前些日子,看到Herb Sutter在自己的部落格中推薦了一篇文章《Why mobile web apps are slow》,在推薦裡他這樣寫道:
“I don’t often link to other articles, but this one is worth reading.”
我不經常連結到其它文章,但是這篇文章的確值得一讀。
“He offers data (imagine!) to justly debunk many common memes and “easy answers” that routinely litter HN/Reddit/Slashdot comment threads.”
這句話挺難翻譯的,大概意思應該是作者使用了確切的資料來支援自己的觀點,而不像其他很多人一樣只是隨意地發出毫無根據的評論。”
“Don’t be distracted by the author’s viewpoint and emphasis on “iOS and Javascript” development – the article covers lots of important ground, including:
- developing for ARM vs. x86;
- developing for desktop vs. mobile;
- managed vs. native code performance;
- JIT issues vs. inherent language design tensions;
- why garbage collection is not at all the panacea it’s often billed to be and often needs to be emphatically avoided (did you realize Apple already jettisoned GC?); and
- as many of you know already, why if you’re serious about performance you’ll be seriously serious about memory usage and access patterns as a first-order issue.”
不要被作者的觀點以及iOS和Javascript開發等字眼分散注意力——這篇文章包含了很多重要的基礎知識,包括:
- ARM平臺程式設計和x86平臺程式設計比較;
- 桌面環境程式設計和移動裝置程式設計比較;
- 託管程式碼和原生程式碼效能比較;
- JIT相關話題和語言內在的設計張力;
- 為什麼垃圾回收不是宣傳中所說的萬能藥,而且經常被強調要避免使用(你意識到蘋果公司已經拋棄了GC嗎?);
- 就像你們中的很多人已經知道的那樣,為什麼如果你很在乎效能,那麼你就應該認真嚴肅地將記憶體使用和訪問模式作為最優先需要考慮的問題。
既然Sutter大神如此推薦,我就好好把這篇文章看下來了,的確收穫頗豐,所以特意把這篇文章翻譯下來,一方面加深理解,另一方面跟大家分享。我翻譯的首要目標是可讀性和流暢性,並不一定拘泥於字眼;難以翻譯和習慣用英文表達的詞彙會保留。我可以保證理解作者95%以上的意思(畢竟是技術類文章),但是作者的一些幽默我很可能沒法傳神地翻譯出來,還請大家包涵。
(提示:這是一篇非常長的文章,認真讀下來可能需要一段時間。下面是正文翻譯。)
我寫過不少文章來討論為什麼移動Web應用程式很慢,這也引起了不少的討論。但是不幸的是,這些討論沒有像我喜歡的那樣的基於事實。
所以我這篇文章的目地就是給這些問題帶來一些真正的證據,而不是僅僅過來對罵。在這篇文章的中,你可以看到基準測試(benchmark),可以看到專家的觀點,你甚至可以看到非常誠實(honest-to-God)的期刊文章。這篇文章有超過100個引用(不是開玩笑)。我不保證這篇文章能使你信服,甚至不保證這篇文章中的所有內容都是正確的(在這樣大規模的文章中做到這一點幾乎是不可能的),但是我可以保證這是一篇關於許多iOS開發者都抱有的想法——移動Web應用很慢並且會在可預計的未來繼續如此——分析最完備和全面的文章。
現在我要警告你:這是一篇長得嚇人的文章,差不多10000字。當然,這是我故意的。我更喜歡好文章,而不是流行的文章。我嘗試使得這篇文章成為前者,同時宣揚我認同的風氣:我們應該鼓勵那些優秀的、基於證據的、有趣的討論,不鼓勵那些詼諧、譁眾取寵的評論。
我寫這篇的文章,在某種程度上是因為這是話題已經到了一種爭論不休的地步。這不是另一篇爭論的文章,如果你想看到30秒左右的對罵:“真的!Web應用很渣!”和“誰說的?Web程式挺好!”,那麼這篇文章不適合你。另一方面,據我所知,到現在為止還沒有一個關於這個話題全面的、正式的、理性的討論。這篇文章中我嘗試去理性地討論這個激起千層浪的話題,儘管這可能是一個非常愚蠢的想法。這裡我給自己辯護一下,我相信這個問題與那些本來可以更好地去討論卻沒有這樣做的人更有關係,而不是主題本身。
如果你想知道你那些原生程式碼(native code)程式設計師朋友為什麼在如今開放的網路革命時期還在寫著萬惡的原生程式碼,那就把本頁面加入書籤吧,給自己倒杯咖啡,找出一個下午的時間,找到一個舒服的椅子,然後我們就正式開始吧!
簡單回顧
我上一篇部落格中寫道:基於SunSpider的benchmark給出的資料可以看出當今的移動Web應用很慢。
如果你認為“Web應用程式”就是“一個網頁加上一兩個按鈕”,那麼你就可以讓那些花哨的benchmark——比如SunSpider——滾一邊去。但是如果你認為“Web應用程式”是指“簡單的文書處理,簡單的照片編輯,本地儲存和螢幕之間的切換動畫”,那麼除非你有想死的心,否則你永遠不會願意在ARM上寫Web應用程式。
你應該先讀一下那篇文章,但是我還是在這邊給你看下benchmark:
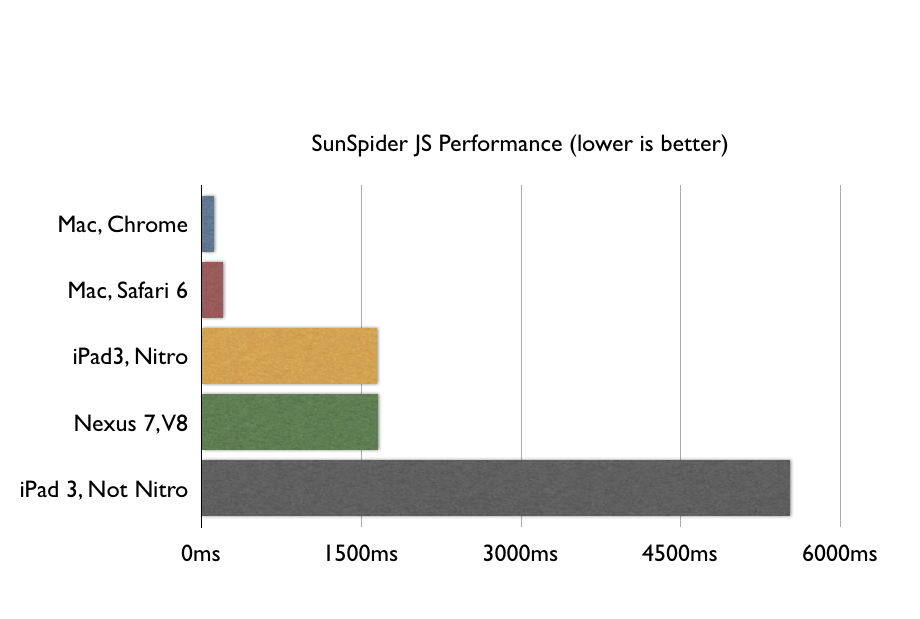
關於這個benchmark,主要三種主要的批評:
1. JS比原生程式碼要慢並不是什麼新鮮事了,每個人在上第一學期的計算機基礎課時討論編譯型語言、JIT語言和解釋型語言是時候就知道了。問題是JS是不是慢到已經成為你現在所寫軟體的大問題了,但是像這樣的benchmark並不能說明這個問題。
2. JS是很慢,這也的確是個問題,但是它在變得越來越快,所以在不久的未來,我們可以發現它不會那麼慢了。所以大家一起學JS吧。
3. 我是Python/PHP/Ruby的伺服器端的開發者,我不知道你們在說什麼。我知道我的伺服器比你們的移動裝置快,但是如果我可以自信地保證使用真正的解釋型語言寫出支援上千個使用者的程式碼,你們難道不能用一個帶有高效能JIT的語言寫出一個支援單個使用者的程式碼嗎?真的有那麼難嗎?
我有一個相當高的目標,那就是反駁以上所有觀點:是的,JS的確是慢到一定程度了;不,它在不久的未來不會變得有多快;不,你在伺服器端的程式設計經驗不能正確地對映到移動應用中。
但是真正的問題在於,在所有討論這個話題的文章裡面,基本上沒有人真正量化JS到底有多慢,或者提供某種真正有用的比較標準(相對於什麼來說慢)。為了糾正這樣的情況,我在這篇文章中提出了三種(不僅僅是一種)比較JavaScript效能的辦法。我不會說“JS在什麼情況下都慢”,而是真正量化它慢的程度,並且將它跟我們再平常程式設計經驗中的事情做對比,這樣你就可以根據這個結果結合自己的程式設計平臺做出決定,你也可以自己計算下看看是否JavaScript適合你自己的特定問題。
OK,但是JS的效能相比於原生程式碼到底如何?
