背景:

 View Code
View Code
 View Code
View Code
View Code
View Code
View Code
View Code

核心接收分組的方式有兩種:第一種:傳統方式,使用中斷的方式;第二種:NAPI,使用中斷和輪詢結合的方式。
中斷方式:
下圖為一個分組到達NIC之後,該分組穿過核心到達網路層函式的路徑。
此圖的下半部分為中斷處理,上半部分為軟中斷。在中斷處理中,函式net_interupt是
裝置驅動程式的中斷處理程式,它將確認此中斷是否由接收到分組引發的,如果確實如此,
則控制權移交到函式net_rx。函式net_rx也是特定於NIC,首先建立一個新的套接字緩衝區,
分組的內容接下來從NIC傳輸到緩衝區(進入到實體記憶體中),然後使用核心原始碼中針對
各個傳輸型別的庫函式來分析首部的資料。函式netif_rx函式不是特定於網路驅動函式,該
函式位於net/core/dev.c,呼叫該函式,標誌著控制由特定於網路卡的程式碼轉移到了網路層的
通用介面部分。此函式的作用在於,將接收分組放置到一個特定於CPU的等待佇列上,並
退出中斷上下文。核心使用softnet_data來管理進出流量,其定義入下:
2352 /* 2353 * Incoming packets are placed on per-cpu queues 2354 */ 2355 struct softnet_data { 2356 struct list_head poll_list; 2357 struct sk_buff_head process_queue; 2358 2359 /* stats */ 2360 unsigned int processed; 2361 unsigned int time_squeeze; 2362 unsigned int cpu_collision; 2363 unsigned int received_rps; 2364 #ifdef CONFIG_RPS 2365 struct softnet_data *rps_ipi_list; 2366 #endif 2367 #ifdef CONFIG_NET_FLOW_LIMIT 2368 struct sd_flow_limit __rcu *flow_limit; 2369 #endif 2370 struct Qdisc *output_queue; 2371 struct Qdisc **output_queue_tailp; 2372 struct sk_buff *completion_queue; 2373 2374 #ifdef CONFIG_RPS 2375 /* Elements below can be accessed between CPUs for RPS */ 2376 struct call_single_data csd ____cacheline_aligned_in_smp; 2377 struct softnet_data *rps_ipi_next; 2378 unsigned int cpu; 2379 unsigned int input_queue_head; 2380 unsigned int input_queue_tail; 2381 #endif 2382 unsigned int dropped; 2383 struct sk_buff_head input_pkt_queue; //對所有進入分組建立一個連結串列。 2384 struct napi_struct backlog; 2385 2386 };
第2383行的input_pkt_queue即是CPU的等待佇列。netif_rx的實現如下:
3329 static int netif_rx_internal(struct sk_buff *skb) 3330 { 3331 int ret; 3332 3333 net_timestamp_check(netdev_tstamp_prequeue, skb); 3334 3335 trace_netif_rx(skb); 3336 #ifdef CONFIG_RPS //RPS 和 RFS 相關程式碼 3337 if (static_key_false(&rps_needed)) { 3338 struct rps_dev_flow voidflow, *rflow = &voidflow; 3339 int cpu; 3340 3341 preempt_disable(); 3342 rcu_read_lock(); 3343 3344 cpu = get_rps_cpu(skb->dev, skb, &rflow); //選擇合適的CPU id 3345 if (cpu < 0) 3346 cpu = smp_processor_id(); 3347 3348 ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail); 3349 3350 rcu_read_unlock(); 3351 preempt_enable(); 3352 } else 3353 #endif 3354 { 3355 unsigned int qtail; 3356 ret = enqueue_to_backlog(skb, get_cpu(), &qtail); //將skb入隊 3357 put_cpu(); 3358 } 3359 return ret; 3360 } 3361 3362 /** 3363 * netif_rx - post buffer to the network code 3364 * @skb: buffer to post 3365 * 3366 * This function receives a packet from a device driver and queues it for 3367 * the upper (protocol) levels to process. It always succeeds. The buffer 3368 * may be dropped during processing for congestion control or by the 3369 * protocol layers. 3370 * 3371 * return values: 3372 * NET_RX_SUCCESS (no congestion) 3373 * NET_RX_DROP (packet was dropped) 3374 * 3375 */ 3376 3377 int netif_rx(struct sk_buff *skb) 3378 { 3379 trace_netif_rx_entry(skb); 3380 3381 return netif_rx_internal(skb); 3382 }
