一、基本語句優化
1.儘量避免在列上進行運算,這樣會導致索引失敗。例如:
select * from table where DATE_FORMAT(`customer_regtime`,'%Y')>='2010'
優化為
select * from table where customer_regtime>='2010-01-01'
2.在使用join時,應該根據功能的需要儘量使用小結果集驅動大結果集。同時把複雜的join查詢拆分成多個query。因為join多表時,可能導致更多的鎖定和堵塞。
3.僅列出需要的欄位,這對查詢速度沒有影響,但是對記憶體可以節省很多。例如:
select * from customer;
優化為
select customer_id,customer_name from customer;
4.使用批量插入時節省互動例如:
insert into a1(name) values('name1');
insert into a1(name) values('name2');
insert into a1(name) values('name3');
insert into a1(name) values('name4');
優化為:
insert into a1(name) values('name1'),('name2'),('name3'),('name4');
5.limit 的基數比較大時,可以使用where between 或其他方式代替。
6.不要使用rand函式獲取多條隨機資料例如:
select * from a2 order by rand() limit 20;
可以使用php引數隨機數使用 mysql in 查詢 。
7.避免使用null
8.不要使用count(id),因該使用count(*)
9.不要做無謂的排序操作,儘可能的在索引中完成。
二、索引與效能分析
檢視sql執行的效率可以通過開始 profiling 來檢視
set profiling =1;
開啟後執行sql語句mysql就會分析執行該sql 的詳細報告
例如 多執行幾遍
select * from a2;
然後 檢視
show profiles;
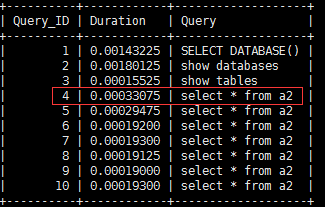
第一次用時是最長的比後面的時間變多了幾乎一倍,這是因為mysql快取了查詢。
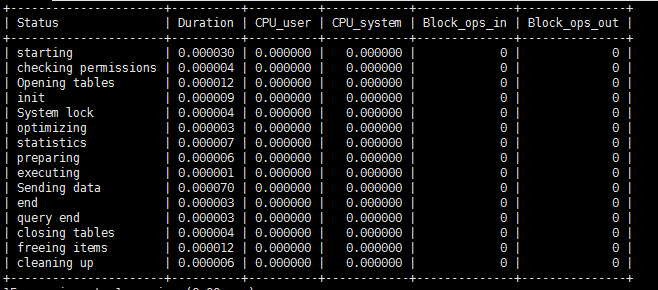
如果需要檢視某一個語句的細節可以使用
show profile cpu,block io for query 4;
結果為:
檢視select 語句在執行過程中是否用到索引,如果是聯合查詢時聯合的順序型別等資訊可以使用explain
explain select * from a2;
結果為:

個屬性含有如下
id:查詢序列號
select_type:查詢的型別,主要包括普通查詢,聯合查詢、子查詢。
table:查詢的表明。
type:聯合查詢使用的型別。
possible_keys:表示mysql能使用哪個索引在該表中找到該行。如果這個值是空就表示沒有用到索引,可以通過檢查where子句,看看是否引用了某些欄位。
key:顯示mysql實際決定使用的鍵。如果沒有索引被應用則為空。
key_len:顯示mysql決定使用的鍵長度。如果鍵是null這個也是null。這個值反應出一個多重主鍵裡實際使用了哪部分。
ref:顯示哪個欄位或常數與key一起被使用。
rows:這個值表示mysql要便利多少資料才能找到需要的結果集,在innodb上不準確。
extra:如果是 only index,意味著資訊只能用索引樹中的資訊檢索,這比掃描整個表要快,如果是where used,則表示使用了where 限制,但是用索引還不夠,如果是impossi-ble where,則表示通過收集到的統計資訊判斷出不可能存在的結果。除此之外,extra還有下面一些可能值:using filesort:表示包含orderby 且無法使用索引進行排序操作時,不得不使用相應的排序演算法實現。using temporary:使用臨時表,常見於orderby和group by。select tables optimized way:使用聚合函式,並且mysql進行了快速定位。通常是max,min,count(*) 等函式。
type特別說明:type顯示的訪問型別是較重要的指標:結果重好到壞一次是:system(系統表),const(讀常量),eq_tef(最大一條比配結果,通常是通過主鍵訪問),ref(被驅動表索引引用),fulltext(全文索引檢索),ref_of_null(帶空值的索引查詢),index_merge(合併索引結果集),unique_subquery(子查詢中返回的欄位是唯一組合或索引),index_subquery(子查詢返回的是索引,但非主鍵),range(索引範圍掃描),index(全索引燒苗),all(全表掃描)。
一般來說,保證查詢至少range級,最好能達到ref級。all為全表掃描,是最壞的情況,表示沒有用到索引。
索引的建立和使用原則:
合理設計和使用索引。
在關鍵欄位的索引上,建與不建索引,查詢數度相差近100倍。
差的索引和沒有索引想過一樣。
索引並非越多越好,因為維護需要成本。
每個表的索引在5個一下,應合理利用部分索引和聯合索引。
不在結果集中的結果單一的列上建立索引。比如性別欄位只有0和1兩種結果,在這個欄位上建立索引不會有太大的幫助。
建索引的欄位結果集最好分佈均勻,或者符合正態分佈。