原文地址:http://www.uml.org.cn/zjjs/201306263.asp
|
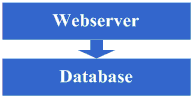
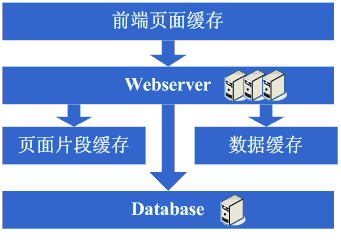
之前我簡單向大家介紹了各個知名大型網站的架構,億萬使用者網站MySpace的成功祕密、Flickr架構、YouTube網站架構、PlentyOfFish 網站架構學習、WikiPedia技術架構學習筆記。這幾個都很典型,我們可以從中獲取很多有關網站架構方面的知識,看了之後你會發現你原來的想法很可能是狹隘的。 今天我們來談談一個網站一般是如何一步步來構建起系統架構的,雖然我們希望網站一開始就能有一個很好的架構,但馬克思告訴我們事物是在發展中不斷前進的,網站架構也是隨著業務的擴大、使用者的需求不斷完善的,下面是一個網站架構逐步發展的基本過程,讀完後,請思考,你現在在哪個階段。 架構演變第一步:物理分離WebServer和資料庫 最開始,由於某些想法,於是在網際網路上搭建了一個網站,這個時候甚至有可能主機都是租借的,但由於這篇文章我們只關注架構的演變歷程,因此就假設這個時候已經是託管了一臺主機,並且有一定的頻寬了。這個時候由於網站具備了一定的特色,吸引了部分人訪問,逐漸你發現系統的壓力越來越高,響應速度越來越慢,而這個時候比較明顯的是資料庫和應用互相影響,應用出問題了,資料庫也很容易出現問題,而資料庫出問題的時候,應用也容易出問題。於是進入了第一步演變階段:將應用和資料庫從物理上分離,變成了兩臺機器,這個時候技術上沒有什麼新的要求,但你發現確實起到效果了,系統又恢復到以前的響應速度了,並且支撐住了更高的流量,並且不會因為資料庫和應用形成互相的影響。 看看這一步完成後系統的圖示:
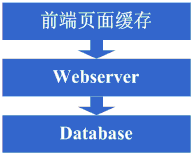
架構演變第二步:增加頁面快取 好景不長,隨著訪問的人越來越多,你發現響應速度又開始變慢了,查詢原因,發現是訪問資料庫的操作太多,導致資料連線競爭激烈,所以響應變慢。但資料庫連線又不能開太多,否則資料庫機器壓力會很高,因此考慮採用快取機制來減少資料庫連線資源的競爭和對資料庫讀的壓力。這個時候首先也許會選擇採用squid等類似的機制來將系統中相對靜態的頁面(例如一兩天才會有更新的頁面)進行快取(當然,也可以採用將頁面靜態化的方案),這樣程式上可以不做修改,就能夠很好的減少對WebServer的壓力以及減少資料庫連線資源的競爭,OK,於是開始採用squid來做相對靜態的頁面的快取。 看看這一步完成後系統的圖示:
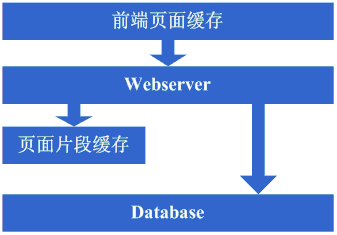
這一步涉及到了這些知識體系: 前端頁面快取技術,例如squid,如想用好的話還得深入掌握下squid的實現方式以及快取的失效演算法等。 架構演變第三步:增加頁面片段快取 增加了squid做快取後,整體系統的速度確實是提升了,WebServer的壓力也開始下降了,但隨著訪問量的增加,發現系統又開始變的有些慢了。在嚐到了squid之類的動態快取帶來的好處後,開始想能不能讓現在那些動態頁面裡相對靜態的部分也快取起來呢,因此考慮採用類似ESI之類的頁面片段快取策略,OK,於是開始採用ESI來做動態頁面中相對靜態的片段部分的快取。 看看這一步完成後系統的圖示:
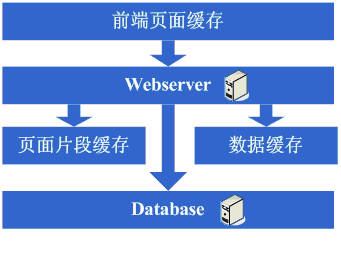
這一步涉及到了這些知識體系: 頁面片段快取技術,例如ESI等,想用好的話同樣需要掌握ESI的實現方式等; 架構演變第四步:資料快取 在採用ESI之類的技術再次提高了系統的快取效果後,系統的壓力確實進一步降低了,但同樣,隨著訪問量的增加,系統還是開始變慢。經過查詢,可能會發現系統中存在一些重複獲取資料資訊的地方,像獲取使用者資訊等,這個時候開始考慮是不是可以將這些資料資訊也快取起來呢,於是將這些資料快取到本地記憶體,改變完畢後,完全符合預期,系統的響應速度又恢復了,資料庫的壓力也再度降低了不少。 看看這一步完成後系統的圖示:
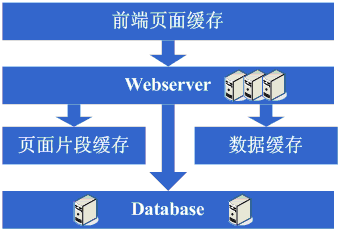
這一步涉及到了這些知識體系: 快取技術,包括像Map資料結構、快取演算法、所選用的框架本身的實現機制等。 架構演變第五步: 增加WebServer 好景不長,發現隨著系統訪問量的再度增加,webserver機器的壓力在高峰期會上升到比較高,這個時候開始考慮增加一臺webserver,這也是為了同時解決可用性的問題,避免單臺的webserver down機的話就沒法使用了,在做了這些考慮後,決定增加一臺webserver,增加一臺webserver時,會碰到一些問題,典型的有: 1、如何讓訪問分配到這兩臺機器上,這個時候通常會考慮的方案是Apache自帶的負載均衡方案,或LVS這類的軟體負載均衡方案; 2、如何保持狀態資訊的同步,例如使用者session等,這個時候會考慮的方案有寫入資料庫、寫入儲存、cookie或同步session資訊等機制等; 3、如何保持資料快取資訊的同步,例如之前快取的使用者資料等,這個時候通常會考慮的機制有快取同步或分散式快取; 4、如何讓上傳檔案這些類似的功能繼續正常,這個時候通常會考慮的機制是使用共享檔案系統或儲存等; 在解決了這些問題後,終於是把webserver增加為了兩臺,系統終於是又恢復到了以往的速度。 看這一步完成後系統的圖示:
這一步涉及到了這些知識體系: 負載均衡技術(包括但不限於硬體負載均衡、軟體負載均衡、負載演算法、linux轉發協議、所選用的技術的實現細節等)、主備技術(包括但不限於ARP欺騙、linuxheart-beat等)、狀態資訊或快取同步技術(包括但不限於Cookie技術、UDP協議、狀態資訊廣播、所選用的快取同步技術的實現細節等)、共享檔案技術(包括但不限於NFS等)、儲存技術(包括但不限於儲存裝置等)。 架構演變第六步:分庫 享受了一段時間的系統訪問量高速增長的幸福後,發現系統又開始變慢了,這次又是什麼狀況呢,經過查詢,發現資料庫寫入、更新的這些操作的部分資料庫連線的資源競爭非常激烈,導致了系統變慢,這下怎麼辦呢?此時可選的方案有資料庫叢集和分庫策略,叢集方面像有些資料庫支援的並不是很好,因此分庫會成為比較普遍的策略,分庫也就意味著要對原有程式進行修改,一通修改實現分庫後,不錯,目標達到了,系統恢復甚至速度比以前還快了。 看看這一步完成後系統的圖示:
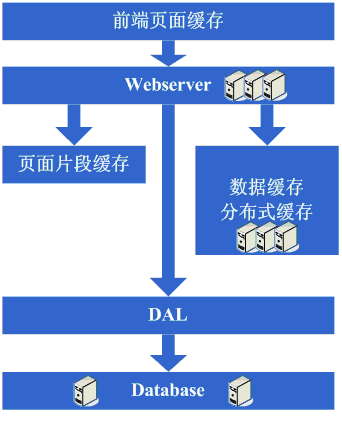
這一步涉及到了這些知識體系: 這一步更多的是需要從業務上做合理的劃分,以實現分庫,具體技術細節上沒有其他的要求;但同時隨著資料量的增大和分庫的進行,在資料庫的設計、調優以及維護上需要做的更好,因此對這些方面的技術還是提出了很高的要求的。 架構演變第七步:分表、DAL和分散式快取 隨著系統的不斷執行,資料量開始大幅度增長,這個時候發現分庫後查詢仍然會有些慢,於是按照分庫的思想開始做分表的工作。當然,這不可避免的會需要對程式進行一些修改,也許在這個時候就會發現應用自己要關心分庫分表的規則等,還是有些複雜的。於是萌生能否增加一個通用的框架來實現分庫分表的資料訪問,這個在ebay的架構中對應的就是DAL,這個演變的過程相對而言需要花費較長的時間。當然,也有可能這個通用的框架會等到分表做完後才開始做。同時,在這個階段可能會發現之前的快取同步方案出現問題,因為資料量太大,導致現在不太可能將快取存在本地,然後同步的方式,需要採用分散式快取方案了。於是,又是一通考察和折磨,終於是將大量的資料快取轉移到分散式快取上了。 看看這一步完成後系統的圖示:
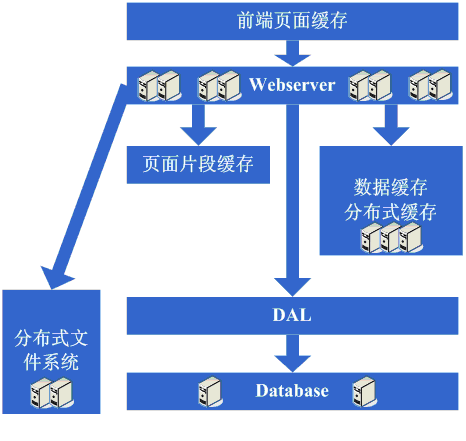
這一步涉及到了這些知識體系: 分表更多的同樣是業務上的劃分,技術上涉及到的會有動態hash演算法、consistenthash演算法等;DAL涉及到比較多的複雜技術,例如資料庫連線的管理(超時、異常)、資料庫操作的控制(超時、異常)、分庫分表規則的封裝等; 架構演變第八步:增加更多的WebServer 在做完分庫分表這些工作後,資料庫上的壓力已經降到比較低了,又開始過著每天看著訪問量暴增的幸福生活了。突然有一天,發現系統的訪問又開始有變慢的趨勢 了,這個時候首先檢視資料庫,壓力一切正常,之後檢視webserver,發現apache阻塞了很多的請求,而應用伺服器對每個請求也是比較快的,看來是請求數太高導致需要排隊等待,響應速度變慢。這還好辦,一般來說,這個時候也會有些錢了,於是新增一些webserver伺服器,在這個新增webserver伺服器的過程,有可能會出現幾種挑戰: 1、Apache的軟負載或LVS軟負載等無法承擔巨大的web訪問量(請求連線數、網路流量等)的排程了,這個時候如果經費允許的話,會採取的方案是購買硬體負載平衡裝置,例如F5、Netsclar、Athelon之類的,如經費不允許的話,會採取的方案是將應用從邏輯上做一定的分類,然後分散到不同的軟負載叢集中; 2、原有的一些狀態資訊同步、檔案共享等方案可能會出現瓶頸,需要進行改進,也許這個時候會根據情況編寫符合網站業務需求的分散式檔案系統等; 在做完這些工作後,開始進入一個看似完美的無限伸縮的時代,當網站流量增加時,應對的解決方案就是不斷的新增webserver。 看看這一步完成後系統的圖示:
這一步涉及到了這些知識體系: 了這一步,隨著機器數的不斷增長、資料量的不斷增長和對系統可用性的要求越來越高,這個時候要求對所採用的技術都要有更為深入的理解,並需要根據網站的需求來做更加定製性質的產品。 架構演變第九步:資料讀寫分離和廉價儲存方案 突然有一天,發現這個完美的時代也要結束了,資料庫的噩夢又一次出現在眼前了。由於新增的webserver太多了,導致資料庫連線的資源還是不夠用,而這個時候又已經分庫分表了,開始分析資料庫的壓力狀況,可能會發現資料庫的讀寫比很高,這個時候通常會想到資料讀寫分離的方案。當然,這個方案要實現並不容易,另外,可能會發現一些資料儲存在資料庫上有些浪費,或者說過於佔用資料庫資源,因此在這個階段可能會形成的架構演變是實現資料讀寫分離,同時編寫一些更為廉價的儲存方案,例如BigTable這種。 看看這一步完成後系統的圖示:
這一步涉及到了這些知識體系: 資料讀寫分離要求對資料庫的複製、standby等策略有深入的掌握和理解,同時會要求具備自行實現的技術;廉價儲存方案要求對OS的檔案儲存有深入的掌握和理解,同時要求對採用的語言在檔案這塊的實現有深入的掌握。 架構演變第十步:進入大型分散式應用時代和廉價伺服器群夢想時代 經過上面這個漫長而痛苦的過程,終於是再度迎來了完美的時代,不斷的增加webserver就可以支撐越來越高的訪問量了。對於大型網站而言,人氣的重要毋庸置疑,隨著人氣的越來越高,各種各樣的功能需求也開始爆發性的增長。這個時候突然發現,原來部署在webserver上的那個web應用已經非常龐大 了,當多個團隊都開始對其進行改動時,可真是相當的不方便,複用性也相當糟糕,基本是每個團隊都做了或多或少重複的事情,而且部署和維護也是相當的麻煩。因為龐大的應用包在N臺機器上覆制、啟動都需要耗費不少的時間,出問題的時候也不是很好查,另外一個更糟糕的狀況是很有可能會出現某個應用上的bug就導 致了全站都不可用,還有其他的像調優不好操作(因為機器上部署的應用什麼都要做,根本就無法進行鍼對性的調優)等因素,根據這樣的分析,開始痛下決心,將系統根據職責進行拆分,於是一個大型的分散式應用就誕生了,通常,這個步驟需要耗費相當長的時間,因為會碰到很多的挑戰: 1、拆成分散式後需要提供一個高效能、穩定的通訊框架,並且需要支援多種不同的通訊和遠端呼叫方式; 2、將一個龐大的應用拆分需要耗費很長的時間,需要進行業務的整理和系統依賴關係的控制等; 3、如何運維(依賴管理、執行狀況管理、錯誤追蹤、調優、監控和報警等)好這個龐大的分散式應用。 經過這一步,差不多系統的架構進入相對穩定的階段,同時也能開始採用大量的廉價機器來支撐著巨大的訪問量和資料量,結合這套架構以及這麼多次演變過程吸取的經驗來採用其他各種各樣的方法來支撐著越來越高的訪問量。 看看這一步完成後系統的圖示:
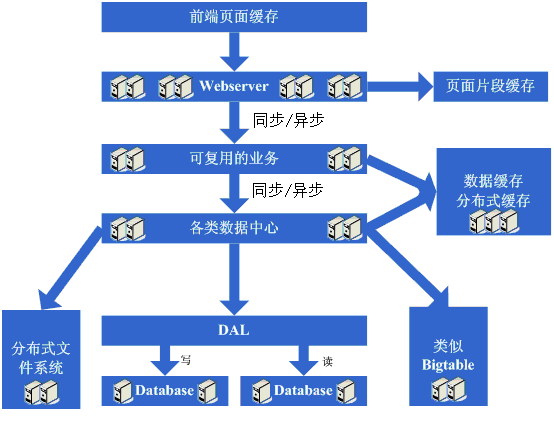
這一步涉及到了這些知識體系: 這一步涉及的知識體系非常的多,要求對通訊、遠端呼叫、訊息機制等有深入的理解和掌握,要求的都是從理論、硬體級、作業系統級以及所採用的語言的實現都有清楚的理解。 最後,附上一張大型網站的架構圖:
|