在前面幾篇文章中都是在講倒排索引的結構, 及合併優化方法. 這篇博文裡更多談下怎麼根據輸輸入查詢引數來定位到倒排記錄表的指標. 其實這跟MySQL中對VARCHAR型別加索引後, 然後基於該欄位查詢的原理一樣, 都是可以基於B-Tree的經典資料結構來快速定位. MySQL中基於記憶體表還可以用hash索引, 同樣資訊檢索技術中也可以用這種方式, 但是基於hash函式的有個缺點是它不能進行字首模糊查詢, 比如查詢hell*, 以hell開頭的關鍵字. 原因很簡單, 因為凡是兩個關鍵字只要有一點不同, 最終通過雜湊計算後的結果都可以是截然不同的. 所以用得最多的還是基於樹的結構. 關於B-Tree的資料結構及操作演算法, 可以google到很多介紹文章, 就不說了. 這裡討論下兩個問題: 一是萬用字元查詢, 我們前面說過字首查詢比較簡單, 但是如果萬用字元不在結尾, 比如he*o, 或者*red, 這在B-Tree裡是無法做直接做到的. 第二個問題: 我們經常搜尋查詢詞時拼寫錯誤, 比如我就經常在google中搜尋lucene但是卻打入的lucence, 這時候google會自動識別我是否想真正想要查詢的是lucene, 這就是拼寫校正技術. 下面詳細討論這兩點.
萬用字元查詢(general wildcard queries)
我們在基於資料庫(MySQL)的應用開發時, 對於欄位的模糊查詢, 我們一般建議產品需求是隻能滿足字首查詢, 如trian*, 如果需求非要做到也能字尾查詢, 如*orgal, 這時候我們一般會在表中冗餘一個欄位, 此欄位是對原欄位按照完全相反的字元展示順序儲存, 比如原欄位中儲存的是hello, 那麼冗餘欄位中儲存的就是olleh, 這樣使用者如果是字首模糊查詢就按原欄位比較查詢, 如果是字尾查詢, 就按冗餘的欄位查詢. 而在資訊檢索中一樣可以這樣來做, 我們的詞典完全可以冗餘一個反序的詞典表, 專門用來做字尾查詢. 這時聰明的你肯定會想到, 對於萬用字元在中間的查詢的做法, 如查詢dic*ary, 我們可以通過字首查詢dic*和字尾查詢yra*, 然後取交集, 就是我們所想滿足的所有詞. 這種基於兩個B樹結構的交集運算, 就像MySQL中的索引合併(Index Merge)一樣.
輪排索引(Permuterm Indexes)
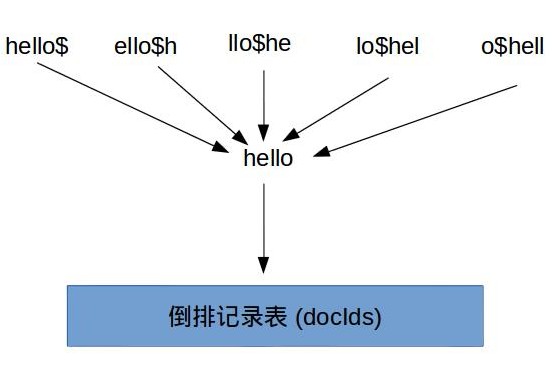
什麼叫輪排, 舉個例子, 如果對於詞項hello來說, 我們會同時生成hello$, ello$h, llo$he, lo$hel, o$hell, 它們都指向原始詞項hello. 這樣假如我們現在要查詢he*o時, 我們只要在該查詢關鍵字後面加上$然後旋轉到*出現在最後面, 得到o$he*, 然後在輪排詞典中字首查詢, 就可以查詢得到到所以對應的原始詞項, 繼而可以根據這些詞項定位到倒排記錄表的指標.