這是一個好問題。為了回答這個問題,我從Benchmark Game中隨意抓取了一個基準測試。然後我找到了一個做同樣benchmark的較老的C程式(老到不像很多新程式有一些x86特性)。我在自己的iPhone 4S上分別測試Nitro和LLVM。所有的程式碼已經傳到了Github。
這是一個隨機的測試,正如日常生活中執行的程式碼一樣。如果你想要一個更好的實驗,可以自己執行。我執行這個實驗還有另外一個原因,就是因為其它的實驗都不存在LLVM和Nitro的對比。
在這個綜合的基準測試中,LLVM一致地比Nitro快4.5倍:
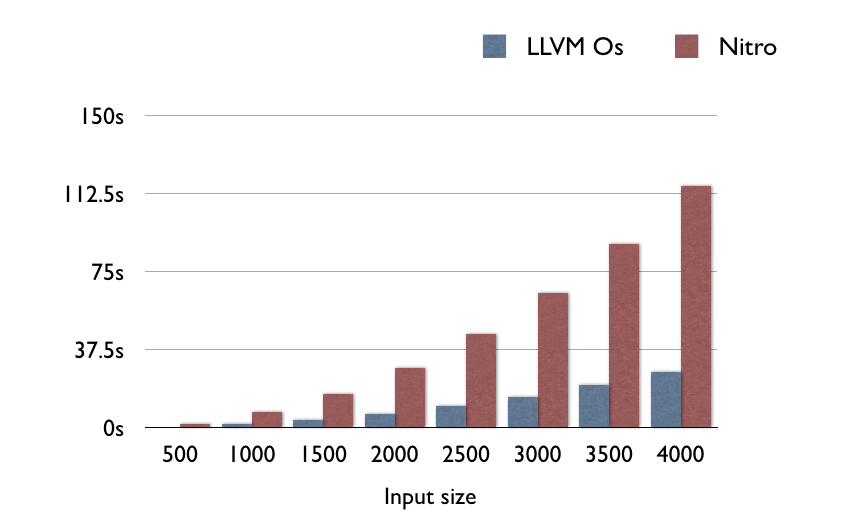
如果你在想“如果是計算密集型(CPU-bound)的功能,原生程式碼比Nitro JS快多少呢”,那麼答案是差不多5倍。這個結果大致上和Benchmark Game在x86/GCC/V8上面的結果一致,那裡面的GCC/x86通常比V8/x86快2到9倍。所以結果大致上是正確的,無論是ARM還是x86。
但是1/5的效能對每個人來說還不夠好嗎?
在x86上是足夠好了。當渲染一個電子表格的時候,CPU的計算能有多密集呢?其實並不是那麼難。問題是,ARM不是x86。
根據GeekBench的結果,最新的MacBook Pro的效能是最新的iPhone效能的10倍。這其實不算太大問題——電子表格沒那麼複雜。我們可以忍受10%的效能。但是我還要把它除以5?好傢伙!我們現在只有桌面效能的2%了。
OK,但是文書處理到底有多難?我們可不可以用一個m68k晶片加上一個協處理器來搞定呢?這是一個可以回答的問題。你可能記不起來,Google Doc的實時協作之前事實上還不是一個正式的功能,後來他們進行了大規模的重寫並且在2010年4月份加入到Google Doc裡面。我們來看一下2010年瀏覽器的效能:
![BrowserCompChart1 9-6-10[7]](http://sealedabstract.com/wp-content/uploads/2013/05/BrowserCompChart1-9-6-107.png)
從圖中可以清晰地看到,iPhone 4S在Google Docs的實時協作方面完全不是桌面網頁瀏覽器的對手。當然了,它還是可以跟IE8比上一比的。恭喜iPhone 4S,可喜可賀。
我們再看看另外一個正經的JavaScript應用:Google Wave。Wave從來沒有支援IE8,因為它實在是太慢了。
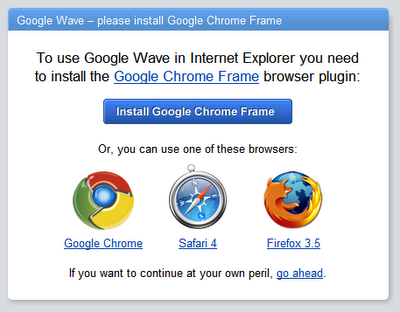
看到這些瀏覽器比iPhone 4S快多少了嗎?
注意,所有支援的瀏覽器的得分都低於1000,其中那個得分3800的因為太慢了而被忽略了。iPhone得分為2400。差不多和IE8一樣,太慢幾乎無法執行。
這邊要說明的是,在移動裝置上實現實時協作是可能的,只是不太可能用JavaScript來實現。原生程式碼和Web應用的效能差距基本上和Firefox與IE8的效能差距差不多,這麼大的差距足以影響正常的工作。
但是我感覺V8或者是現代JS已經有了接近C的效能了?
這取決於你怎麼理解“接近”了。如果你的C程式執行了10ms,那麼一個執行50ms的JavaScript程式差不多是接近C的速度了。如果你的C程式執行了10s,那麼一個執行了50s的JavaScript程式對於大多數正常人來說很可能就不是接近C的速度了。
硬體角度
1/5的速度在x86上是沒問題的,畢竟x86起點就比ARM快10倍,你還有很多上升空間。解決方案顯然是讓ARM變成10倍快,這樣就可以跟x86競爭了,然後我們就可以不用做任何工作就可以得到桌面環境的JS效能了。
這個方法行不行得通取決於你是否相信摩爾定律,以及給每個晶片配置一個3盎司的電池是否可行。我不是一個硬體工程師,但是我曾經為一家大型半導體公司工作過,那裡的人告訴我說當今硬體的效能基本上是製作工藝(process)起的作用。iPhone 5令人印象深刻的效能主要是因為其晶片工藝從45nm做到了32nm,減少了差不多1/3。但是如果想繼續這麼做,蘋果就要達到22nm的工藝。
順便提一下,Intel22nm工藝的Atom處理器現在還沒上市。而且Intel不得不重新發明全新的半導體,畢竟原來的半導體在22nm級別已經不適用了。他們會把工藝授權給ARM?再好好想想吧。如今22nm的產品少之又少,而且大部分被Intel掌控著。
事實上,ARM似乎已經在著手在明年嘗試28nm了(看看A7),同時Intel正在嘗試22nm甚至在稍微晚些時候嘗試20nm。從純硬體的角度,我感覺具有x86級別效能的x86晶片很可能遠遠比具有x86效能的ARM晶片更早登入智慧手機市場。
看一個前Intel工程師給我發的郵件:
我是一個前Intel工程師,剛開始從事於移動微處理器的工作,後來工作轉向了Atom處理器。無論如何,我有一個很偏激的觀點,即x86從較大的核心轉向手機市場的難度遠比ARM從頭開始設計技術細節以達到x86的效能級別的難度要低很多。
再看一個機器人領域的工程師給我發的郵件:
你說得非常對,這些(譯註:指的是ARM的發展)不會帶來多大的效能提升,Intel可能在近幾年之內就會有更高效能的移動處理器。事實上,移動處理器當前和桌面處理器面臨著同樣的問題,即工作頻率達到3GHz左右的時候,再提高時鐘速度就不可避免地使得功耗大大增加。這種情況同樣會發生在下一代工藝上,儘管IPC(Instruction per Clock,即CPU每一時鐘週期內所執行的指令多少)會得到一些提高(差不多10%-20%)。在面臨這種限制的情況下,桌面處理器開始向雙核和四核方向變化,但是移動處理器現在已經是雙核和四核了,所以想提高效能不是那麼容易。
摩爾定律無論怎麼說都可能是正確的,但是這需要整個移動生態環境向x86環境轉變。這並非完全不可能,畢竟曾經有人做過這樣的事。但那是在移動處理器一年才賣出去100萬個的時候做的,不像現在,每個季度就可以賣出6200萬個晶片。那個時候現成的虛擬化環境可以模擬出老架構的60%的速度,而按照現在的研究來看,虛擬化系統上執行優化過的(O3)ARM程式碼的速度已經接近27%了。
如果你堅信JavaScript的效能最終會到達一個合理的水平,那麼硬體效能的提升絕對是最好的方式。要麼Intel會在5年之內開發出可行的iPhone晶片(這是有可能的),並且蘋果迅速轉向x86架構(這是不太可能的),或者ARM能夠在未來的10年之內得到效能的飛躍。但是在我看來,10年是一個很長的時間,長到足夠使某件事情可能成功。
恐怕我的硬體的知識只能分析到這裡了。我可以告訴你的是,如果你相信ARM可以在未來的5年之內填補與x86之間的效能差距,那麼第一步就是找到一個在ARM或者x86上工作的人(也就是真正懂硬體的人),讓他同意你的看法。我寫這篇文章之前,曾近諮詢過很多有很高資質的硬體工程師,他們所有人都拒絕公開發表這個觀點,這讓我感覺這個觀點不是很靠譜。
軟體角度
這是一個很多優秀軟體工程師犯錯誤的地方。他們的思路是這樣的:JavaScript已經變得更快了,並且它會變得更快。
這個觀點的前一部分是正確的,JavaScript的確變得快很多。但是我們現在已經達到了JavaScript效能的頂點了,它不可能變得更快多少。
為什麼?其實前一部分JavaScript的效能提升從某種程度上是硬體的原因,正如Jeff Atwood寫道:
我感覺從1996到2006之間JavaScript的效能變快了100倍。如果Web 2.0主要建立在JavaScript上的話,這很可能主要是因為摩爾定律所帶來的硬體效能提升。
如果我們把JS的效能提升總結為硬體效能提升的話,那麼JS的已有的硬體效能提升不能預測未來的軟體效能提升。這就是為什麼如果你相信JS會變得更快的話,最有可能的方式就是硬體變得更快,因為歷史趨勢就是如此。
那麼JIT如何呢?V8,Nitro/SFX,TraceMonkey/IonMonkey,Chakra等等?當然,當他們剛剛問世的時候,的確是很了不起的(但或許不像你認為的那麼了不起)。V8在2008年9月釋出,我找到了一份差不多那個時候同期的Firefox 3.0.3,看看它的效能:
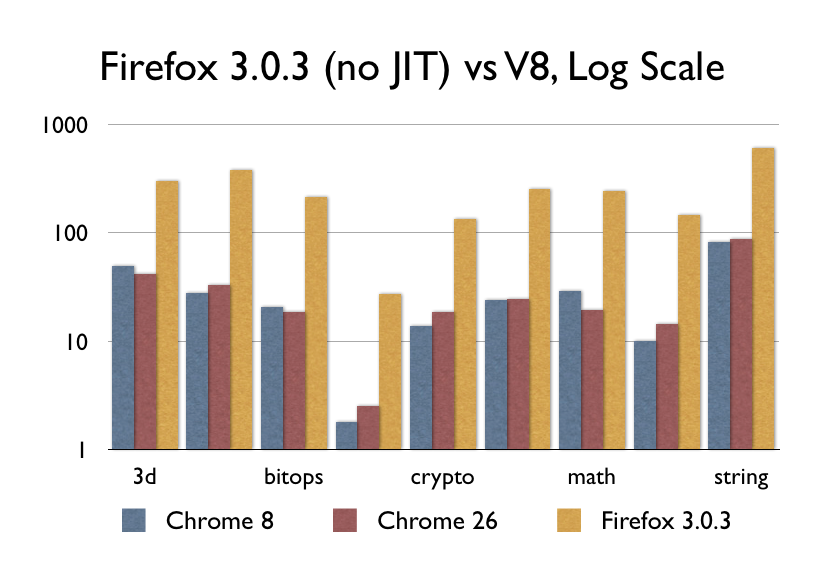
不要誤解我的意思,9倍的效能提升的確值得稱讚,畢竟這差不多是ARM和x86之間的效能差距了。即便如此,Chrome 8和Chrome 26之間的效能卻呈現出了水平線,因為自從2008開始,幾乎沒有什麼重大的事情發生。其他瀏覽器廠商都已經趕上來了,有些快有些慢,但是沒人真正提高過JavaScript的效能了。
JavaScript效能在提升嗎?
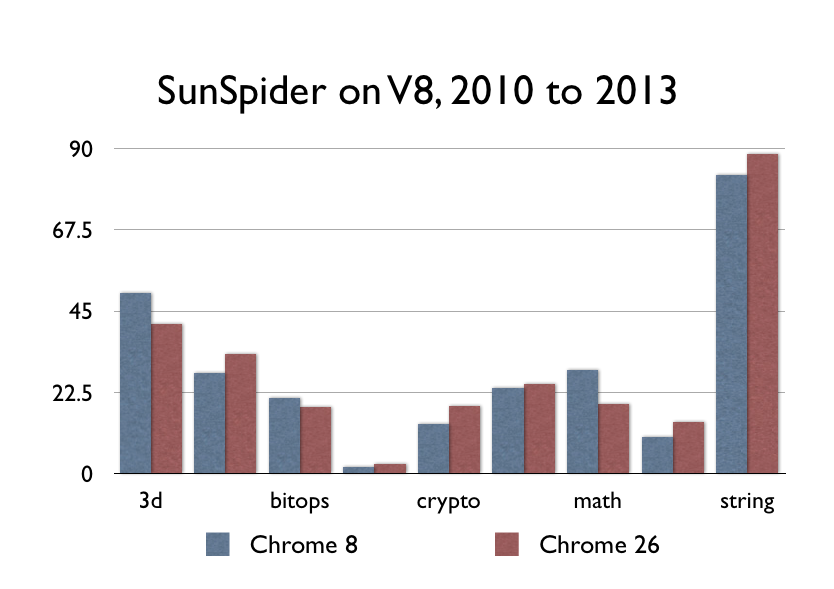
這是我Mac上的Chrome 8(可執行的最早版本,2010年12月份的版本)和Chrome 26。
看不出差別?因為根本沒有差別。JavaScript的效能最近根本沒有得到大的提升。
如果你感覺現在的瀏覽器比2010年的瀏覽器跑的快的話,那很可能是因為你有了一臺更快的電腦,但是這與Chrome的效能提升沒什麼關係。
更新:有些聰明的人指出SunSpider現在不是一個好的benchmark(並且拒絕提供任何實際的數字或其它什麼)。為了能夠可以理性地討論,我在一些舊版本的Chrome上面執行Octane(一個Google的benchmark),的確顯示出了一些效能提升:
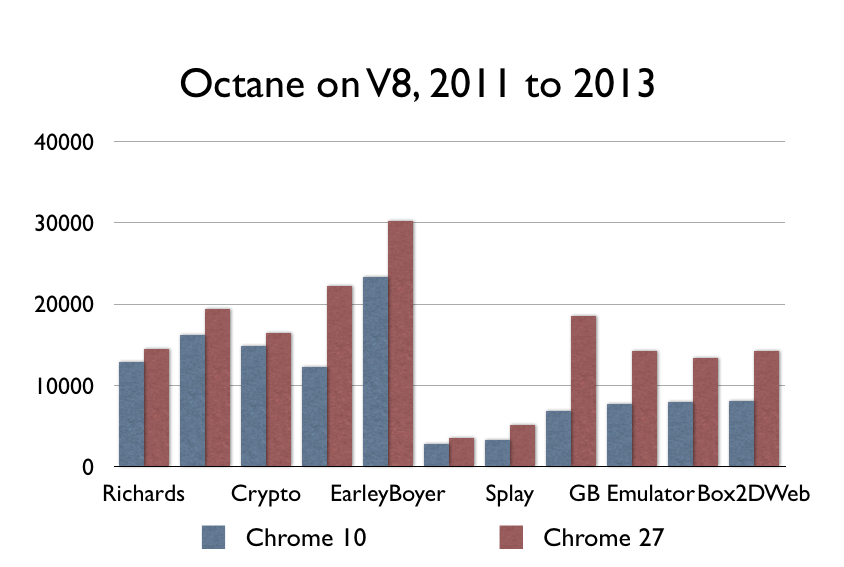
在我看來,在這個期間的效能提升還是太小,不足以支撐JS馬上就會足夠快這樣的論調。然而,要說我過分強調這個情況也沒錯,畢竟JavaScript的計算密集型操作的確在發生變化。但是推我來說,這些數字可以得出更大的推斷:這些效能提升的幅度還不足以在一定時間之內使得JavaScript的速度趕上原生程式碼。你需要效能達到2-9倍才能跟LLVM競爭。這些提升是好的,但還不足夠好。更新結束。
問題是,讓JavaScript採用JIT技術是一個60年前就有的想法,並且這60年來一直有人在研究。數以千計的你可能想到的程式語言對JIT的實現都證明這是一個好主意。但是既然我們已經做到了,我們已經用完了這個60年前的想法。夥計們,就是這樣的,表演結束了。或許我們可以在未來的60年之內想到另一個好辦法。
但是Safari恐怕比以前要快吧?
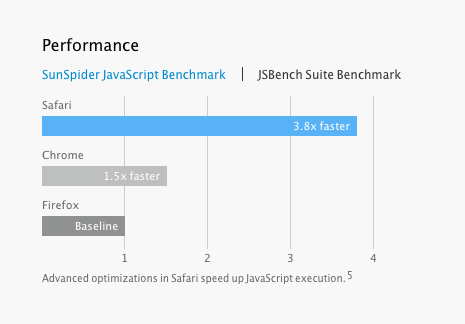
Safari 7 是不是比其它的瀏覽器快3.8倍?
