1.背景

5.關鍵路徑

目前收包存在的問題:
第一:inpterrupt livelock, 當收到包的時候,網路卡驅動程式就會產生一次中斷。在大流量的情況下,作業系統將花費大量時間用於處理中斷,而只有
少量的時間用於其他任務。
第二:將包從網路卡移動到使用者層花費的時間太久。
2.PF_RING的目標
1. 充分利用 device polling 機制
2. 減少核心開銷,開闢一條新的通道將收包從網路卡傳輸到使用者態
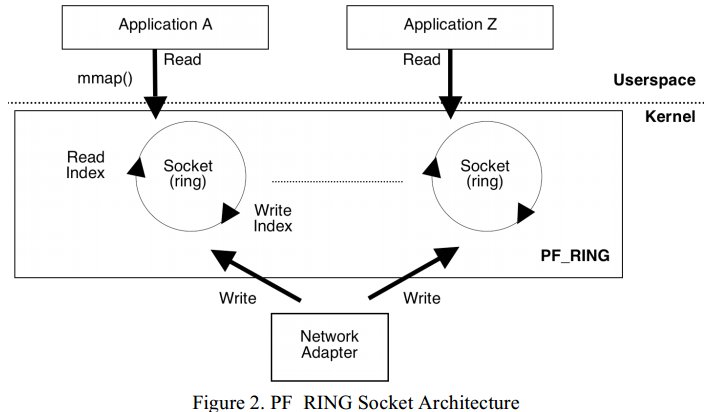
其架構圖如下:
PF_RING實現功能如下:
1. 建立一種新的套接字型別 PF_RING, 用於將收包拷貝到一個環形緩衝區
2. 環形緩衝區和PF_RING套接字一同建立和銷燬,各個緩衝區為套接字私有
3.如果一個網路卡介面卡被PF_RING套接字利用系統呼叫bind()繫結,這個網路卡只能用於只讀直到套接字銷燬
4.對於PF_RING套接字,收包將會被拷貝到套接字緩衝區或被丟包
5.套接字緩衝區將會利用mmap功能
6.使用者態程式通過mmap()系統呼叫訪問套接字緩衝區
7.核心拷貝包到環形佇列並移動寫指標,使用者態程式讀包並移動讀指標
8.新來的包將會覆蓋原有包,因此不需要進行記憶體的分配和釋放
9.套接字的緩衝區的長度和桶大小可被使用者配置
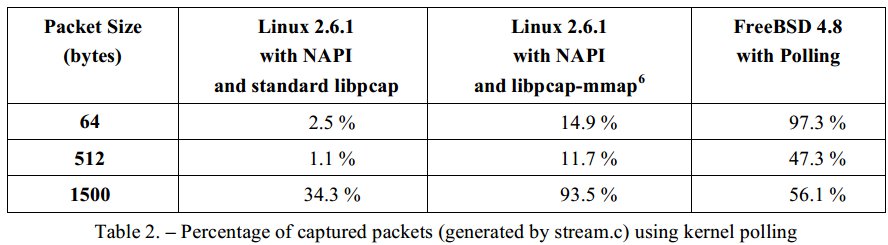
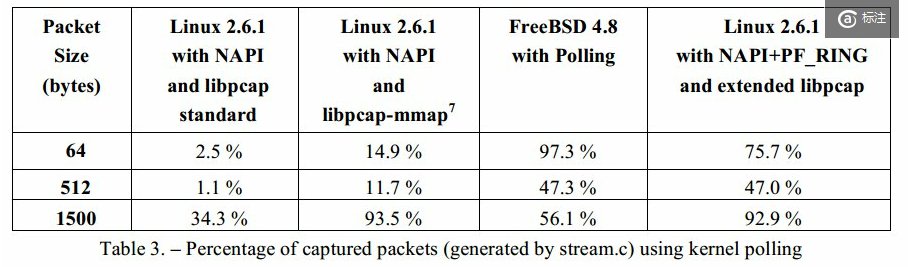
3.實驗效果
使用PF_RING之前:
使用PF_RING之後:
以上依然有丟包主要是因為使用者態程式阻塞在poll(),可通過核心補丁優化。
4.PF_RING 模式1和2的實現
處理流程圖:
5.關鍵路徑
函式igb_clean_rx_irq的內部實現:
第8080行函式nap_gro_receice實際上是一個巨集:
#define napi_gro_receive(_napi, _skb) netif_receive_skb(_skb)
函式netif_receive_skb分析分組型別,以便根據分類型別將分組傳遞到網路層的接收函式,為此該函式遍歷所有可能負責當前
分組型別的所有網路層函式,這樣的話就將包傳送至了核心協議棧。而第8075行的函式pf_ring_handle_skb函式將呼叫PF_RING的註冊函式進行處理。
6.考慮方案
在函式igb_clean_rx_irq增加包過濾函式,UDP且埠53傳送至PF_RING處理,而其餘包走核心協議棧。
7.需要考慮的問題
- 修改網路卡驅動且需要維護多個網路卡驅動
- 效能上不一定能到達DPDK的效果,因為DPDK丟棄了無關包
- PF_RING的發包需要使用DNA技術,而此功能需要費用。如果不使用DNA,發包將會走協議棧
- PF_RING是否對驅動進行了優化
備註:DNA功能和普通PF_RING比較減少一次記憶體拷貝
8.待做實驗
實驗目的:驗證模式0,1,2之間的差異
參考文獻:
Improving Passive Packet Capture: Beyond Device Polling - Luca Deri