx * 3.2)若整個連結串列僅僅有一個節點e,則是直接將e賦給newTable[idx]就可以 * 3.3)若整個連結串列還有其它節點,先算出最後一個節點lastRun的位置lastIdx。並將最後一個節點賦值給newTable[lastIdx] * 3.4)最後將從頭節點開始到最後一個節點之前的全部節點計算其將要儲存的索引k,然後建立新節點,將新節點賦給newTable[k],並將之前newTable[k]上存在的節點作為新節點的下一節點 */ void rehash() { HashEntry<K, V>[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity >= MAXIMUM_CAPACITY) return; HashEntry<K, V>[] newTable = HashEntry.newArray(oldCapacity << 1);//擴容為原來二倍 threshold = (int) (newTable.length * loadFactor);//計算新的擴容臨界值 int sizeMask = newTable.length - 1; for (int i = 0; i < oldCapacity; i++) { // We need to guarantee that any existing reads of old Map can // proceed. So we cannot yet null out each bin. HashEntry<K, V> e = oldTable[i];//頭節點 if (e != null) { HashEntry<K, V> next = e.next; int idx = e.hash & sizeMask;//又一次按位與計算將要存放的新陣列中的索引 if (next == null)//假設是僅僅有一個頭節點,僅僅需將頭節點設定到newTable[idx]就可以 newTable[idx] = e; else { // Reuse trailing consecutive sequence at same slot HashEntry<K, V> lastRun = e; int lastIdx = idx;//存放最後一個元素將要儲存的陣列索引 //查詢到最後一個元素,並設定相關資訊 for (HashEntry<K, V> last = next; last != null; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun;//存放最後一個元素 // Clone all remaining nodes for (HashEntry<K, V> p = e; p != lastRun; p = p.next) { int k = p.hash & sizeMask; HashEntry<K, V> n = newTable[k];//獲取newTable[k]已經存在的HashEntry,並將此HashEntry賦給n //建立新節點,並將之前的n作為新節點的下一節點 newTable[k] = new HashEntry<K, V>(p.key, p.hash, n,p.value); } } } } table = newTable; }Segment的get(Object key, int hash):
/** * 依據key和hash值獲取value */ V get(Object key, int hash) { if (count != 0) { // read-volatile HashEntry<K, V> e = getFirst(hash);//找到HashEntry[index] while (e != null) {//遍歷整個連結串列 if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) return v; /* * 假設V等於null,有可能是當下的這個HashEntry剛剛被建立。value屬性還沒有設定成功, * 這時候我們讀到是該HashEntry的value的預設值null,所以這裡加鎖。等待put結束後,返回value值 */ return readValueUnderLock(e); } e = e.next; } } return null; }Segment的remove(Object key, int hash, Object value):
V remove(Object key, int hash, Object value) { lock(); try { int c = count - 1;//key-value對個數-1 HashEntry<K, V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K, V> first = tab[index];//獲取將要刪除的元素所在的HashEntry[index] HashEntry<K, V> e = first; //從頭節點遍歷到最後,若未找到相關的HashEntry。e==null,否則,有 while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue = null; if (e != null) {//將要刪除的節點e V v = e.value; if (value == null || value.equals(v)) { oldValue = v; // All entries following removed node can stay // in list, but all preceding ones need to be // cloned. ++modCount; HashEntry<K, V> newFirst = e.next; /* * 從頭結點遍歷到e節點,這裡將e節點刪除了,可是刪除節點e的前邊的節點會倒序 * eg.原本的順序:E3-->E2-->E1-->E0,刪除E1節點後的順序為:E2-->E3-->E0 * E1前的節點倒序排列了 */ for (HashEntry<K, V> p = first; p != e; p = p.next) newFirst = new HashEntry<K, V>(p.key, p.hash, newFirst, p.value); tab[index] = newFirst; count = c; // write-volatile } } return oldValue; } finally { unlock(); } }
對於ConcurrentHashMap的加入,刪除操作。在操作開始前,執行緒都會獲取Segment的相互排斥鎖;操作完成之後,才會釋放。
而對於讀取操作。它是通過volatile去實現的,HashEntry陣列是volatile型別的。而volatile能保證“即對一個volatile變數的讀。總是能看到(隨意執行緒)對這個volatile變數最後的寫入”,即我們總能讀到其他執行緒寫入HashEntry之後的值。
以上這些方式。就是ConcurrentHashMap執行緒安全的實現原理。
ArrayBlockingQueue是陣列實現的執行緒安全的有界的堵塞佇列。
執行緒安全是指。ArrayBlockingQueue內部通過“相互排斥鎖”保護競爭資源。實現了多執行緒對競爭資源的相互排斥訪問。
而有界,則是指ArrayBlockingQueue相應的陣列是有界限的。
堵塞佇列,是指多執行緒訪問競爭資源時。當競爭資源已被某執行緒獲取時。其他要獲取該資源的執行緒須要堵塞等待;並且。ArrayBlockingQueue是按 FIFO(先進先出)原則對元素進行排序,元素都是從尾部插入到佇列,從頭部開始返回。
注意:ArrayBlockingQueue不同於ConcurrentLinkedQueue。ArrayBlockingQueue是陣列實現的。而且是有界限的。必須指定佇列大小;而ConcurrentLinkedQueue是連結串列實現的,是無界限的。
ArrayBlockingQueue的原理和資料結構以及原始碼:
private final E[] items;//底層資料結構 private int takeIndex;//用來為下一個take/poll/remove的索引(出隊) private int putIndex;//用來為下一個put/offer/add的索引(入隊) private int count;//佇列中元素的個數 /* * Concurrency control uses the classic two-condition algorithm found in any * textbook. */ /** Main lock guarding all access */ private final ReentrantLock lock;//鎖 /** Condition for waiting takes */ private final Condition notEmpty;//等待出隊的條件 /** Condition for waiting puts */ private final Condition notFull;//等待入隊的條件
/** * 創造一個佇列,指定佇列容量。指定模式 * @param fair * true:先來的執行緒先操作 * false:順序隨機 */ public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = (E[]) new Object[capacity];//初始化類變數陣列items lock = new ReentrantLock(fair);//初始化類變數鎖lock notEmpty = lock.newCondition();//初始化類變數notEmpty Condition notFull = lock.newCondition();//初始化類變數notFull Condition } /** * 創造一個佇列。指定佇列容量。預設模式為非公平模式 * @param capacity <1會拋異常 */ public ArrayBlockingQueue(int capacity) { this(capacity, false); }說明:
1. ArrayBlockingQueue繼承於AbstractQueue,而且它實現了BlockingQueue介面。
2. ArrayBlockingQueue內部是通過Object[]陣列儲存資料的。也就是說ArrayBlockingQueue本質上是通過陣列實現的。ArrayBlockingQueue的大小,即陣列的容量是建立ArrayBlockingQueue時指定的。
3. ArrayBlockingQueue與ReentrantLock是組合關係。ArrayBlockingQueue中包括一個ReentrantLock物件(lock)。ReentrantLock是可重入的相互排斥鎖,ArrayBlockingQueue就是依據該相互排斥鎖實現“多執行緒對競爭資源的相互排斥訪問”。並且,ReentrantLock分為公平鎖和非公平鎖。關於詳細使用公平鎖還是非公平鎖,在建立ArrayBlockingQueue時能夠指定。並且,ArrayBlockingQueue預設會使用非公平鎖。
4. ArrayBlockingQueue與Condition是組合關係。ArrayBlockingQueue中包括兩個Condition物件(notEmpty和notFull)。並且。Condition又依賴於ArrayBlockingQueue而存在,通過Condition能夠實現對ArrayBlockingQueue的更精確的訪問 --(01)若某執行緒(執行緒A)要取資料時,陣列正好為空,則該執行緒會執行notEmpty.await()進行等待;當其他某個執行緒(執行緒B)向陣列中插入了資料之後,會呼叫notEmpty.signal()喚醒“notEmpty上的等待執行緒”。
此時,執行緒A會被喚醒從而得以繼續執行。
此時,執行緒H就會被喚醒從而得以繼續執行。
// 建立一個帶有給定的(固定)容量和預設訪問策略的 ArrayBlockingQueue。 ArrayBlockingQueue(int capacity) // 建立一個具有給定的(固定)容量和指定訪問策略的 ArrayBlockingQueue。 ArrayBlockingQueue(int capacity, boolean fair) // 建立一個具有給定的(固定)容量和指定訪問策略的 ArrayBlockingQueue。它最初包括給定 collection 的元素,並以 collection 迭代器的遍歷順序加入元素。 ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) // 將指定的元素插入到此佇列的尾部(假設馬上可行且不會超過該佇列的容量),在成功時返回 true,假設此佇列已滿。則丟擲 IllegalStateException。 boolean add(E e) // 自己主動移除此佇列中的全部元素。 void clear() // 假設此佇列包括指定的元素,則返回 true。 boolean contains(Object o) // 移除此佇列中全部可用的元素,並將它們加入到給定 collection 中。 int drainTo(Collection<? super E> c) // 最多從此佇列中移除給定數量的可用元素,並將這些元素加入到給定 collection 中。 int drainTo(Collection<? super E> c, int maxElements) // 返回在此佇列中的元素上按適當順序進行迭代的迭代器。 Iterator<E> iterator() // 將指定的元素插入到此佇列的尾部(假設馬上可行且不會超過該佇列的容量),在成功時返回 true,假設此佇列已滿。則返回 false。 boolean offer(E e) // 將指定的元素插入此佇列的尾部。假設該佇列已滿。則在到達指定的等待時間之前等待可用的空間。 boolean offer(E e, long timeout, TimeUnit unit) // 獲取但不移除此佇列的頭;假設此佇列為空,則返回 null。 E peek() // 獲取並移除此佇列的頭,假設此佇列為空,則返回 null。 E poll() // 獲取並移除此佇列的頭部,在指定的等待時間前等待可用的元素(假設有必要)。 E poll(long timeout, TimeUnit unit) // 將指定的元素插入此佇列的尾部,假設該佇列已滿,則等待可用的空間。 void put(E e) // 返回在無堵塞的理想情況下(不存在記憶體或資源約束)此佇列能接受的其它元素數量。 int remainingCapacity() // 從此佇列中移除指定元素的單個例項(假設存在)。 boolean remove(Object o) // 返回此佇列中元素的數量。 int size() // 獲取並移除此佇列的頭部,在元素變得可用之前一直等待(假設有必要)。 E take() // 返回一個按適當順序包括此佇列中全部元素的陣列。 Object[] toArray() // 返回一個按適當順序包括此佇列中全部元素的陣列。返回陣列的執行時型別是指定陣列的執行時型別。 <T> T[] toArray(T[] a) // 返回此 collection 的字串表示形式。 String toString()
三種入隊對照:
- offer(E e):假設佇列沒滿,馬上返回true; 假設佇列滿了,馬上返回false-->不堵塞
- put(E e):假設佇列滿了,一直堵塞,直到陣列不滿了或者執行緒被中斷-->堵塞
- offer(E e, long timeout, TimeUnit unit):在隊尾插入一個元素,,假設陣列已滿。則進入等待,直到出現下面三種情況:-->堵塞
- 被喚醒
- 等待時間超時
- 當前執行緒被中斷
三種出對對照:
- poll():假設沒有元素。直接返回null;假設有元素,出隊
- take():假設佇列空了,一直堵塞。直到陣列不為空或者執行緒被中斷-->堵塞
- poll(long timeout, TimeUnit unit):假設陣列不空。出隊;假設陣列已空且已經超時,返回null;假設陣列已空且時間未超時。則進入等待,直到出現下面三種情況:
- 被喚醒
- 等待時間超時
- 當前執行緒被中斷
LinkedBlockingQueue是一個單向連結串列實現的堵塞佇列。
該佇列按 FIFO(先進先出)排序元素。新元素插入到佇列的尾部,而且佇列獲取操作會獲得位於佇列頭部的元素。連結佇列的吞吐量通常要高於基於陣列的佇列,可是在大多數併發應用程式中,其可預知的效能要低。
此外,LinkedBlockingQueue還是可選容量的(防止過度膨脹)。即能夠指定佇列的容量。假設不指定,預設容量大小等於Integer.MAX_VALUE。
LinkedBlockingQueue的原理和資料結構:
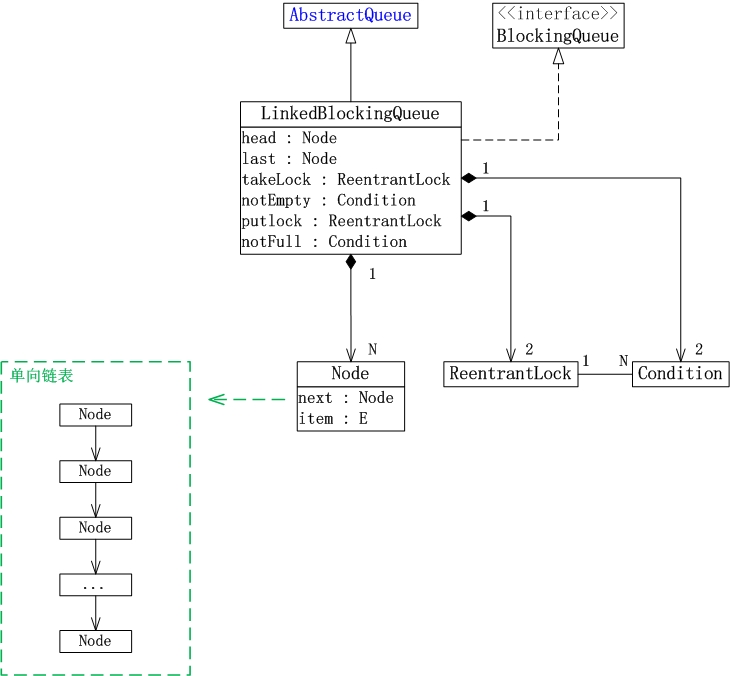
1. LinkedBlockingQueue繼承於AbstractQueue,它本質上是一個FIFO(先進先出)的佇列。
2. LinkedBlockingQueue實現了BlockingQueue介面。它支援多執行緒併發。當多執行緒競爭同一個資源時。某執行緒獲取到該資源之後。其他執行緒須要堵塞等待。
3. LinkedBlockingQueue是通過單連結串列實現的。
(01) head是連結串列的表頭。取出資料時。都是從表頭head處插入。
(02) last是連結串列的表尾。
新增資料時。都是從表尾last處插入。
(03) count是連結串列的實際大小,即當前連結串列中包括的節點個數。
(04) capacity是列表的容量。它是在建立連結串列時指定的。
(05) putLock是插入鎖,takeLock是取出鎖;notEmpty是“非空條件”。notFull是“未滿條件”。通過它們對連結串列進行併發控制。
LinkedBlockingQueue在實現“多執行緒對競爭資源的相互排斥訪問”時。對於“插入”和“取出(刪除)”操作分別使用了不同的鎖。對於插入操作。通過“插入鎖putLock”進行同步;對於取出操作。通過“取出鎖takeLock”進行同步。
此外,插入鎖putLock和“非滿條件notFull”相關聯,取出鎖takeLock和“非空條件notEmpty”相關聯。
通過notFull和notEmpty更細膩的控制鎖。
-- 若某執行緒(執行緒A)要取出資料時。佇列正好為空。則該執行緒會執行notEmpty.await()進行等待;當其他某個執行緒(執行緒B)向佇列中插入了資料之後,會呼叫notEmpty.signal()喚醒“notEmpty上的等待執行緒”。此時。執行緒A會被喚醒從而得以繼續執行。 此外。執行緒A在執行取操作前,會獲取takeLock,在取操作執行完成再釋放takeLock。
-- 若某執行緒(執行緒H)要插入資料時,佇列已滿,則該執行緒會它執行notFull.await()進行等待。當其他某個執行緒(執行緒I)取出資料之後,會呼叫notFull.signal()喚醒“notFull上的等待執行緒”。此時,執行緒H就會被喚醒從而得以繼續執行。 此外,執行緒H在執行插入操作前,會獲取putLock,在插入操作執行完成才釋放putLock。
// 建立一個容量為 Integer.MAX_VALUE 的 LinkedBlockingQueue。 LinkedBlockingQueue() // 建立一個容量是 Integer.MAX_VALUE 的 LinkedBlockingQueue。最初包括給定 collection 的元素。元素按該 collection 迭代器的遍歷順序加入。 LinkedBlockingQueue(Collection<?extends E> c) // 建立一個具有給定(固定)容量的 LinkedBlockingQueue。 LinkedBlockingQueue(int capacity) // 從佇列徹底移除全部元素。 void clear() // 移除此佇列中全部可用的元素。並將它們加入到給定 collection 中。 int drainTo(Collection<?
super E> c) // 最多從此佇列中移除給定數量的可用元素。並將這些元素加入到給定 collection 中。 int drainTo(Collection<?