這個結論或許對蘋果來說很容易得到,但是這個版本的Safari在NDA協議之下,所以沒有人能夠公開關於Safari效能的獨立引數。但是我可以僅僅根據現在已經得到的資訊來做一些分析。
我發現一些現象很有意思。第一、蘋果官方在公開的JSBench上的資料要比在他們在較老的benchmark(如SunSpider)上給出的資料高出不少。現在JSBench背後有一些非常酷的名字,包括JavaScript之父Brenden Eich。但是和傳統的benchmark不一樣,JSBench的工作方式並不是通過編寫大整數分解或類似的程式,它反而自動為Amazon、Facebook和Twitter提供的內容進行優化,而且根據它們提供的內容來建立benchmark。
如果你在寫一個多數人用來瀏覽Facebook的瀏覽器,我可以理解用一個只測試Facebook效能的benchmark是很有用的。但是從另外的角度講,如果你在寫一個電子表格的程式,或者遊戲,或是一個影象過濾應用,在我看來傳統的benchmark(注重整數運算和md5雜湊)會比分析Facebook效能的benchmark更能夠準確地幫你預測出程式碼有多快。
另一個重要的事實是,蘋果聲稱的在SunSpider上效能的提升並不能代表其它東西的提升,Eich et al在這篇提到蘋果所偏愛的benchmark的文章中寫道:
圖中清楚地顯示出了Firefox的3.6版本比1.5版本在SunSpider的benchmark上效能提高了13倍。但是當我們看它在amazon的benchmark上的效能表現時,發現只有較適度的3倍的提升。更有意思的是,在過去的兩年時間,在amazon的benchmark上的效能提升幾乎已經不存在了。這意味著在SunSpider上做的一些優化幾乎對amazon沒有太大作用。
在這篇文章中,JavaScript之父和Mozilla的首席架構師之一曾公開承認在過去的兩年之內Amazon的JavaScript效能幾乎沒有提升,沒有發生過什麼特別重要的事情。從這一點你也可以看出來,那些營銷人員這些年都在過分誇大自己產品的效能。
他們繼續爭辯道:對於那些人們用來瀏覽Amazon網頁的瀏覽器來說,執行Amazon的benchmark比執行其它benchmark要更能準確地預測出瀏覽器的效能(這是當然了……),但是這些手段不會幫助你更好地寫出一個照片處理程式。
但是無論怎麼說,從我可以看到的公開資訊來看,蘋果聲稱的3.8倍的效能提升對你來說幾乎沒有什麼太有用的東西。我可以告訴你,如果我有一些能夠反駁蘋果聲稱擊敗Chrome的benchmark的話,我將不被允許釋出它們。
所以,我們總結一下這一節,如果有一些人拿出一個柱狀圖來顯示網頁瀏覽器變得更快了,那並不能真正說明整個JS變得更快了。
但是還有一個更大的問題。
並非為效能而設計

下面這段話出自於Herb Sutter,現代C++中最著名的人物之一:
在過去的20年裡,有一種很難根除的文化基因——只要等到下一代的(包括JIT和靜態)編譯器出來,託管語言就會變得和原生語言一樣高效。是的,我完全希望C#和Java編譯器能夠不斷提高,包括JIT和類NGEN的靜態編譯器。但是,它們永遠不會消除與原生程式碼之間的效率差距,有兩個原因:一、JIT編譯不是主要問題。根本原因更為基本:託管語言在程式設計人員的開發效率(當時的確是個問題)和程式的執行效率之間從設計上做了故意的妥協。特別的,託管語言選擇選擇在所有的程式上新增額外的效能開銷,儘管你根本沒有用到一個特性,你都會受到這個特性帶來的額外的效能開銷。主要的例子是assumption/reliance、垃圾回收、虛擬執行環境和後設資料等功能在託管語言中是預設開啟。當然還有其它的例子,比如託管程式碼中函式預設是virtual的,而C++程式碼中的函式是預設inline的。1盎司(譯註:12盎司=1磅)的內聯阻止(inlining prevention)抵得上1磅的去虛擬化優化(devirtualization optimization cure)。
下面這段話出自於Mono專案組的Miguel de Icaza,他是為數不多的“維護著一個主流JIT編譯器的人”。他說道:
關於主流託管語言(.NET、Java和JavaScript)的虛擬機器之間的差異,有一個比較準確的說法。託管語言的設計者在他們設計一門語言的過程中更傾向於安全性,而不是效能。
或者你可以找Alex Gaynor談一談,他負責維護和優化Ruby的JIT編譯器,並且也為Python的JIT的優化工作做出了貢獻:
這是加在這些具有高生產力的動態語言身上的詛咒。它們使得建立一個雜湊表十分容易。這是一件非常好的事情。我認為C程式設計師多數不太會使用雜湊表,因為對他們來說用雜湊表實在是是一件痛苦的事情。原因有二:第一,你沒有一個內建的雜湊表;第二、當你嘗試去使用的時候,你會左右碰壁。對比來看,Python、Ruby和JavaScript程式設計師都過度使用雜湊表了,因為使用它們實在太容易了……所以大家都不在乎。
Google似乎意識到了JavaScript正面臨著效能的瓶頸:
複雜的Web應用(這是Google比較擅長的)在某些平臺上正在面臨著不小的掙扎,主要是因為這些應用用到了一些不能被效能調優的語言,這些語言有內在的效能問題。
最後,我們聽聽權威人士的意見。我的一個讀者向我指出這段Brenden Eich的評論。正如你所知,他是JavaScript之父。
有一點Mike沒有強調:得到一個更簡單的語言。Lua比JS簡單得多。這意味著你可以寫出一個簡單的直譯器使得它跑得足夠快,同時能夠保持對trace-JIT程式碼的尊重(這和JS不同)。
稍微下面一點又提到:
關於JS和Lua之間的差別,你可以說這完全是正確的設計和工程上的問題,但是內在的複雜性區別還是很大。你當然可以把較難的案例從熱路徑中刪除,但是他們也會因此付出代價。JS比Lua有更多的更難的案例。一個例子是:Lua(沒有顯式的元表使用)沒有像JS中的原型物件鏈(prototype object chain)的東西。
在這些真正從事相關工作的人當中,持有JS或者是其它動態語言能夠趕上C語言效能這個觀點的,只佔極少數(very much the minority)。到處都有和主流想法不同的人,所以根本無法沒有什麼辦法能夠達到真正的一致。但是,從語言的角度說到JIT語言是否能夠趕上原生語言的效率,他們給出的答案都是“不,不可能,除非修改語言本身或者API”。
但是還有一個更更大的問題。
都是因為垃圾回收
你可以發現,CPU問題、CPU相關的benchmark以及所有有關CPU的設計決定,都只是故事的一半。故事的另一半是記憶體。記憶體問題現在看來是如此的巨大,大到使整個CPU的問題看上去都僅僅是冰山一角。實際上可以討論的是,所有關於CPU的討論都是轉移注意力的話題(red herring)。你接下來要閱讀的應該會完全改變你對移動裝置軟體開發的理解。
2012年,蘋果做了一件非常奇怪的事情(當然了,除非你是John Gruber,能夠看到它的到來)。他們把垃圾回收從OSX中除去了。真的,你可以去看看程式設計師指南。標題右邊有一個大大的“不推薦(Not Recommended)”。如果你之前是Ruby、Python、JavaScript、Java、C#或是其它任何1990年代之後誕生的語言的開發者,這應該會讓你感覺很奇怪。但是這很可能不會影響到你,因為你很可能不在Mac下面使用ObjC,在HN點選下一個連結。但是這仍然看上去很奇怪,畢竟GC一直被大家使用著,而且它的價值也得到了證明。為什麼你要反對它呢?蘋果是這麼說的:
我們十分堅信ARC才是記憶體管理的正確方式,所以我們決定使OSX上的垃圾回收變成過時的(deprecate)。——ession 101, Platforms Kickoff, 2012, ~01:13:50
這段話沒有告訴你的是,當聽到這句話的時候,臺下的觀眾爆發出了熱烈的掌聲。OK,這就變得真的非常奇怪了。你是不是在告訴我有那麼一個屋子裡的程式設計師在為了垃圾回收之前的那種混亂的迴歸而鼓掌?你可以想象下如果Matz在RubyConf上宣佈GC過時的時候整個會場的寂靜,幾乎一顆針掉在地上都聽得到聲音。而這群人卻因此而高興?太古怪了吧?
