Hadoop之HDFS
版權宣告:本文為yunshuxueyuan原創文章。
如需轉載請標明出處: http://www.cnblogs.com/sxt-zkys/
QQ技術交流群:299142667
HDFS介紹
HDFS(Hadoop Distributed File System )Hadoop分散式檔案系統。是根據google發表的論文翻版的。
什麼是分散式檔案系統
分散式檔案系統(Distributed File System)是指檔案系統管理的物理儲存資源不一定直接連線在本地節點上,而是通過計算機網路與節點相連。分散式檔案系統的設計基於客戶機/伺服器模式。
[優點]
支援超大檔案 超大檔案在這裡指的是幾百M,幾百GB,甚至幾TB大小的檔案。
檢測和快速應對硬體故障在叢集的環境中,硬體故障是常見的問題。因為有上千臺伺服器連線在一起,這樣會導致高故障率。因此故障檢測和自動恢復是hdfs檔案系統的一個設計目標
流式資料訪問應用程式能以流的形式訪問資料集。主要的是資料的吞吐量,而不是訪問速度。
簡化的一致性模型 大部分hdfs操作檔案時,需要一次寫入,多次讀取。在hdfs中,一個檔案一旦經過建立、寫入、關閉後,一般就不需要修改了。這樣簡單的一致性模型,有利於提高吞吐量。
[缺點]
低延遲資料訪問如和使用者進行互動的應用,需要資料在毫秒或秒的範圍內得到響應。由於hadoop針對高資料吞吐量做了優化,犧牲了獲取資料的延遲,所以對於低延遲來說,不適合用hadoop來做。
大量的小檔案Hdfs支援超大的檔案,是通過資料分佈在資料節點,資料的後設資料儲存在名位元組點上。名位元組點的記憶體大小,決定了hdfs檔案系統可儲存的檔案數量。雖然現在的系統記憶體都比較大,但大量的小檔案還是會影響名位元組點的效能。
多使用者寫入檔案、修改檔案Hdfs的檔案只能有一次寫入,不支援寫入,也不支援修改。只有這樣資料的吞吐量才能大。
不支援超強的事務沒有像關係型資料庫那樣,對事務有強有力的支援。
[HDFS結構]
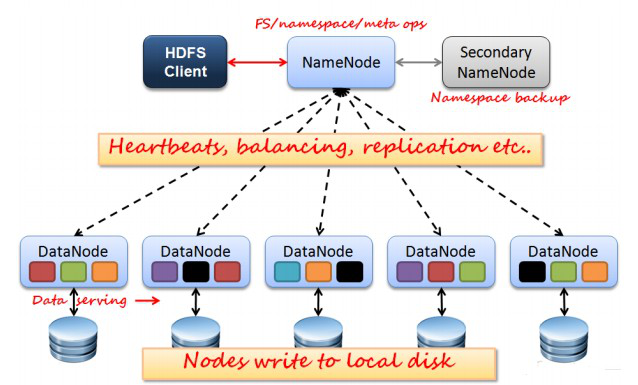
NameNode:分散式檔案系統中的管理者,主要負責管理檔案系統的名稱空間、叢集配置資訊和儲存塊的複製等。NameNode會將檔案系統的Meta-data儲存在記憶體中,這些資訊主要包括了檔案資訊、每一個檔案對應的檔案塊的資訊和每一個檔案塊在DataNode的資訊等。
SecondaryNameNode:合併fsimage和fsedits然後再發給namenode。
DataNode:是檔案儲存的基本單元,它將Block儲存在本地檔案系統中,儲存了Block的Meta-data同時週期性地將所有存在的Block資訊傳送給NameNode。
Client:就是需要獲取分散式檔案系統檔案的應用程式。
fsimage:後設資料映象檔案(檔案系統的目錄樹。)
edits:後設資料的操作日誌(針對檔案系統做的修改操作記錄)
NameNode、DataNode和Client之間通訊方式:
client和namenode之間是通過rpc通訊;
datanode和namenode之間是通過rpc通訊;
client和datanode之間是通過簡單的socket通訊。
Client讀取HDFS中資料的流程
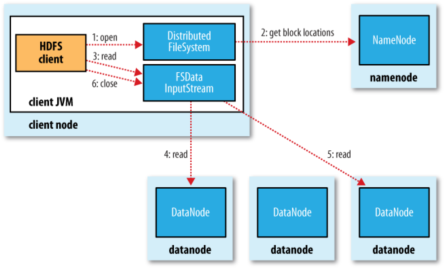
1. 客戶端通過呼叫FileSystem物件的open()方法開啟希望讀取的檔案。
2. DistributedFileSystem通過使用RPC來呼叫namenode,以確定檔案起始塊的位置。[注1]
3. Client對輸入流呼叫read()方法。
4. 儲存著檔案起始塊的natanoe地址的DFSInputStream[注2]隨即連結距離最近的datanode。通過對資料流反覆呼叫read()方法,可以將資料從datanode傳輸到Client。[注3]
5. 到達快的末端時,DFSInputStream會關閉與該datanode的連線,然後尋找下一個快遞最佳datanode。
6. Client讀取資料是按照卡開DFSInputStream與datanode新建連線的順序讀取的。它需要詢問namenode來檢索下一批所需要的datanode的位置。一旦完成讀取,呼叫FSDataInputStream呼叫close()方法。
[注1]:對於每一個塊,namenode返回存在該塊副本的datanode地址。這些datanode根據他們於客戶端的距離來排序,如果客戶端本身就是一個datanode,並儲存有響應資料塊的一個副本時,該節點從本地datanode中讀取資料。
[注2]:Di是tribute File System類返回一個FSDataInputStream物件給Client並讀取資料。FSDataInputStream類轉而封裝DFSInputStream物件,該物件管理datanode和namenode的I/O。
[注3]:如果DFSInputStream在與datanode通訊時遇到錯誤,它便會嘗試從這個塊的另外一個最臨近datanode讀取資料。它也會記住哪個故障的natanode,以保證以後不回反覆讀取該節點上後續的塊。DFSInputStream也會通過校驗和確認從datanode發來的資料是否完整。如果發現一個損壞的塊,它就會在DFSinputStream檢視從其他datanode讀取一個塊的副本之前通知namenode。
Client將資料寫入HDFS流程
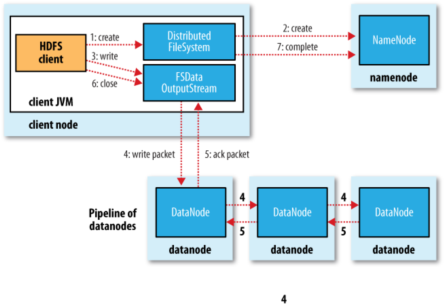
1. Client呼叫DistributedFileSystem物件的create()方法,建立一個檔案輸出流
2. DistributedFileSystem對namenode建立一個RPC呼叫,在檔案系統的名稱空間中建立一個新檔案。
3. Namenode執行各種不同的檢查以確保這個檔案不存在,並且客戶端有建立該檔案的許可權。如果這些檢查均通過,namenode就會為建立新檔案記錄一條記錄,否則,檔案建立失敗,向Client丟擲IOException,DistributedFileSystem向Client返回一個FSDataOutputStream隊形,Client可以開始寫入資料。
4. DFSOutputStream將它分成一個個的資料包,並寫入內部佇列。DataStreamer處理資料佇列,它的責任時根據datanode列表來要求namenode分配適合新塊來儲存資料備份。這一組datanode構成一個管線---我們假設副本數為3,管路中有3個節點,DataStreamer將資料包流式床書到管線中第一個datanode,該dananode儲存資料包並將它傳送到管線中的第二個datanode,同樣地,第二個datanode儲存該資料包並且傳送給管縣中的第3個。
5. DFSOutputStream也維護著一個內部資料包佇列來等待datanode的收到確認回執(ack queue)。當收到管道中所有datanode確認資訊後,該資料包才會從確認佇列刪除。[注1]
6. Client完成資料的寫入後,回對資料流呼叫close()方法