super E> c, int maxElements) // 返回在佇列中的元素上按適當順序進行迭代的迭代器。
Iterator<E> iterator() // 將指定元素插入到此佇列的尾部(假設馬上可行且不會超出此佇列的容量),在成功時返回 true,假設此佇列已滿,則返回 false。
boolean offer(E e) // 將指定元素插入到此佇列的尾部。如有必要,則等待指定的時間以使空間變得可用。
boolean offer(E e, long timeout, TimeUnit unit) // 獲取但不移除此佇列的頭;假設此佇列為空,則返回 null。 E peek() // 獲取並移除此佇列的頭,假設此佇列為空,則返回 null。
E poll() // 獲取並移除此佇列的頭部,在指定的等待時間前等待可用的元素(假設有必要)。 E poll(long timeout, TimeUnit unit) // 將指定元素插入到此佇列的尾部,如有必要。則等待空間變得可用。 void put(E e) // 返回理想情況下(沒有記憶體和資源約束)此佇列可接受而且不會被堵塞的附加元素數量。 int remainingCapacity() // 從此佇列移除指定元素的單個例項(假設存在)。
boolean remove(Object o) // 返回佇列中的元素個數。 int size() // 獲取並移除此佇列的頭部。在元素變得可用之前一直等待(假設有必要)。 E take() // 返回按適當順序包括此佇列中全部元素的陣列。 Object[] toArray() // 返回按適當順序包括此佇列中全部元素的陣列;返回陣列的執行時型別是指定陣列的執行時型別。 <T> T[] toArray(T[] a) // 返回此 collection 的字串表示形式。 String toString()
三種入隊對照:
- offer(E e):假設佇列沒滿,馬上返回true; 假設佇列滿了,馬上返回false-->不堵塞
- put(E e):假設佇列滿了,一直堵塞。直到佇列不滿了或者執行緒被中斷-->堵塞
- offer(E e, long timeout, TimeUnit unit):在隊尾插入一個元素,,假設佇列已滿。則進入等待,直到出現下面三種情況:-->堵塞
- 被喚醒
- 等待時間超時
- 當前執行緒被中斷
三種出隊對照:
- poll():假設沒有元素,直接返回null;假設有元素,出隊
- take():假設佇列空了。一直堵塞,直到佇列不為空或者執行緒被中斷-->堵塞
- poll(long timeout, TimeUnit unit):假設佇列不空,出隊;假設佇列已空且已經超時,返回null;假設佇列已空且時間未超時。則進入等待,直到出現下面三種情況:
- 被喚醒
- 等待時間超時
- 當前執行緒被中斷
ArrayBlockingQueue與LinkedBlockingQueue對照:
- ArrayBlockingQueue:
- 一個物件陣列+一把鎖+兩個條件
- 入隊與出隊都用同一把鎖
- 在僅僅有入隊高併發或出隊高併發的情況下。由於運算元組,且不須要擴容,效能非常高
- 採用了陣列。必須指定大小,即容量有限
- LinkedBlockingQueue:
- 一個單向連結串列+兩把鎖+兩個條件
- 兩把鎖。一把用於入隊,一把用於出隊,有效的避免了入隊與出隊時使用一把鎖帶來的競爭。
- 在入隊與出隊都高併發的情況下,效能比ArrayBlockingQueue高非常多
- 採用了連結串列,最大容量為整數最大值。可看做容量無限
功能類似於:一直等待,來一個及時處理一個。但不能同一時候處理兩個。比方queue.take()方法會堵塞。queue.offer(element)插入一個元素,插入的元素立即就被queue.take()處理掉。
所以它沒有容納元素的能力,isEmpty方法總是返回true。可是給人的感覺像是能夠暫時容納一個元素。
平時非常少使用。可是線上程池的地方用到了該佇列。
SynchronousQueue支援2種策略:公平和非公平,默覺得非公平。
1) 公平策略:內部實現為TransferQueue,即一個佇列.(consumer和productor將會被佇列化)
2) 非公平策略:內部實現為TransferStack,即一個stack(內部模擬了一個單向連結串列。同意闖入行為)
內部實現比較複雜。雖然支援執行緒安全。可是其內部並沒有使用lock(其實無法使用lock)。使用了LockSupport來控制執行緒。使用CAS來控制棧的head遊標(非公平模式下)。
**********************************************未完待續*********************************************
該文為本人學習的筆記,方便以後自己查閱。參考網上各大帖子,取其精華整合自己的理解而成。
如有不正確的地方。請多多指正!自勉!
共勉!
**************************************************************************************************