1.位元組快取的基本原理
資料壓縮也被稱作基本壓縮,或無失真壓縮,一般採用 LZ 系列壓縮演算法。資料壓縮具有自包
含性:即對端解壓縮方只根據資料包本身:即可進行解壓還原,不需要其它任何資訊。壓縮比因數
據型別而異:文字資料壓縮比最大,各種網頁、Windows office 檔案(Excel、word 等等)、PDF 其
次,對多媒體和已壓縮資料基本無效。位元組快取技術又叫“字典快取”或“超級壓縮”等名稱。
它通過快取的方式在記憶體和硬碟中記錄下流經的資料流,並以一定的大小(例如 32 位元組、64 字
節或 128 位元組等)為最小單位建立易於查詢的索引。當以後流向廣域網鏈路的資料流出現了大於
最小單位的相同資料時,可以將該資料替換成某個更短的符號。遠端的裝置能夠將相應符號還原
成原始資料。
位元組快取與資料壓縮的不同之處是,位元組快取不具有自包含性。要解開壓縮資料,對端裝置
必須引用以前記錄的歷史快取資訊。為達到這一目的,位元組快取技術需要連線兩端的快取完全同
步,於是需要在每條廣域網鏈路兩端的加速裝置之間建立快取資料同步機制。對比於資料壓縮,
位元組快取的另一優勢是即使對本身不具可壓性的資料型別,如多媒體或已壓縮資料,只要曾經傳
輸過相同或類似資料,位元組快取即可以提取出全部或部分相同資料,從而大幅縮減需要傳輸的數
據量。位元組快取技術通過使用大量的快取資訊(包括該資料流本身以前的資料歷史和其他資料流
的資料歷史)來壓縮當前資料,有時能夠達到非常高的壓縮比。
2.MODP
MODP這種技術首先應用於在一個大的檔案系統中查詢相似的檔案。這種技術之所以叫MODP是由於使用了
取模運算和所有樣本中的1/p樣本被取樣。使用MODP的系統如下圖所示:

假設資料從左側伺服器傳送到右側伺服器。當資料包通過MODP(圖中 左側的LotWan),資料包中的重複部分將被替換為
Label,而在對端的MODP(圖中右側的LotWan)將Label替換成真正的資料。因此我們面對的問題就是如何提高查詢重複資料
的命中率!
2.1 指紋計算
我們可以用Rabin指紋來標識資料包。其定義如下:

Rabin指紋定義了一系列長度為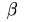 的位元組序列。當以
的位元組序列。當以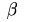 為視窗值和單個位元組遞增的方式就可以計算整個資料包的指紋。這種
為視窗值和單個位元組遞增的方式就可以計算整個資料包的指紋。這種
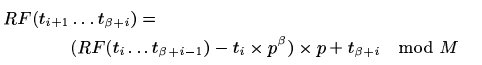
的位元組序列。當以為視窗值和單個位元組遞增的方式就可以計算整個資料包的指紋。這種
指紋計算方法的一個優勢就是下一個指紋可以通過上一個指紋計算出來,如下所示:
因此當我們有上一個指紋時,我們就可以通過一個減法,一個乘法,一個加法和一個取模計算出下一個指紋值。通過
提前計算 可以優化此步驟。
可以優化此步驟。
可以優化此步驟。
2.2 指紋選擇
由於指紋是按位元組遞增計算,指紋的總數接近於位元組總數,因此實現上不可能將所有的指紋取樣。重複資料
對位置非常敏感,我們也不可以按固定位置來選擇指紋,只要調整一個位元組就會影響後面指紋的計算。因此我們
就需要選擇部分指紋用於表示資料包。因為指紋都是隨機和均勻分佈,在實現上可以選擇指紋值的後p位為0的用於取樣。
2.3 演算法
MODP中需要一個字典來存放最近快取的資料包,字典通過標識資料包的指紋進行索引。對於一個需要快取的資料包的
虛擬碼如下:
1 def handle_packet(payload): 2 for i in paylod: 3 rf = hash(i) //計算指紋 4 if check(rf): //確認指紋是否符合取樣標準 5 if cache.find(rf): //是否在字典中查詢到相同的指紋 6 expand(rf) //向左和向右擴充匹配的字串 7 cache.rset(rf) //更新此指紋對於的資料包,如果原資料包沒有在其他地方引用,可以釋放。 8 else: 9 cache.set(rf): //用此指紋更新字典
2.4 應用舉例:
華夏的AppEx應該是使用類似技術。AppEx 首先使用全部快取資訊及字典索引對超過 64 位元組的長資料模式進行快速智慧匹配,再利用區域性快取資訊匹配短資料串(超過 8 位元組即可完成匹配),最後再對結果進行 LZ 壓縮。通過三級壓縮過程,資料的冗餘成分被完全提取。
通常資料壓縮和位元組快取功能由於對資料進行了複雜處理,並且處理中可能涉及到硬碟讀寫,往往引入可觀的延遲。對某些實時性要求較高的應用,顯著增加的延遲可能會帶來使用者體驗的明顯下降。為最大限度的降低這一副作用, AppEx 設計了獨特的記憶體硬碟二級快取及字典結構,動態智慧判斷最可能被使用的資料,並將其置於記憶體中。同時根據當前連線匹配情況智慧判斷接下來需要的歷史記錄,並提前調入記憶體中。除此之外,AppEx 還動態監控資料延遲,在必要時改變壓縮方式(如只採用 LZ 壓縮等方式)以控制延遲引入。這一獨特的延遲的控制為使用者帶來整體應用體驗的提升。
2.5 存在的問題:
- 為了讓hash衝撞的可能性儘可能的小,選擇hash的槽數為2的60次方,在實現上這樣明顯不可以行,因此需要二級hash來實現,這樣的話就有可能資料沒有在二級hash表上均勻分佈,從而導致查詢的時間過長。
- 在選擇樣本的時候,我們只選擇了指紋值後p位為0的值,這樣導致會導致重複資料沒有被選取。
- 需要考慮傳送端和接收端之間的資料一致性。
3.PACK
PACK是一種低延遲、低CPU開銷的TRE(traffic redundancy elimination)技術。PACK設計需要TCP擴充套件項的支援,
因此PACK可以支援所有應用TCP的應用程式。PACK是一種基於接收端TRE技術,而傳送端不需要快取資料並進行過多的計算。
3.1 PACK的處理流程如下:

如上圖,PACK對TCP的三次握手和資料傳送都進行了一定的修改。
3.2 資料的快取
PACK的資料快取類似於LBFS(A Low-bandwidth Network File System)。PACK和MODP一樣,
需要考慮如何標識已經接收的歷史資料。對於接收資料的處理如下:
1 def handle_data(payload): 2 for i in payload: 3 rbhash = hash(i) //第一步:計算資料包的Rabin指紋 4 if check(rbhash): //第二步:根據標準選取資料包的分割點,通過分割點將資料包分割的長度近似500位元組。 5 setbound(i)
第一步中我們按48bits來計算Rabin指紋,使用這種方法是因為Rabin指紋是位置無關的。第二步
只有最小的12或13位的值等於預定值的Rabin指紋才會被用來作為分割點。如下圖:
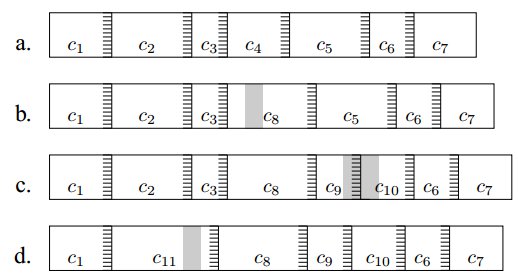
假如a為一個資料包初始的狀態,當資料包b中之是修改了c4的時候,那麼只會影響c4而不會影其餘的資料塊。
資料包c的修改也只是影響了c5,資料包d的修改只是影響了c2和c3。
對資料包進行分割後,將資料塊計算SHA後會存入字典,但是此字典有兩個特別之處:
- 在字典中的資料塊會用用指標建立連結串列,其順序就是資料塊在資料包中的順序。
- 此字典需要將以往所有接收的資料進行快取。
3.3 接收端演算法
接收端的主要功能:
- 驗證傳送端送來的資料是否已經快取,如果快取傳送預測資料。
- 如果傳送端送的資料是新資料,新增到字典。
演算法的虛擬碼如下:

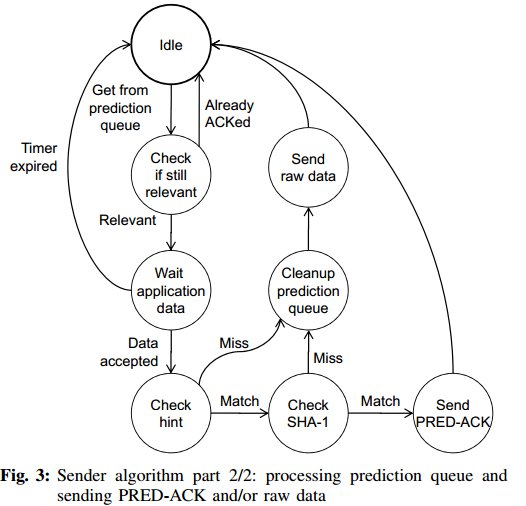
3.4 傳送端演算法
傳送端的主要功能就是當接收端發來預測資訊後,驗證傳送緩衝區的資料是否和預測資訊匹配。
通過狀態機來描述傳送端演算法。

3.5 應用

3.6 待考慮的問題
- PACK應該會影響TCP的其他功能,如TCP Retransmission、Delayed ACKs、Round-Trip Time Measurements 等。
- PACK的字典中並沒有實際的資料,需要考慮實際資料的存放。
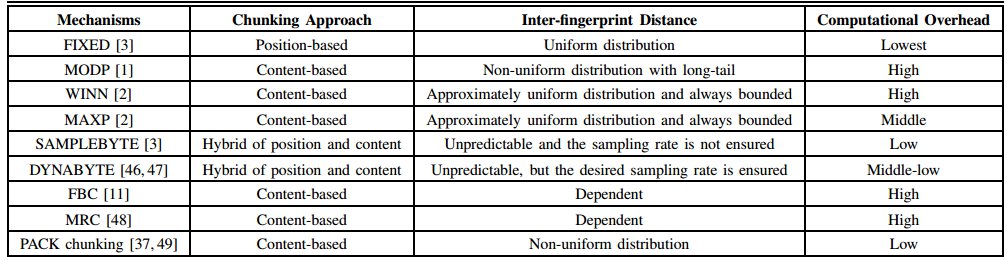
4.常用的位元組快取技術

參考資料
[1] A Protocol-Independent T echnique for Eliminating Redundant Network Traffic
[2] A Low-bandwidth Network File System
[3] PACK: Speculative TCP Traffic Redundancy Elimination
[4] On Protocol-Independent Data Redundancy Elimination
[5] HyperCompression 低延遲深度壓縮技術白皮書
[6] DiViNetworks Compression Technology