入隊函式 enqueue_to_backlog的實現如下:

3286 static int enqueue_to_backlog(struct sk_buff *skb, int cpu, 3287 unsigned int *qtail) 3288 { 3289 struct softnet_data *sd; 3290 unsigned long flags; 3291 unsigned int qlen; 3292 3293 sd = &per_cpu(softnet_data, cpu); //獲得此cpu上的softnet_data 3294 3295 local_irq_save(flags); 3296 3297 rps_lock(sd); 3298 qlen = skb_queue_len(&sd->input_pkt_queue); 3299 if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) { 3300 if (qlen) { 3301 enqueue: 3302 __skb_queue_tail(&sd->input_pkt_queue, skb); 3303 input_queue_tail_incr_save(sd, qtail); 3304 rps_unlock(sd); 3305 local_irq_restore(flags); 3306 return NET_RX_SUCCESS; 3307 } 3308 3309 /* Schedule NAPI for backlog device 3310 * We can use non atomic operation since we own the queue lock 3311 */ 3312 if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) { 3313 if (!rps_ipi_queued(sd)) 3314 ____napi_schedule(sd, &sd->backlog); //只有qlen是0的時候才執行到這裡 3315 } 3316 goto enqueue; 3317 } 3318 3319 sd->dropped++; 3320 rps_unlock(sd); 3321 3322 local_irq_restore(flags); 3323 3324 atomic_long_inc(&skb->dev->rx_dropped); 3325 kfree_skb(skb); 3326 return NET_RX_DROP; 3327 }
NAPI
NAPI是混合了中斷和輪詢機制,當一個新的分組到達,而前一個分組依然在處理,這時核心
並不需要產生中斷,核心會繼續處理並在處理完畢後將中斷開啟。這樣核心就利用了中斷和輪詢的好處,
只有有分組到達的時候,才會進行輪詢。
NAPI存在兩個優勢
1.減少了CPU使用率,因為更少的中斷。
2.處理各種裝置更加公平
只有裝置滿足如下兩個條件時,才能實現NAPI:
1.裝置必須能夠保留多個接收的分組
2.裝置必須能夠禁用用於分組接收的IRQ。而且,傳送分組或其他可能通過IRQ進行的操作,都仍然
必須是啟用的。
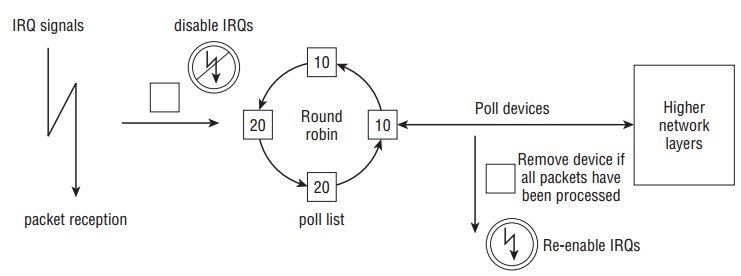
其執行概覽如下:
如上所示,各個裝置在進入poll list前需要禁用IRQ,而裝置中的分組都處理完畢後重新開啟IRQ。poll list使用
napi_struct來管理裝置,其定義如下:
296 /* 297 * Structure for NAPI scheduling similar to tasklet but with weighting 298 */ 299 struct napi_struct { 300 /* The poll_list must only be managed by the entity which 301 * changes the state of the NAPI_STATE_SCHED bit. This means 302 * whoever atomically sets that bit can add this napi_struct 303 * to the per-cpu poll_list, and whoever clears that bit 304 * can remove from the list right before clearing the bit. 305 */ 306 struct list_head poll_list; //用作連結串列元素 307 308 unsigned long state; 309 int weight; //裝置權重 310 unsigned int gro_count; 311 int (*poll)(struct napi_struct *, int); //裝置提供的輪詢函式 312 #ifdef CONFIG_NETPOLL 313 spinlock_t poll_lock; 314 int poll_owner; 315 #endif 316 struct net_device *dev; 317 struct sk_buff *gro_list; 318 struct sk_buff *skb; 319 struct hrtimer timer; 320 struct list_head dev_list; 321 struct hlist_node napi_hash_node; 322 unsigned int napi_id; 323 };
