從XML檔案亂碼問題,探尋其背後的原理
原文連結:http://blog.csdn.net/dinglang_2009/article/details/6895355
在日常開發工作中,我們經常會使用到XML,早已成為了一種標準。它的用途非常的廣泛,但這些不是本文所重點討論的。
相信大家在做開始時候經常碰到過“亂碼”的問題,這是中國程式設計師非常頭疼的問題。我一直很想深入研究關於“編碼”的原理,無奈水平有限,那些枯燥的理論(二進位制,ASCII,Unicode,UTF-8,gb2312,ISO ...光這些就讓我看的兩眼發黑了),實在看不下去,也很難真正搞懂搞明白。望各位網友多指點......
我將用工作中遇到的一個“XML檔案亂碼”的簡單問題,解決問題,分析其背後的原理。
首先,我們在本地新建一個文字檔案,將字尾名改為".XML”, 然後用用記事本開啟,往裡面新增一些符合XML文件規範的內容。如圖所示:
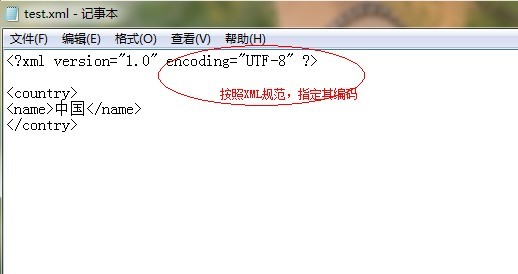
寫好之後,按“ctrl+s”儲存,然後使用IE瀏覽器開啟該XML檔案,驗證該XML文件的規範及正確性。不料,居然解析出錯了,如下:

這是咋回事呢?我的XML文件定義的格式好像沒問題啊。無效字元?這肯定是典型的“編碼”問題了。聰明的我第一就想到了,調整IE瀏覽器的“編碼”嘛。
可是開啟“檢視”“編碼”,發現那些編碼格式全是灰色的,好像不能選擇哦。這是因為,在定義XML文件的時候,指定了編碼格式為"UTF-8",這就相當於告訴了瀏覽器(XML解析引擎):你必須使用"UTF-8"編碼去解析我,所以無法使用其他的編碼格式去檢視了。
這是因為,我們在使用記事本儲存該文件的時候,沒有選擇編碼格式,預設使用的是作業系統編碼(中文版的系統),也就是對應的"GB2312”編碼。當我們的IE瀏覽器,再使用我們指定的UTF-8編碼去解析該XML文件的時候,出現了亂碼,所以造成了上面的錯誤。(Windows中的檔案儲存在硬碟上,預設使用作業系統編碼。比如我們XML文件中定義的“中國”這兩個字,儲存好後,假如其對應的GB2312可能是"10001",而在UTF-8編碼中的,“10001”對應的就不是“中國”了,要麼找不到,要麼是亂碼,所以IE就拒絕顯示了)。那我們應該怎麼辦呢?有兩種辦法可以解決。
第一,我們在xml文件定義時,指定其編碼為gb2312,如下圖所示:
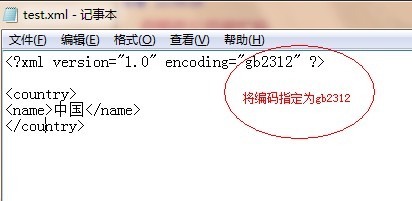
儲存之後,我們再使用IE瀏覽器開啟,結果如圖:
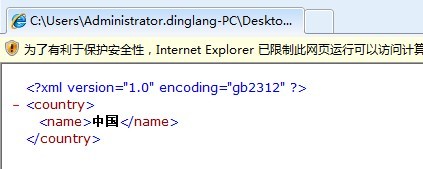
恭喜,這個問題解決了。但是這種方法不推薦使用。因為我們在定義XML文件時候,為了文件的通用性,我們一般使用UTF-8編碼。
第二種方法:
我們再用記事本開啟該文件,點選“另存為”,發現下面會有“編碼”選項,選擇“UTF-8”之後再試。
其實,我們在使用諸如 Eclipse 或者Microsoft Visual Studio之類的開發工具來定義XML文件,並不會碰到上面的問題。原因是這些IDE都非常“聰明”,你的XML文件指定的是那種編碼格式,IDE在將XML文件儲存到硬碟的時候,就自動使用那種格式。所以,很多侷限於使用某種IDE開發的程式設計師,其實並不明白這些知識及其背後的原理,但他們做開發起來一樣很順手。早年據筆者瞭解,國內有很多大牛,寫程式碼都是用EditPlus之類的文字編輯器,而那些在Linux/unix上面的大牛,很多都是用VI/VIM來編碼。大概這就是差距吧。(呵呵。當然這不是本文討論的重點)
補充一點理論知識,不暈的就繼續讀下去吧。
在最初的時候,Internet上只有一種字符集——ANSI的ASCII字符集,它使用7 bits來表示一個字元,總共表示128個字元,其中包括了英文字母、數字、標點符號等常用字元。之後,又進行擴充套件,使用8 bits表示一個字元,可以表示256個字元,主要在原來的7 bits字符集的基礎上加入了一些特殊符號例如製表符。
後來,由於各國語言的加入,ASCII已經不能滿足資訊交流的需要,因此,為了能夠表示其它國家的文字,各國在ASCII的基礎上制定了自己的字符集,這些從ANSI標準派生的字符集被習慣的統稱為ANSI字符集,它們正式的名稱應該是MBCS(Multi-Byte Chactacter System,即多位元組字元系統)。這些派生字符集的特點是以ASCII 127 bits為基礎,相容ASCII 127,他們使用大於128的編碼作為一個Leading Byte,緊跟在Leading Byte後的第二(甚至第三)個字元與Leading Byte一起作為實際的編碼。這樣的字符集有很多,我們常見的GB-2312就是其中之一。
而其UTF-8編碼為:E8 BF 9E E9 80 9A
開頭位元組 Charset/encoding
EF BB BF UTF-8
FE FF UTF-16/UCS-2, little endian
FF FE UTF-16/UCS-2, big endian
FF FE 00 00 UTF-32/UCS-4, little endian.