你應該根據這些古怪的反應發現一些你現在看不到但是卻是在真正發生的事情,而不是僅僅把這些事情歸結於這群人對於蘋果的狂熱。這些正在發生的事情就是我們下面就要討論的主題。
思維過程是這樣的:把一個工作得好好的垃圾回收器從一個語言中拿出來簡直是瘋了吧?一個簡答的解釋可能是ARC可能僅僅是蘋果為了給垃圾回收披上一層美麗新裝而創造的一個營銷詞彙,所以這些開發者是為了這種升級而不是降級而鼓掌的。事實上,這就是很多iOS簇擁們的抱有的想法。
ARC不是一個垃圾收集器
所有的那些認為ARC是某種垃圾回收器的人,我想通過下面這個蘋果的幻燈片給你迎頭一擊(beat your face):

這與和垃圾回收有類似名字的演算法無關。它不是垃圾回收,他不是什麼像垃圾回收的東西,它表現得一點都不像垃圾回收,它不會打亂任何保留週期,它沒有去回收任何東西,它甚至沒有去做掃描。OK,故事結束,它絕對不是垃圾回收。
因為正式的文件還在NDA協議下,所以有很多傳言認為這並不是真的(但是細則已經可以看得到了,沒有任何藉口了),而且很多部落格都紛紛說這些不是真的。它是真的。不要再討論了。
垃圾回收不像你的經驗讓你感覺的那樣可行
這是蘋果在壓力之下給出的關於ARC和GC的說法:
在願望清單的頂端上我們能為你們做的最重要的事情就是把垃圾回收帶到了iOS中,而這恰恰是我們最不應該做的。不幸的是,垃圾回收給效能帶來了很多次優的影響。你程式中的垃圾回收會使得你的記憶體使用率變得很高,而且垃圾回收器經常在不確定的時間點上被觸發而導致非常高的CPU使用率,從而打斷使用者正在做的事情。這就是為什麼GC不適合在我們的移動平臺上使用的原因。對比來看,帶有獲取和釋放(retain/release)的手動記憶體管理學起來比較難,坦率的講有些像痔瘡(譯註:這個翻譯可能不準確,原文是pain in the ass)。但是它產生了更好更可預測的效能,這也是為什麼我們選擇手動記憶體管理作為我們記憶體管理策略的基礎的原因。因為在外面真實的世界,高效能以及使用者體驗的連續性是我們的使用者最看重的。(譯註:在蘋果看來,使用者體驗要比開發者體驗重要。)~Session 300, Developer Tools Kickoff, 2011, 00:47:49
但是這還是完全瘋狂了,不是嗎?這只是開始:
1. 這可能會直接影響你整個職業生涯對於垃圾回收語言給桌面和伺服器上帶來影響的理解;
2. Windows Mobile、Andriod、Mono Touch以及所有其它移動平臺上的GC似乎都可以挺好地工作。
所以讓我們反過來看這個問題。
移動平臺上的GC和桌面平臺上的GC不是同一回事
我知道你在想什麼,你是一個有了N年開發經驗的Python程式設計師。現在是2013年了,垃圾回收完全可以解決問題。
這是一篇你想看到的文章,似乎問題並沒有解決:
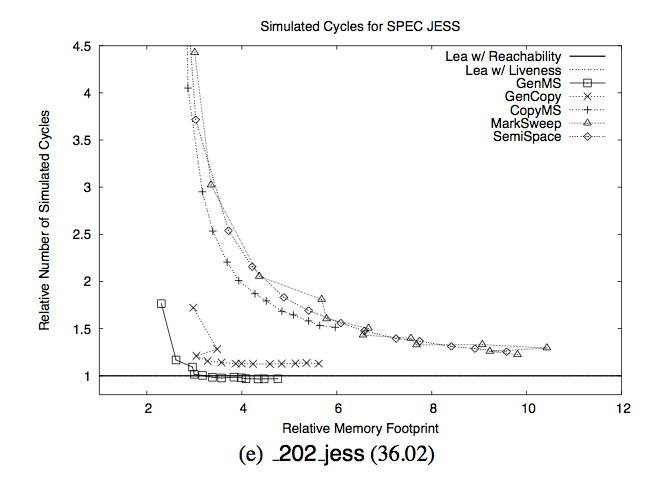
如果你在這篇文章中其它什麼都記不得,那麼請記住這張圖。Y軸是垃圾回收所用的時間,X軸是“相對的記憶體足跡”,相對於什麼?相對於所需的最小記憶體。
這張圖想說明的是,“如果你有6倍以上你實際需要的記憶體,那麼使用垃圾回收是沒有問題的。但是如果你只有小於4倍你實際需要的記憶體,那麼災難就要降臨了。”。但是不要相信我的話:
特別的,如果垃圾回收時系統擁有5倍於所需的記憶體時,它的執行時效能差不多甚至是超過顯式記憶體管理。但是,垃圾回收的效能在必須使用小堆(small heap)的情況下會出現急劇下降。如果有3倍於所需的記憶體的話,它會跑得慢17%;如果只有2倍於所需的記憶體的話,會慢70%。垃圾回收比實體記憶體的換頁更容易受到記憶體不足的影響。在這種情況下,我們所測試的所有垃圾回收器相對於手動記憶體管理都出現指數級的效能下降。
現在我們再來比較一下顯式記憶體管理的策略:
這些圖顯示,如果可用記憶體在合理的範圍的情況下(但不足以容得下整個應用),顯式記憶體管理器都要比垃圾回收器快太多。比如說,pesudoJBB以63M的可用記憶體執行,Lea allocator在25s的時間內完成執行。在相同可用的記憶體下執行GenMS,花了超過10倍的時間來執行(255s)。我們可以看到其它benchmark套件的相同趨勢。最值得一提的例子是213 javac和Lea allocator一起在36M的記憶體下執行,總體執行時間是14s,而與GenMS一起執行的情況下,執行時間為211s,用了超過15倍的時間。
基本的事實是,在記憶體受限的環境下垃圾回收效能的下降是指數級的。如果你在桌面電腦上寫Python或者JS程式的話,你整個的體驗可能是這幅圖的右邊部分,你可以一輩子都體會不到垃圾回收帶來的效能問題。花點時間想想這幅圖的左邊部分,並且想想我們該如何應對。
iOS上有多少可用記憶體?
這一點很難準確地描述。從iPhone 4到iPhone 5,這些裝置上的實體記憶體從512M到1G不等。但是其中很大一部分為系統預留了,還有更大的一部分為多工處理預留了。所以唯一真正的方法是在不同的情況下進行嘗試。Jan Ilavsky寫了一個非常有用的工具來完成這個任務,但是貌似沒有人公開任何資料。但這一點現在已經改變了。
現在,在一種“正常”的情況下(這一點很難具體說清楚是什麼意思)進行測試是非常重要的,因為如果你在一臺剛剛啟動的機器上測試的話,你會得到更好的資料,畢竟你的系統裡面沒有Safari所開啟的頁面。所以我就在“真實世界”的情況下拿出一些我公寓裡的裝置進行本次benchmark。

你可以點選進去看看詳細的結果,大體上來說,在iPhone 4S上,當你的程式使用了40M記憶體的時候就會得到警告,而使用了213M記憶體的時候,程式就會被殺死;在iPad 3上,使用400M左右時獲得警告,而使用550M左右的時候,程式被殺死。當然了,這些也僅僅是數字而已,如果你的使用者在聽音樂或者在後臺跑一些程式,你可用的記憶體會比我測試裡面可用的記憶體更少,這只是給你一個思路而已。這麼多記憶體看上去不少(213M應該對每個人來說都足夠了,是吧?),但實際上這還不夠。舉個例子,iPhone 4S拍照時的解析度為3264*2448,每張照片有超過30M的點陣圖資料。如果你在記憶體里載入了2張照片你就會獲得警告,而如果載入了7張照片,程式就會被殺死。哦,你打算給你寫個迴圈在你的相簿中逐個處理?程式會被殺死。
還有一點需要十分注意:實際的情況下,一張照片可能存在於記憶體的多個位置。比如說,如果你在拍照片,那麼你在以下位置都有資料:1) 你通過螢幕看到的攝像頭中的資料,2) 攝像頭實際上拍到的照片資料,3) 你嘗試寫到儲存卡中的壓縮JPEG緩衝資料;4) 你準備在下一個屏中顯示的資料;5) 你準備上傳到某個伺服器中的資料。
在一些點上你會發現,保留30M的緩衝區去顯示照片縮圖是一個非常不好的想法,因為這樣你會引入更多的資料:6) 用來保留下一屏顯示合適大小照片的快取;7) 用於在後臺重新調整照片大小的快取(在前臺做實在太慢了)。然後你發現你可能真正需要5個不同的大小,然後你的程式就不是一般的慢了,而是慢到讓人抓狂。在實際的應用程式中,僅僅是處理一個照片就會遇到記憶體的瓶頸並非罕見的事情。但是不要相信我說的話:
你能做的最糟糕的事情就是在記憶體不充足的情況下在記憶體中快取圖片。當一張圖片被畫成點陣圖或者顯示到螢幕上時,我們就不得不把照片解碼為點陣圖。點陣圖的每個畫素點為4位元組,無論原始圖片多大都是如此。每當我們將它解碼一次,點陣圖就會繫結到圖片本身並且一直維持到這個物件生命週期結束之時。所以如果你把圖片載入到記憶體而且曾經顯示過一次,那你現在就會在記憶體中保留整個點陣圖,直到你釋放它為止。所以永遠不要把UIImage或者CGImage放到快取中,除非你有一個非常明確(但願是非常短期的)的目標。- Session 318, iOS Performance In Depth, 2011
你甚至不要相信上面的話!你給自己分配的記憶體其實只是冰山一角。下圖是蘋果一張幻燈片中給出的冰山的全圖。Session 242, iOS App Performance – Memory, 2012:

你可以從兩方面考慮這個問題。第一、在213M可用記憶體的情況下,在iOS上寫一個照片處理程式比在桌面上寫一個要困難許多。第二,你在iOS上寫一個照片處理程式時,你對記憶體的需要會更多,因為你的桌面程式沒有一個可以放進你口袋的攝像頭。
我們可以看看另外一個例子:在iPad 3上,你要顯示一個視訊,這種照片的大小很可能比你電腦上的視訊要大不少(後面的高解析度攝像頭,差不多2000-4000畫素)。每一幀要顯示的就是一個12M的點陣圖。如果你對記憶體的使用很節省的話,每一時刻你可以在記憶體中保留45幀的未壓縮視訊或動畫快取,也就是在30fps的情況下每1.5s,在60fps的情況下0.75s。你想為一個全屏的動畫預留快取?應用被殺死。值得指出的是,AirPlay的延遲是2s,所以對於任何多媒體型別的應用,你幾乎是保證沒有足夠的記憶體。
這種情況下我們同樣面臨著和照片的多個資料拷貝差不多的問題。比如說,蘋果指出,“每一個UIView背後都有一個CALayer,而且只要CALayer存在於在這個層次中,對應的圖片資料會一直儲存在記憶體中”。這意味著,很可能有許多中間的渲染資料的拷貝存在於記憶體中。
還有剪下矩形和備份儲存這些可能會佔用記憶體的事情。這樣的資料處理架構事實上是非常高效的,但是這帶來的代價是程式會盡可能地佔用記憶體。iOS不是為低記憶體使用而設計的,它是為了快速執行而設計的。這沒有和垃圾回收扯在一起。
我們同樣需要從兩個方面考慮問題。第一,你在一種記憶體非常緊缺的情況下做出動畫效果;第二、做出這樣超級高質量的視訊和動畫是需要極大的記憶體的。而為了使得普通消費者買得起消費級別的、具有高攝像頭解析度的產品,這種糟糕的、記憶體受限的環境幾乎是必然的選擇。如果你想寫一個軟體來毫無壓力地播放視訊,那麼你就得說服別人為了螢幕多花700美元,或者花500美元買一個iPad,它實際上已經包含了一個內建的電腦。
我們會獲得更多記憶體嗎?(更新)
一些聰明的人說:“OK,你說了很多關於我們不會有更快的CPU。但是我們應該回有更多的記憶體吧?這正是桌面環境上發生的事情。”
這種理論的一個問題是,ARM平臺上的記憶體就在處理器本身上,這被稱為package on package。所以在ARM上獲得更多的記憶體幾乎和提高CPU效能是同一個問題,因為它們歸根結底是同一件事情:在CPU上整合更多的電晶體。記憶體電晶體處理起來稍微容易一些,因為它們是統一的,所以不是那麼難,但實際上也不是那麼簡單。
如果你看看iFixit的A6的照片,你會發現在CPU模具最表面的矽幾乎100%都是記憶體。這意味著,如果你想擁有更多的記憶體,你要麼使得製作工藝更精細,要麼提高模具的大小。事實上,如果你把工藝的大小做歸一化處理,那麼其實伴隨著每次記憶體升級,你的模具都在變得更大。
矽其實是一種不完美的材料,為了獲得更大的尺寸所付出的的代價是指數級增長的。它們也很難維持較低的溫度,也很難放進小裝置中。它們和製作出更好的CPU的目標是重複的,因為記憶體也面臨同樣的問題:CPU最上層的矽中需要放進更多的電晶體。
我搞不懂的是,面臨著PoP的這些問題,CPU廠商們繼續使用PoP的方式為系統提供記憶體。我還沒有遇到任何ARM工程師能夠解釋這一點。或許以下的評論可能會幫助我們理解。我們有可能從PoP架構轉向電腦中採用的分離記憶體模組,而且我感覺這比較可行。原因很簡單,將記憶體分為單獨的模組比製造出更大的晶片和進一步減小製作工藝對廠商來說毫無疑問成本是更低的。但是現在所有的廠商都在不停地嘗試提高製作工藝或者製作出更大的晶片,而不是把記憶體模組獨立出來。
然而,一些聰明的工程師曾經給我發了郵件讓我填補了這方面的空白。
一個前Intel工程師說道:
PoP記憶體模型可以大量減少記憶體延遲,也可以減輕路由問題。但是我不是ARM工程師,也不確定這是否是全部的原因。
一個機器人學的工程師提到:
當PoP記憶體不夠用時,“3D”記憶體會提供足夠大的記憶體:記憶體晶片在生產的時候堆疊在一起,1G的RAM在同一層堆成10層向上,就像現在的硬體模型一樣。但是,這樣的開銷會很大,頻率和電壓都要相應地降低使得電力消耗處於一個合理的水平。
移動RAM的頻寬不會像最近提高得這麼快了。頻寬被連線SoC和RAM包的匯流排的數量所限制。當前RAM的匯流排多數使用的是高效能SoC的圓柱體表面。SoC的中間部分不能用來加入RAM匯流排,因為這些RAM包是層疊的。接下來的重大改變應該回來自於將SoC和記憶體放在一個單獨的、高度整合的包中,允許更小、更密集和大量的RAM匯流排(更大的頻寬),並給SoC設計和更低的RAM電壓帶來更多自由。根據這樣的設計,更大的快取也就可能成為現實,因為RAM可能用更高的頻寬放在SoC模具中。
但是Mono/Andriod/Windows Mobile平臺怎麼解決這個問題呢?
這個問題事實上有兩個答案。第一個答案我們可以從圖中看出。如果你發現你有6倍於所需的記憶體,垃圾回收其實是非常快的。舉個例子來說,如果你在寫一個文字編輯器,你可能可以用35M的記憶體完成自己要做的所有事情,這是我的iPhone 4S會崩潰記憶體上界的1/6。你可能在Mono上寫個文字編輯器,看到非常不錯的效能,然後從這個例子中得出如下結論:垃圾回收十分適合這個任務。你是對的。
然而Xamarin框架在案例中有一個飛行器模擬器。很顯然的是,垃圾回收對於現實生活中的較大的應用程式來說是不適合的。難道不是嗎?
你在開發和維護這個遊戲時一定會遇到什麼樣的問題?“效能一直是一個大問題,而且將持續是我們再跨平臺中會遇到的最大的問題之一。最初的Windows Phone裝置是非常慢的,我們不得不花很多時間來優化程式,使得它達到一個體面的幀率。我們不僅僅在飛行模擬程式碼上進行優化,而且在3D引擎上優化。垃圾回收和GPU的弱點是最大的瓶頸。
程式設計師不約而同地聲稱垃圾回收是最大的瓶頸。當你的案例中的人在抱怨的時候,那應該是一個足夠引起你重視的線索了。但是Xamarin可能是一個局外人,我們還是來看看Andriod開發者怎麼說的吧:
請記住下面是我在我的Galaxy Nexus上執行的情況:無論怎麼說都是效能非常不錯的裝置。但是看看渲染的時間!我在電腦上只要花幾百毫秒就可以渲染出這些圖片,可是在這臺手機上卻花了超過兩個數量級的時間。渲染“inferno”圖片超過6s?這簡直是瘋了吧!要生成一副圖片,需要10-15倍的時間來執行垃圾回收器。
另一個開發者:
如果你想在Andriod手機上為實時物體識別或者基於內容的現實增強進行對照相機圖片的處理,那麼你很可能聽說過照相機預覽回撥(Camera Preview Callback)的記憶體問題。每次Java程式嘗試從系統獲取預覽圖片時,系統就會建立一大塊新的記憶體。當垃圾回收器釋放這塊記憶體時,系統會卡住(freezes)100ms到200ms。如果系統在高負載的情況下,事情可能會變得非常糟糕(我曾經在手機上做過物體識別——天吶,它幾乎把整個CPU都佔用了)。如果你看過Andriod 1.6的原始碼你就會知道,這只是因為這個功能的包裝類(wrapper,用來包裝原生程式碼)每次在一個新的幀可用時都會申請一個新的位元組陣列。當然,內建的原生程式碼可以避免這個問題。
或者,我還可以去看看Stack Overflow:
我負責在Andriod平臺上為Java寫的互動式遊戲進行效能調優。很多時候,當候垃圾回收開始工作會讓使得遊戲的畫圖和互動功能發生打嗝。通常情況下這種打嗝持續不到1/10s,但有的時候在比較慢的裝置上會長達200ms。如果我在一個內部迴圈中使用樹或者雜湊表,我就就知道我要很小心,或者甚至不用Java標準的Collections框架,而是自己重新實現一個,因為我承擔不起垃圾回收帶來的額外開銷。
這是一個“接受的答案(accepted answer)”,有27個人贊同:
我也是Java手機遊戲的開發者……避免垃圾回收(垃圾回收可能在某個點被出發從而大幅降低你遊戲的效能)的最好方法就是不要再遊戲的主迴圈中建立物件。實在沒有什麼“簡潔”的方式來處理這種問題,或許只有手動追蹤這些物件了,真悲哀。這地也是目前大部分當前移動裝置上效能優良的Java遊戲所採取的的方式。
我們來看看Facebook的Jon Perlow怎麼看待這個問題:
對於開發流暢的安卓應用來說,GC是一個非常大的效能問題。在Facebook,我們遇到的最大問題之一是GC會使得UI執行緒暫停。當我們處理很多點陣圖資料時,GC被觸發的頻率很高,而且難以避免。GC經常導致掉幀的問題。即使GC只會阻塞UI執行緒幾毫秒,但這卻會嚴重影響原本需要16毫秒的幀渲染。
OK,我們再聽聽一個微軟MVP的說法:
通常情況下,你的程式碼在33.33ms之內就會完成執行,從而使得30fps的幀率變得很不錯。但是當GC執行的時候,它會佔用那個時間。如果你的堆比較整潔和簡單,那麼GC一般可以執行得不錯,不會對程式產生什麼影響。但是讓一個簡單的堆處於一個使GC可以快速執行的情形是一件困難的程式設計任務,它要求大量的計劃和/或程式重寫,即使是這樣也不是完全安全的(有時在一個複雜的、有很多玩意的遊戲中你的堆裡面有很多內容)。更簡單的方法是(假設你能這麼做),在遊戲過程中限制甚至是禁用記憶體分配。
在有垃圾回收的情況下,在遊戲中保證一定會贏的方法就是不要玩(作者的幽默,原文:the winning move is not play)。比這種哲理稍弱的一種形式如Andriod官方文件中所說的:
物件建立永遠不是免費的。帶有執行緒級別記憶體池的垃圾回收器使得記憶體分配的成本變得稍微低一些,但是分配記憶體永遠比不分配記憶體開銷大。因為當你在程式中分配物件時,你會強制垃圾回收週期性地工作,從而使得使用者體驗不是那麼流暢。Andriod 2.3當前引入的垃圾回收器有一些作用,但是要是應該避免不必要的工作。因此,你應該避免建立你不需要的物件例項。一般而言,儘可能不要建立短期臨時物件。越少的物件建立就意味著越低頻率的垃圾回收,從而提高使用者體驗。
還不信?那讓我來問問一位真正從事垃圾回收工作的工程師,他為移動裝置實現垃圾回收器。
然而,WP7系統的手機CPU和記憶體效能正在大幅度地提升。遊戲和大型Silverlight應用越來越多,這些程式會佔用100M左右的記憶體。隨著記憶體的變得越來越大,很多物件擁有的引用會指數級地變多。在上面解釋的模式中,GC不得不去遍歷每個物件以及他們的引用,標記它們,然後清理沒喲引用指向的記憶體。所有GC的時間也大幅增加,並且成為這個應用的工作集(workingset)的一個函式。這會在大型XN遊戲中和SL應用中導致程式卡住,體現在很長的啟動時間(因為GC有可能在遊戲啟動的時候執行)或者遊戲過程中的小問題。
還是不信?Chrome有一個測量GC效能的benchmark。我們來看看它都幹嘛了:

你可以看到很多GC導致的卡頓。當然了,這是一個壓力測試,但還是能說明問題的。你真的願意花幾秒時間來渲染一幀?你瘋了吧。
這麼多引用,我才不會挨個看呢,直接告訴我結論就行了。
結論是:移動裝置上的記憶體管理很難。iOS平臺的開發者已經形成了一種文化,即手動做大部分事情,讓編譯器做其它容易的部分。Andriod平臺形成的文化是,提高垃圾收集器的效能,但事實上開發者在實際開發中儘量避免使用它。這兩者的共同點是,大家在開發移動應用時,開始越來越多地考慮記憶體管理問題了。
當JavaScript、Ruby或是Python開發者聽到“垃圾收集器”這個詞時,他們習慣將它理解為“銀彈(silver bullet)垃圾收集器”,也就是“讓我不要讓我再考慮記憶體問題的垃圾收集器”。但是移動裝置上根被沒有銀彈可言,每個人寫移動應用時都在考慮記憶體問題,不管他們是否使用了垃圾收集器。獲得“銀彈”記憶體管理方式的唯一方式就像我們在桌面環境上一樣,擁有10倍於程式實際需要記憶體。
JavaScript的整個設計基於一個思想,即不要擔心記憶體。看看Chromium開發者們怎麼說:
有沒有任何一種方式強制chrome的js引擎進行垃圾回收?一般意義而言,沒有,這是從設計的角度就已經確定了的。
ECMAScript規範沒有提到“分配(allocation)”這個詞,唯一與“記憶體”相關的話題本質上就是說整個主題都是“實現相關的(host-defined)”。
ECMA 6的維基頁面上有幾頁提案的草稿,歸根結底是說(不是開玩笑):
“垃圾回收器不可以回收那些程式需要繼續使用來完成正確執行的記憶體。所有不能從根節點傳遞遍歷到的物件都應該最終被銷燬,防止程式因為記憶體耗盡而發生錯誤。”
是的,他們的確在思考將這個需求規約:垃圾回收器不應該回收那些不應該被回收的東西,但是應該回收那些需要被回收的。歡迎來到tautology club。但是下面這段話可能與我們的話題更相關:
然而,並沒有規範說明單個物件佔用多少記憶體,也不太可能會有。因此當任何程式在記憶體耗盡的情況下,我們永遠不會得到任何保證,所以任何準確的、可觀察的下界。
用英語來說就是,JavaScript的思想(如果這算是一種思想的話)是你不應該能夠觀察到系統記憶體中的情況,想都不要想。這種思想和人們在寫實際的程式時候的想法簡直是令人難以置信的背道而馳(so unbelievably out of touch),我甚至找不到正確的詞語來向你形容。我的意思是,在iOS的世界裡,我們並不相信垃圾回收器,我們感覺Andriod開發者都瘋了(nuts)。我懷疑Andriod開發者會這麼認為:iOS開發者竟然會用手動記憶體管理,簡直是瘋子。但是你知道這兩個水火不容的陣營的人可以在哪件事情上達成共識嗎?那就是JavaScript開發者是真正的瘋子。你在移動平臺上寫出一個有點意思的程式,而從來不關心繫統記憶體的分配和釋放,是絕對不可能的(absolutely zero chance)。絕對不可能。暫時把SunSpider的benchmark上的問題和CPU計算密集型的問題都拋開,我們可以得出這樣的結論:JavaScript,儘管現在存在著,是和移動平臺軟體開發過程中絕對重要的思想,即永遠要考慮記憶體問題,從根本上是背道而馳的。
只要人們想要人們想在移動裝置上開發各種視訊和照片處理程式(不像桌面電腦),只要移動裝置的記憶體不是那麼充足,這個問題就是非常棘手的。你在移動裝置上需要理性的、正式的記憶體管理保證。而JavaScript從設計上來說是拒絕提供這些的。
假設它能夠提供這些
現在你可能會問,“OK,桌面環境上的JS開發者不會移動裝置上的開發者遇到的問題。假設他們相信你說的,或者假設有一些知道這些問題的移動開發者們根據JS重新設計一門語言。你感覺理論上他們可以做哪些事情?”
我不確定這是否是解決的,但是我可以在這個問題上放一些邊界。有另一群人曾經嘗試在JS的基礎上設計一門適合移動開發者的語言——RubyMotion。
這些人非常聰明,他們很瞭解Ruby。然後這些Ruby開發者認為垃圾回收對於他們的語言來說是一個糟糕的想法。(GC倡導者們,你們看到我說的了嗎?)所以他們用了一種非常類似ARC的技術然後嫁接到語言當中,然而卻沒有成功。
總結:很多人正經歷著由於RM-3或者其它難以辨別的問題所導致的記憶體相關議題,我們可以看看他們怎麼說。
Ben Sheldon說:
不僅僅是你,我也面臨著記憶體相關的程式崩潰(比如SIGSEGV和SIGBUS)生產環境下有10-20%的使用者遇到過這種情況。
有一些人懷疑這個問題是否易於處理:
我在最近的一次Motion Meetup會上提出關於RM-3的問題,Laurent和Watson都對此提出了自己的看法。Watson提到說,RM-3是最難修復的bug;Laurent說他嘗試了很多方法,但最終都沒有很好地解決這個問題。他們兩個人都是非常聰明和厲害的程式設計師,所以我相信他們說的話。
還有一些人懷疑編譯器理論上是否能夠解決這個問題:
很長的一段時間內,我都認為編譯器可以簡單明確地處理程式塊,即靜態地分析程式塊內部的內容來判斷程式塊是否引用了這個程式塊外部的變數。我認為,對於所有這些變數,編譯器可以在程式塊建立時獲取,在程式塊銷燬時釋放。這個過程吧這些變數的生命週期繫結到程式塊上(當然,在某種情況下不是“完整的”生命週期)。有一個問題是instance_eval(譯註:Ruby中Object類的方法)。程式塊中的內容或許是按你提前知道的方式使用的,但也有可能並不是你能夠提前知道的。
RubyMotion還有一個對立的問題:記憶體洩露,而且它還有可能有其它問題。沒有人真正知道程式崩潰時記憶體洩露有2個原因還是有200個原因。
所以不管怎麼說,我們的結論是:一部分世界上最好的Ruby程式設計師專門為移動裝置開發設計了一種語言,他們設計了一個系統,這個系統不僅會崩潰,而且還會記憶體洩露,這些問題都是你可能會面臨到的。至今為止他們並沒有能夠處理這個問題,儘管他們已經非常盡力了。對了,他們也表示他們“自己嘗試了不少次,但沒有能夠能夠找到一個好的並且能夠保持高效能的解決方案”。
我並不是說在JavaScript的基礎上建立一門具有較高記憶體效能的語言是不可能的,我只是想說很多證據顯示這個問題會非常難。
更新:一個Rust語言的貢獻者提到:
我為Rust專案工作,我的主要目標是實現零額外開銷的記憶體安全。我們通過“@-boxes”(@T宣告的型別是任何型別T)的方式來支援通過GC處理的物件,而我們最近遇到的比較麻煩的事情是,GC觸碰到語言中的所有內容。如果你想支援GC但卻不需要它,你就要非常仔細地設計你的語言來支援零額外開銷的非GC指標。這不是一個簡單的問題,我不認為可以通過建立在JS的基礎上建立一門新語言來解決。
OK,但是ASM.JS如何呢?
asm.js就比較有趣了,因為它提供了一個JavaScript模型,但這個模型嚴格意義上不是建立在垃圾回收的基礎上的。所以從理論上講,使用正確的網頁瀏覽器,使用正確的API就可以了。問題是,“我們會得到正確的瀏覽器嗎?”
Mozilla顯然在這個概念上被出賣了,作為這個技術的作者,他們的實現今年晚些時候實現了它。Chrome的反應一直是含糊不清的,因為這個技術顯然和Google的其它提案,包括Dart和PNaC1有直接的競爭關係。關於它有一個開發的bug清單,但是一個V8的黑客對此不滿意。至於Apple陣營,按照我現在看來,WebKit那群人對比完全保持沉默。IE?我從來就沒有抱任何希望。
無論如何,現在還不能說asm.js就是真正解決JavaScript問題,且能夠擊敗所有其它提案的方法。另外,如果它能做到,它真的不可能是JavaScript,畢竟它能夠可行的原因就是拋開了麻煩的垃圾回收器。所以它有可能和C/C++或者其它手動管理記憶體的語言的前端一起工作,但肯定不和我們現在知道並且喜歡的動態語言一樣。
相對什麼來說慢?
當一些文章裡面說“X慢”和“X不慢”的時候,一個問題是,沒有人真正說的清楚它們的參照系是什麼。對於一個網頁瀏覽器開發者,和對於一個高效能叢集的開發者,以及對於一個嵌入式系統的開發者,等等,“慢”的含義是不一樣的。既然我們已經闖過了戰壕而且做了這麼多benchmark,我可以給出你三個有用且大致正確的座標系。
如果你是一個Web開發者,把iPhone 4S的Nitro當做IE8來看,因為它們的benchmark成績差不多。這就給了你寫程式碼時的正確座標系。寫程式碼的時候應該謹慎地使用JS,否則你會面臨一大堆平臺相關的效能問題要處理。有些應用用JS來寫價效比是不高的,即使是流行的瀏覽器。
如果你是x86平臺上的C/C++開發者,把iPhone 4S的Web開發環境當成只有桌面開發環境效能的1/50。其中1/10來自於ARM相對於x86的效能差距,1/5來自於JavaScript相對於C/C++的效能差距。在非JavaScript、效能為桌面環境1/10的情況下,仔細考慮正反面的因素。
如果你是Java、Ruby、Python或者C#開發者,按照以下方式去理解iPhone 4S的Web開發環境:它的效能是你電腦的1/10(ARM的因素),並且如果你的記憶體使用超過35M,效能會指數級下降,這是由垃圾回收的工作方式決定的。還有,如果你的程式分配了超過213M的記憶體,程式就會崩潰。注意,沒有人“從設計的角度”在執行時刻給你這個資訊。對了,人們都希望你在這種環境下寫出很耗記憶體的照片處理和視訊應用。
這是一篇非常長的文章
下面是你應該記得的內容:
- 2013年,用JavaScript寫的移動應用(如照片編輯等)實在是太慢了。
- 比原生程式碼慢5倍
- 效能和IE8差不多
- 比x86平臺上的C/C++程式碼慢50倍
- 如果你的程式所有的記憶體不超過35M,比伺服器端的Java/Ruby/Python/C#慢10倍;如果記憶體使用超過這個數,效能開始指數級下降
- 要使這個速度變得快一些,最可能的方式是讓硬體效能達到桌面水平的效能。從長遠來看這是可行的,但是看起來要等很長時間。
- 最近一段時間JavaScript語言本身並沒有變得更快,在JavaScript上工作的人認為,在現有的語言和API下,它永遠不會向原生程式碼那麼快。
- 垃圾回收在記憶體受限的環境下會呈現指數級的效能下降,這一點比桌面和伺服器級別的情況差很多。
- 任何能幹的移動開發者都花很多時間來為目標裝置考慮記憶體效能問題,不管他們是否使用具有GC的環境。
- 當前的JavaScript,從本質上是和允許程式為目標裝置考慮記憶體效能問題這一點背道而馳的。
- 如果JavaScript的工作者們意識到這問題並且做出改變,允許開發者考慮記憶體問題,經驗表明這是技術上的難題。
- asm.js讓人看到了一些希望,但是就算它能成功,它應該是用了C/C++或者類似的“過時的”語言的前端,而不是像JavaScript這樣的前端。
讓我們提高爭論的層次
毫無疑問的一點是,我不久就將收到上百封郵件,這些郵件圈出我說的某句話,然後在不提供任何實際的證據(或者根本不能算是證據)的情況下,指出我說得不對。或者說“我曾經用JavaScript寫過一個文字編輯器,挺好”,或者說“有些我從來沒見過的人寫了一個飛行模擬器,但是從來沒有給我寫郵件說明他們遇到效能問題”,這些郵件我會一律刪除。
如果我們想要在移動Web開發(或者是原生應用,或者是任何其它事情)上取得一些進展,我們都需要各種至少看上去有說服力(at least appear to have a plausible basis)的討論,包括benchmark、期刊以及編譯器作者們的引用等等。網上有很多HN關於“我曾經寫了一個Web應用,挺好”的評論,還有很多關於Facebook在知道他們將會知道現在應該知道的東西的情況下(譯註:原文knowing what they would have known then what they could have known now,不知這樣翻譯對不對?)是選擇HTML5還是原生應用是對是錯的爭論(譯註:原文為bikeshedding,這是一個比較有意思的詞,意思是在還沒完成自行車車架還沒弄好的情況下就去討論車的顏色,意指過於關心細節和邊緣的問題,而忽視主要問題)。
對於我們來說,剩下來的任務是,明確地量化如何使得移動Web和原生生態環境變得越來越好,接著為此做出一些事情。正如你所知,這也是一個軟體開發者應該做的事情。
翻譯到此結束,翻譯過程前前後後花了4天的時候。當快回宿舍之前,終於可以放到部落格上去時,竟然感覺有些不可思議。謝謝大家支援!