引言
狹義的分散式系統指由網路連線的計算機系統,每個節點獨立地承擔計算或儲存任務,節點間通過網路協同工作。廣義的分散式系統是一個相對的概念,正如Leslie Lamport所說[1]:
What is a distributed systeme. Distribution is in the eye of the beholder.
To the user sitting at the keyboard, his IBM personal computer is a nondistributed system.
To a flea crawling around on the circuit board, or to the engineer who designed it, it's very much a distributed system.
一致性是分散式理論中的根本性問題,近半個世紀以來,科學家們圍繞著一致性問題提出了很多理論模型,依據這些理論模型,業界也出現了很多工程實踐投影。下面我們從一致性問題、特定條件下解決一致性問題的兩種方法(2PC、3PC)入門,瞭解最基礎的分散式系統理論。
一致性(consensus)
何為一致性問題?簡單而言,一致性問題就是相互獨立的節點之間如何達成一項決議的問題。分散式系統中,進行資料庫事務提交(commit transaction)、Leader選舉、序列號生成等都會遇到一致性問題。這個問題在我們的日常生活中也很常見,比如牌友怎麼商定幾點在哪打幾圈麻將:

《賭聖》,1990
假設一個具有N個節點的分散式系統,當其滿足以下條件時,我們說這個系統滿足一致性:
- 全認同(agreement): 所有N個節點都認同一個結果
- 值合法(validity): 該結果必須由N個節點中的節點提出
- 可結束(termination): 決議過程在一定時間內結束,不會無休止地進行下去
有人可能會說,決定什麼時候在哪搓搓麻將,4個人商量一下就ok,這不很簡單嗎?
但就這樣看似簡單的事情,分散式系統實現起來並不輕鬆,因為它面臨著這些問題:
- 訊息傳遞非同步無序(asynchronous): 現實網路不是一個可靠的通道,存在訊息延時、丟失,節點間訊息傳遞做不到同步有序(synchronous)
- 節點當機(fail-stop): 節點持續當機,不會恢復
- 節點當機恢復(fail-recover): 節點當機一段時間後恢復,在分散式系統中最常見
- 網路分化(network partition): 網路鏈路出現問題,將N個節點隔離成多個部分
- 拜占庭將軍問題(byzantine failure)[2]: 節點或當機或邏輯失敗,甚至不按套路出牌丟擲干擾決議的資訊
假設現實場景中也存在這樣的問題,我們看看結果會怎樣:
我: 老王,今晚7點老地方,搓夠48圈不見不散! …… (第二天凌晨3點) 隔壁老王: 沒問題! // 訊息延遲 我: …… ---------------------------------------------- 我: 小張,今晚7點老地方,搓夠48圈不見不散! 小張: No …… (兩小時後……) 小張: No problem! // 當機節點恢復 我: …… ----------------------------------------------- 我: 老李頭,今晚7點老地方,搓夠48圈不見不散! 老李: 必須的,大保健走起! // 拜占庭將軍
(這是要打麻將呢?還是要大保健?還是一邊打麻將一邊大保健……)
還能不能一起愉快地玩耍...
我們把以上所列的問題稱為系統模型(system model),討論分散式系統理論和工程實踐的時候,必先劃定模型。例如有以下兩種模型:
- 非同步環境(asynchronous)下,節點當機(fail-stop)
- 非同步環境(asynchronous)下,節點當機恢復(fail-recover)、網路分化(network partition)
2比1多了節點恢復、網路分化的考量,因而對這兩種模型的理論研究和工程解決方案必定是不同的,在還沒有明晰所要解決的問題前談解決方案都是一本正經地耍流氓。
一致性還具備兩個屬性,一個是強一致(safety),它要求所有節點狀態一致、共進退;一個是可用(liveness),它要求分散式系統24*7無間斷對外服務。FLP定理(FLP impossibility)[3][4] 已經證明在一個收窄的模型中(非同步環境並只存在節點當機),不能同時滿足 safety 和 liveness。
FLP定理是分散式系統理論中的基礎理論,正如物理學中的能量守恆定律徹底否定了永動機的存在,FLP定理否定了同時滿足safety 和 liveness 的一致性協議的存在。

《怦然心動 (Flipped)》,2010
工程實踐上根據具體的業務場景,或保證強一致(safety),或在節點當機、網路分化的時候保證可用(liveness)。2PC、3PC是相對簡單的解決一致性問題的協議,下面我們就來了解2PC和3PC。
2PC
2PC(tow phase commit)兩階段提交[5]顧名思義它分成兩個階段,先由一方進行提議(propose)並收集其他節點的反饋(vote),再根據反饋決定提交(commit)或中止(abort)事務。我們將提議的節點稱為協調者(coordinator),其他參與決議節點稱為參與者(participants, 或cohorts):

2PC, phase one
在階段1中,coordinator發起一個提議,分別問詢各participant是否接受。
2PC, phase two
在階段2中,coordinator根據participant的反饋,提交或中止事務,如果participant全部同意則提交,只要有一個participant不同意就中止。
在非同步環境(asynchronous)並且沒有節點當機(fail-stop)的模型下,2PC可以滿足全認同、值合法、可結束,是解決一致性問題的一種協議。但如果再加上節點當機(fail-recover)的考慮,2PC是否還能解決一致性問題呢?
coordinator如果在發起提議後當機,那麼participant將進入阻塞(block)狀態、一直等待coordinator迴應以完成該次決議。這時需要另一角色把系統從不可結束的狀態中帶出來,我們把新增的這一角色叫協調者備份(coordinator watchdog)。coordinator當機一定時間後,watchdog接替原coordinator工作,通過問詢(query) 各participant的狀態,決定階段2是提交還是中止。這也要求 coordinator/participant 記錄(logging)歷史狀態,以備coordinator當機後watchdog對participant查詢、coordinator當機恢復後重新找回狀態。
從coordinator接收到一次事務請求、發起提議到事務完成,經過2PC協議後增加了2次RTT(propose+commit),帶來的時延(latency)增加相對較少。
3PC
3PC(three phase commit)即三階段提交[6][7],既然2PC可以在非同步網路+節點當機恢復的模型下實現一致性,那還需要3PC做什麼,3PC是什麼鬼?
在2PC中一個participant的狀態只有它自己和coordinator知曉,假如coordinator提議後自身當機,在watchdog啟用前一個participant又當機,其他participant就會進入既不能回滾、又不能強制commit的阻塞狀態,直到participant當機恢復。這引出兩個疑問:
- 能不能去掉阻塞,使系統可以在commit/abort前回滾(rollback)到決議發起前的初始狀態
- 當次決議中,participant間能不能相互知道對方的狀態,又或者participant間根本不依賴對方的狀態
相比2PC,3PC增加了一個準備提交(prepare to commit)階段來解決以上問題:
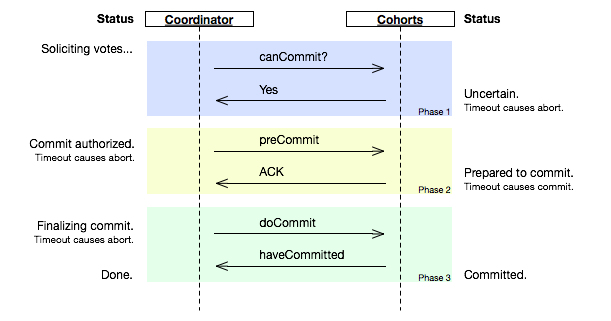
圖片擷取自wikipedia
coordinator接收完participant的反饋(vote)之後,進入階段2,給各個participant傳送準備提交(prepare to commit)指令。participant接到準備提交指令後可以鎖資源,但要求相關操作必須可回滾。coordinator接收完確認(ACK)後進入階段3、進行commit/abort,3PC的階段3與2PC的階段2無異。協調者備份(coordinator watchdog)、狀態記錄(logging)同樣應用在3PC。
participant如果在不同階段當機,我們來看看3PC如何應對:
- 階段1: coordinator或watchdog未收到當機participant的vote,直接中止事務;當機的participant恢復後,讀取logging發現未發出贊成vote,自行中止該次事務
- 階段2: coordinator未收到當機participant的precommit ACK,但因為之前已經收到了當機participant的贊成反饋(不然也不會進入到階段2),coordinator進行commit;watchdog可以通過問詢其他participant獲得這些資訊,過程同理;當機的participant恢復後發現收到precommit或已經發出贊成vote,則自行commit該次事務
- 階段3: 即便coordinator或watchdog未收到當機participant的commit ACK,也結束該次事務;當機的participant恢復後發現收到commit或者precommit,也將自行commit該次事務
因為有了準備提交(prepare to commit)階段,3PC的事務處理延時也增加了1個RTT,變為3個RTT(propose+precommit+commit),但是它防止participant當機後整個系統進入阻塞態,增強了系統的可用性,對一些現實業務場景是非常值得的。
小結
以上介紹了分散式系統理論中的部分基礎知識,闡述了一致性(consensus)的定義和實現一致性所要面臨的問題,最後討論在非同步網路(asynchronous)、節點當機恢復(fail-recover)模型下2PC、3PC怎麼解決一致性問題。
閱讀前人對分散式系統的各項理論研究,其中有嚴謹地推理、證明,有一種數學的美;觀現實中的分散式系統實現,是綜合各種因素下妥協的結果。
[1] Solved Problems, Unsolved Problems and Problems in Concurrency, Leslie Lamport, 1983
[2] The Byzantine Generals Problem, Leslie Lamport,Robert Shostak and Marshall Pease, 1982
[3] Impossibility of Distributed Consensus with One Faulty Process, Fischer, Lynch and Patterson, 1985
[4] FLP Impossibility的證明, Daniel Wu, 2015
[5] Consensus Protocols: Two-Phase Commit, Henry Robinson, 2008
[6] Consensus Protocols: Three-phase Commit, Henry Robinson, 2008
[7] Three-phase commit protocol, Wikipedia