變數state可以為NAPI_STATE_SCHED或NAPI_STATE_DISABLE, 前者表示裝置將在
核心的下一次迴圈時被輪詢,後者表示輪詢已經結束且沒有更多的分組等待處理,但
裝置並沒有從poll list移除。
支援NAPI的NIC需要修改中斷處理程式,將此裝置放置在poll list上。示例程式碼如下:
2215 static irqreturn_t e100_intr(int irq, void *dev_id) 2216 { 2217 struct net_device *netdev = dev_id; 2218 struct nic *nic = netdev_priv(netdev); 2219 u8 stat_ack = ioread8(&nic->csr->scb.stat_ack); 2220 2221 netif_printk(nic, intr, KERN_DEBUG, nic->netdev, 2222 "stat_ack = 0x%02X\n", stat_ack); 2223 2224 if (stat_ack == stat_ack_not_ours || /* Not our interrupt */ 2225 stat_ack == stat_ack_not_present) /* Hardware is ejected */ 2226 return IRQ_NONE; 2227 2228 /* Ack interrupt(s) */ 2229 iowrite8(stat_ack, &nic->csr->scb.stat_ack); 2230 2231 /* We hit Receive No Resource (RNR); restart RU after cleaning */ 2232 if (stat_ack & stat_ack_rnr) 2233 nic->ru_running = RU_SUSPENDED; 2234 2235 if (likely(napi_schedule_prep(&nic->napi))) { //設定state為NAPI_STATE_SCHED 2236 e100_disable_irq(nic); 2237 __napi_schedule(&nic->napi); //將裝置新增到 poll list,並開啟軟中斷。 2238 } 2239 2240 return IRQ_HANDLED; 2241 }
函式__napi_schedule的定義入下:
3013 /* Called with irq disabled */ 3014 static inline void ____napi_schedule(struct softnet_data *sd, 3015 struct napi_struct *napi) 3016 { 3017 list_add_tail(&napi->poll_list, &sd->poll_list); 3018 __raise_softirq_irqoff(NET_RX_SOFTIRQ); 3019 } 4375 /** 4376 * __napi_schedule - schedule for receive 4377 * @n: entry to schedule 4378 * 4379 * The entry's receive function will be scheduled to run. 4380 * Consider using __napi_schedule_irqoff() if hard irqs are masked. 4381 */ 4382 void __napi_schedule(struct napi_struct *n) 4383 { 4384 unsigned long flags; 4385 4386 local_irq_save(flags); 4387 ____napi_schedule(this_cpu_ptr(&softnet_data), n); 4388 local_irq_restore(flags); 4389 } 4390 EXPORT_SYMBOL(__napi_schedule);
裝置除了對中斷處理進行修改,還需要提供一個poll函式,使用此函式從NIC中獲取分組。示例程式碼如下:
特定於硬體的方法 hyper_do_poll 從NIC中獲取分組,返回值work_done為處理的分組數目。當分組處理完後,
會呼叫netif_rx_complete將此裝置從poll list中移除。ixgbe網路卡的poll函式為ixgbe_poll, 而對於非NAPI的函式,
核心提供預設的處理函式process_backlog。
軟中斷處理相關
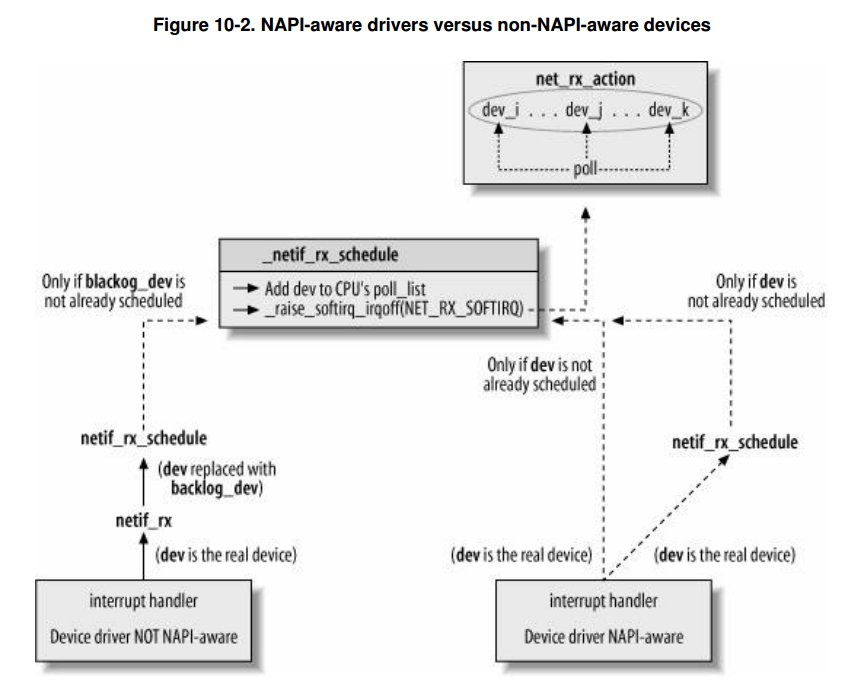
無論是NAPI介面還是非NAPI最後都是使用 net_rx_action 作為軟中斷處理函式。因此整個流程如下:
上圖中有些函式名已經發生變更,但是流程依然如此。在最新的3.19核心程式碼中,非NAPI的呼叫流程如下:
neif_rx會呼叫enqueue_to_backlog 將skb存入softnet_data,並呼叫____napi_schedule函式。
netif_rx===>netif_rx_internal===>enqueue_to_backlog===>____napi_schedule===>net_rx_action===>process_backlog===>__netif_receive_skb
e100網路卡的NAPI呼叫流程入下:
e100_intr===>__napi_schedule===>net_rx_action===>e100_poll===>e100_rx_clean===>e100_rx_indicate===>netif_receive_skb