7. 將剩餘所有的資料包寫入datanode管線中,並且在練習namenode且傳送檔案寫入完成訊號之前。
[注1]:如果在資料寫入期間,datanode發生故障,則:1.關閉管線,確認把佇列中的任何資料包新增回資料佇列的最前端,一去到故障節點下游的datanode不回漏包。2.為儲存在另一個正常datanode的當前資料塊指定一個新的標誌,並將給標誌傳給namenode,以便故障datanode在恢復後可以刪除儲存的部分資料塊。3.從管線中刪除故障資料節點,並且把餘下的資料塊寫入管線中的兩個正常的datanode。namenode注意到副本量不足時,會在另一個節點上建立一個新的副本。
Hadoop中NameNode單點故障解決方案
Hadoop 1.0核心主要由兩個分支組成:MapReduce和HDFS,這兩個系統的設計缺陷是單點故障,即MR的JobTracker和HDFS的NameNode兩個核心服務均存在單點問題,這裡只討論HDFS的NameNode單點故障的解決方案。
[問題]
HDFS仿照google GFS實現的分散式儲存系統,由NameNode和DataNode兩種服務組成,其中NameNode是儲存了後設資料資訊(fsimage)和操作日誌(edits),由於它是唯一的,其可用性直接決定了整個儲存系統的可用性。因為客戶端對HDFS的讀、寫操作之前都要訪問name node伺服器,客戶端只有從name node獲取後設資料之後才能繼續進行讀、寫。一旦NameNode出現故障,將影響整個儲存系統的使用。
[解決方案]
Hadoop官方提供了一種quorum journal manager來實現高可用,在高可用配置下,edit log不再存放在名稱節點,而是存放在一個共享儲存的地方,這個共享儲存由若干Journal Node組成,一般是3個節點(JN小叢集), 每個JN專門用於存放來自NN的編輯日誌,編輯日誌由活躍狀態的名稱節點寫入。
要有2個NN節點,二者之中只能有一個處於活躍狀態(active),另一個是待命狀態(standby),只有active節點才能對外提供讀寫HDFS服務,也只有active態的NN才能向JN寫入編輯日誌;standby的名稱節點只負責從JN小叢集中的JN節點拷貝資料到本地存放。另外,各個DATA NODE也要同時向兩個NameNode節點報告狀態(心跳資訊、塊資訊)。
一主一從的2個NameNode節點同時和3個JN構成的組保持通訊,活躍的NameNode節點負責往JN叢集寫入編輯日誌,待命的NN節點負責觀察JN組中的編輯日誌,並且把日誌拉取到待命節點(接管Secondary NameNode的工作)。再加上兩節點各自的fsimage映象檔案,這樣一來就能確保兩個NN的後設資料保持同步。一旦active不可用,standby繼續對外提供服。架構分為手動模式和自動模式,其中手動模式是指由管理員通過命令進行主備切換,這通常在服務升級時有用,自動模式可降低運維成本,但存在潛在危險。這兩種模式下的架構如下。
[手動模式]
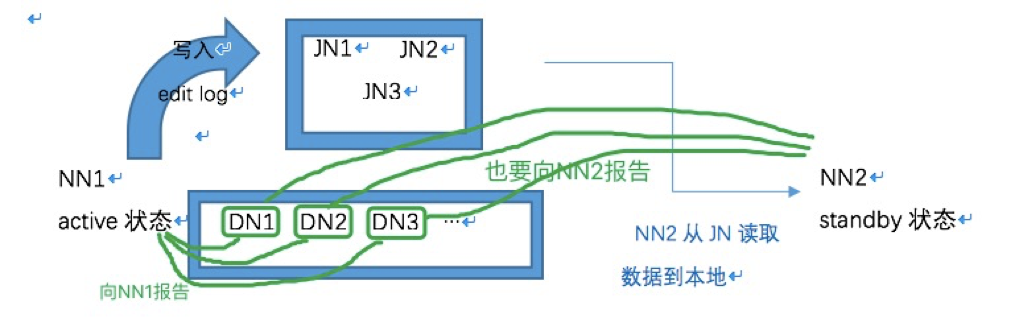
模擬流程:
1. 準備3臺伺服器分別用於執行JournalNode程式(也可以執行在date node伺服器上),準備2臺namenode伺服器用於執行NameNode程式(兩臺配置 要一樣),DataNode節點數量不限。
2. 分別啟動3臺JN伺服器上的JournalNode程式,分別在date node伺服器啟動DataNode程式。
3. 需要同步2臺name node之間的後設資料。具體做法:從第一臺NN拷貝後設資料到放到另一臺NN,然後啟動第一臺的NameNode程式,再到另一臺名稱節點上做standby引導。
4. 把第一臺名節點的edit日誌初始化到JN節點,以供standby節點到JN節點拉取資料。
5. 啟動standby狀態的NameNode節點,這樣就能同步fsimage檔案。
6. 模擬故障,手動把active狀態的NN故障,轉移到另一臺NameNode。
[自動模式]
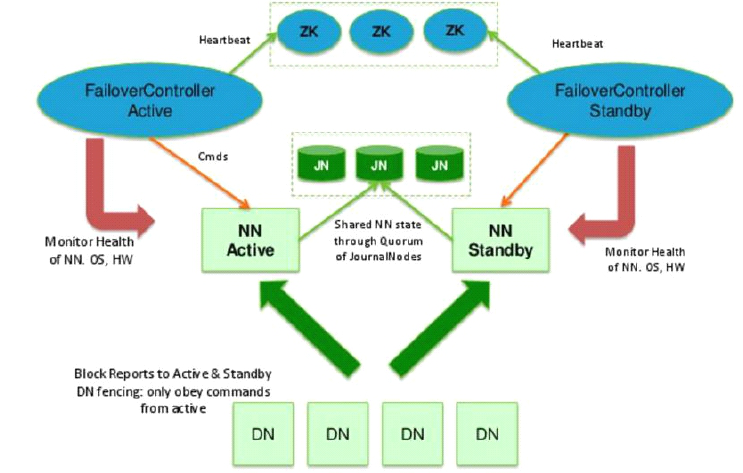
模擬流程:
在手動模式下引入了ZKFC(DFSZKFailoverController)和zookeeper叢集
ZKFC主要負責: 健康監控、session管理、leader選舉
zookeeper叢集主要負責:服務同步
1-6步同手動模式
7. 準備3臺主機安裝zookeeper,3臺主機形成一個小的zookeeper叢集.
8. 啟動ZK叢集每個節點上的QuorumPeerMain程式
9. 登入其中一臺NN, 在ZK中初始化HA狀態
10. 模擬故障:停掉活躍的NameNode程式,提前配置的zookeeper會把standby節點自動變為active,繼續提供服務。
腦裂
腦裂是指在主備切換時,由於切換不徹底或其他原因,導致客戶端和Slave誤以為出現兩個active master,最終使得整個叢集處於混亂狀態。解決腦裂問題,通常採用隔離(Fencing)機制。
共享儲存fencing:確保只有一個Master往共享儲存中寫資料,使用QJM實現fencing。
Qurom Journal Manager,基於Paxos(基於訊息傳遞的一致性演算法),Paxos演算法是解決分散式環境中如何就某個值達成一致。
[原理]
a. 初始化後,Active把editlog日誌寫到JN上,每個editlog有一個編號,每次寫editlog只要其中大多數JN返回成功(過半)即認定寫成功。
b. Standby定期從JN讀取一批editlog,並應用到記憶體中的FsImage中。
c. NameNode每次寫Editlog都需要傳遞一個編號Epoch給JN,JN會對比Epoch,如果比自己儲存的Epoch大或相同,則可以寫,JN更新自己的Epoch到最新,否則拒絕操作。在切換時,Standby轉換為Active時,會把Epoch+1,這樣就防止即使之前的NameNode向JN寫日誌,也會失敗。
客戶端fencing:確保只有一個Master可以響應客戶端的請求。
[原理]
在RPC層封裝了一層,通過FailoverProxyProvider以重試的方式連線NN。通過若干次連線一個NN失敗後嘗試連線新的NN,對客戶端的影響是重試的時候增加一定的延遲。客戶端可以設定重試此時和時間
Slave fencing:確保只有一個Master可以向Slave下發命令。
[原理]
a. 每個NN改變狀態的時候,向DN傳送自己的狀態和一個序列號。
b. DN在執行過程中維護此序列號,當failover時,新的NN在返回DN心跳時會返回自己的active狀態和一個更大的序列號。DN接收到這個返回是認為該NN為新的active。
b. 如果這時原來的active(比如GC)恢復,返回給DN的心跳資訊包含active狀態和原來的序列號,這時DN就會拒絕這個NN的命令。
最後在此感謝尚學堂周老師在我學習過程中給予的幫助。
版權宣告:本文為yunshuxueyuan原創文章。
如需轉載請標明出處: http://www.cnblogs.com/sxt-zkys/
QQ技術交流群:299142667