K-gram索引
輪排索引的缺點顯而易見, 就是會使輪排詞典變得很大. 就像上面舉的例子, 如果一個詞項由n的字母組成, 通過旋轉會產生n個詞項. 這種儲存增長很恐怖的. k-gram索引的原理很簡單, 這裡面的k是代表數量, 可是是2, 也可以是3. 比如hello會被拆解成$he, hel, ell, llo, lo$. 這樣我們如果查詢he*lo, 只要在分解後的K-gram記典中找$he和lo$對應的原始詞項, 並定位到它們的倒排記錄表進行相交運算即可.

K-gram相比倒排索引, 雖然一個詞項也會產生多個輔助詞項, 但是因為k的粒度問題, 使每個gram的重用率很高.
這裡要注意的是, 無論是輪排索引, 還是K-gram索引, 查詢出來的原始詞項都有可能不是我們想要的詞項. 但是我們可以通過初步篩選出來的詞項集合(數量很少)再次做進一步的篩選.
拼寫較正(Spelling Collection)
我們在輸入查詢詞, 經常不確定或者記錯, 導致輸入和實際想要的看起來相似, 但是又是錯誤的, 比如:

這裡用到的技術就是要計算兩個詞的相異程度, 專業的術語叫做編輯距離(edit distance). 編輯距離最早由俄羅斯科學家Levenshtein於1965年提出, 具體的演算法則是1974由Wagner和Fischer提出. 這裡我們來詳細討論下.
兩個單詞s1, s2的差距, 可以這樣來理解: 把s1變成s2要經過多少步驟. 比如把"kitten" 變成"sitting", 要經過下面三步:
- kitten -> sitten (把k替換成s)
- sitten -> sittin (把e替換成i)
- sittin -> sitting (在後面加上g)
所以kitten和sitting的編輯距離是3. 這裡用python寫出這個核心演算法:
def edit_distance(s1, s2):
m = len(s1)
n = len(s2)
d = [[0 for j in range(n + 1)] for i in range(m + 1)] # 先初始化一個二維資料, d[i][j]表示s1的前i個字元組成的字串和s2前j個字元組成的字串的編輯距離
for i in range(m + 1): # 初始化d[i][0]為i. 這點很容易理解, s1的第i個字元轉變成空白字串(j=0), 只要去掉i個字元就可以了, 所以運算元是i
d[i][0] = i
for j in range(n + 1): # 初始化d[0][j]為j, 和上面一樣, s2第j個字元之前組成的串變成空白字串(i=0), 只要去掉j個字元就可以了, 所以運算元是j
d[0][j] = j
for i in range(m):
for j in range(n):
if s1[i] == s2[j]: # 如果s1的第i的字元等於s2的第j個字元, 那麼這一步操作就不用做, 所以編輯距離就是s1的第i-1個字元和s2的第j-1個字元的編輯距離
d[i+1][j+1] = d[i][j]
else:
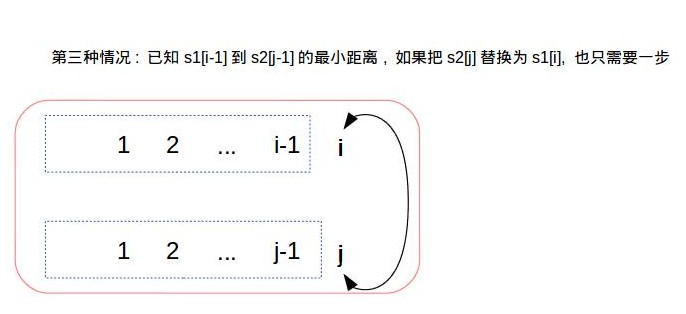
d[i+1][j+1] = min(d[i][j+1] + 1, d[i+1][j] + 1, d[i][j] + 1) # 在基於前面一步的基礎上, 把s1刪除一個字元, 或者把s2插入一個字元, 或者把s2的第j個字元替換成s1的第i個字元
print 'the edit distance is %s' % d[m][n]這裡比較不好理解的是最後一段的程式碼, 核心是用到動態規劃的思想, 這裡畫個圖理解下: