1729 單詞查詢樹
2000年NOI全國競賽
時間限制: 2 s
空間限制: 128000 KB
題目等級 : 大師 Master
題目描述 Description
在進行文法分析的時候,通常需要檢測一個單詞是否在我們的單詞列表裡。為了提高查詢和定位的速度,通常都要畫出與單詞列表所對應的單詞查詢樹,其特點如下:
l 根節點不包含字母,除根節點外每一個節點都僅包含一個大寫英文字母;
l 從根節點到某一節點,路徑上經過的字母依次連起來所構成的字母序列,稱為該節點對應的單詞。單詞列表中的每個詞,都是該單詞查詢樹某個節點所對應的單詞;
l 在滿足上述條件下,該單詞查詢樹的節點數最少。
對一個確定的單詞列表,請統計對應的單詞查詢樹的節點數(包括根節點)
輸入描述 Input Description
該檔案為一個單詞列表,每一行僅包含一個單詞和一個換行/回車符。每個單詞僅由大寫的英文字元組成,長度不超過63個字元。檔案總長度不超過32K,至少有一行資料。
輸出描述 Output Description
該檔案中僅包含一個整數和一個換行/回車符。該整數為單詞列表對應的單詞查詢樹的節點數。
樣例輸入 Sample Input
A
AN
ASP
AS
ASC
ASCII
BAS
BASIC
樣例輸出 Sample Output
13
資料範圍及提示 Data Size & Hint
分析:
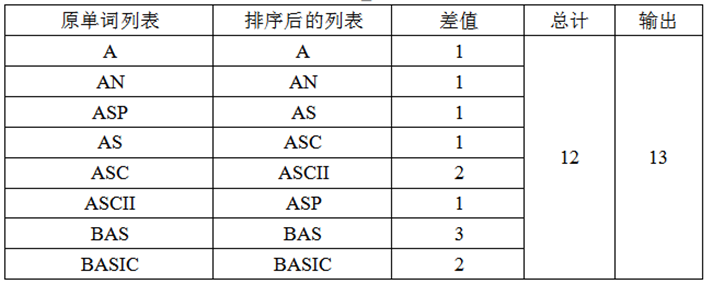
首先要對建樹的過程有一個瞭解。對於當前被處理的單詞和當前樹:在根結點的子結點中找單詞的第一位字母,若存在則進而在該結點的子結點中尋找第二位……如此下去直到單詞結束,即不需要在該樹中新增結點;或單詞的第n位不能被找到,即將單詞的第n位及其後的字母依次加入單詞查詢樹中去。但,本問題只是問你結點總數,而非建樹方案,且有32K檔案,所以應該考慮能不能不通過建樹就直接算出結點數?為了說明問題的本質,我們給出一個定義:一個單詞相對於另一個單詞的差:設單詞1的長度為L,且與單詞2從第N位開始不一致,則說單詞1相對於單詞2的差為L-N+1,這是描述單詞相似程度的量。可見,將一個單詞加入單詞樹的時候,須加入的結點數等於該單詞樹中已有單詞的差的最小值。
單詞的字典順序排列後的序列則具有類似的特性,即在一個字典順序序列中,第m個單詞相對於第m-1個單詞的差必定是它對於前m-1個單詞的差中最小的。於是,得出建樹的等效演算法:
① 讀入檔案;
② 對單詞列表進行字典順序排序;
③ 依次計算每個單詞對前一單詞的差,並把差累加起來。注意:第 一個單詞相對於“空”的差為該單詞的長度;
④ 累加和再加上1(根結點),輸出結果。
就給定的樣例,按照這個演算法求結點數的過程如下表:
1 #include<iostream> 2 #include<algorithm> 3 #include<cstdio> 4 #include<cstring> 5 using namespace std; 6 string a[10001]; 7 int tot=1; 8 int main() 9 { 10 int n=1; 11 while(cin>>a[n]) 12 n++; 13 sort(a+1,a+n+1); 14 int l=a[1].length(); 15 for(int i=2;i<=n;i++) 16 { 17 int j=0; 18 while(a[i][j]==a[i-1][j]&&j<a[i].length()) 19 { 20 j++; 21 } 22 tot=tot+(a[i].length()-j); 23 } 24 cout<<tot; 25 return 0; 26 }