00 00 FE FF UTF-32/UCS-4, big-endian.
例如插入標記後,連通”兩個字的UTF-16 (big endian)和UTF-8碼分別為:
FF FE DE 8F 1A 90
EF BB BF E8 BF 9E E9 80 9A
但是MBCS文字沒有這些位於開頭的字符集標記,更不幸的是,一些早期的和一些設計不良的軟體在儲存Unicode文字時不插入這些位於開頭的字符集標記。因此,軟體不能依賴於這種途徑。這時,軟體可以採取一種比較安全的方式來決定字符集及其編碼,那就是彈出一個對話方塊來請示使用者,例如將那個“連通”檔案拖到MS Word中,Word就會彈出一個對話方塊。
如果軟體不想麻煩使用者,或者它不方便向使用者請示,那它只能採取自己“猜”的方法,軟體可以根據整個文字的特徵來猜測它可能屬於哪個charset,這就很可能不準了。使用記事本開啟那個“連通”檔案就屬於這種情況。
我們可以證明這一點:在記事本中鍵入“連通”後,選擇“Save As”,會看到最後一個下拉框中顯示有“ANSI”,這時儲存。當再當開啟“連通”檔案出現亂碼後,再點選“File”->“Save As”,會看到最後一個下拉框中顯示有“UTF-8”,這說明記事本認為當前開啟的這個文字是一個UTF-8編碼的文字。而我們剛才儲存時是用ANSI字符集儲存的。這說明,記事本猜測了“連通”檔案的字符集,認為它更像一個UTF-8編碼文字。這是因為“連通”兩個字的GB-2312編碼看起來更像UTF-8編碼導致的,這是一個巧合,不是所有文字都這樣。可以使用記事本的開啟功能,在開啟“連通”檔案時在最後一個下拉框中選擇ANSI,就能正常顯示了。反過來,如果之前儲存時儲存為UTF-8編碼,則直接開啟也不會出現問題。
如果將“連通”檔案放入MS Word中,Word也會認為它是一個UTF-8編碼的檔案,但它不能確定,因此會彈出一個對話方塊詢問使用者,這時選擇“簡體中文(GB2312)”,就能正常開啟了。記事本在這一點上做得比較簡化罷了,這與這個程式的定位是一致的。
相關文章
- 深度揭祕亂碼問題背後的原因及解決方式
- 框架雖好,但不要丟了其背後的原理框架
- 【問題】 檔案搜尋
- Java讀取文字檔案中文亂碼問題Java
- linux下zip檔案解壓亂碼的問題Linux
- jsp中的rar檔案連線亂碼問題JS
- Stable Diffusion解析:探尋AI繪畫背後的科技神秘AI
- 解決excel開啟.csv檔案亂碼問題Excel
- Java 讀檔案寫檔案 韓文 中文 亂碼問題解決方案Java
- jaxb輸出xml檔案的中文問題?XML
- 關於SAX解析xml檔案的問題XML
- 解決PHP匯出CSV檔案中文亂碼問題PHP
- 解決java web中safari瀏覽器下載後檔案中文亂碼問題JavaWeb瀏覽器
- asp.net中引入外部js檔案的中文亂碼問題ASP.NETJS
- Tomcat中文亂碼問題的原理和解決方法Tomcat
- 火星探測器背後的人工智慧:從原理到實戰的強化學習人工智慧強化學習
- 探討AIGC的崛起歷程,淺析其背後技術發展AIGC
- confluence上傳檔案附件預覽亂碼問題
- 引入外部js檔案導致亂碼問題解決方案JS
- MySQL直接匯出CSV檔案,並解決中文亂碼的問題MySql
- Java Web後臺從request裡面獲取的資料是亂碼問題JavaWeb
- XML檔案處理中增加xmlns問題XML
- 求救!Jive的工程檔案在JB7/9中亂碼的問題
- libreoffice轉換檔案為pdf檔案亂碼問題解決辦法
- 解決Intellij IDEA中執行緩慢的問題,tomcat控制檯列印亂碼問題,國際化亂碼配置檔案亂碼解決IntelliJIdeaTomcat
- 【SSM】WEB專案中的中文亂碼問題SSMWeb
- 關於本地GB2312編碼的檔案上傳github後 中文出現亂碼的問題Github
- Python基礎教程:Flask上傳檔案(包含中文)儲存後亂碼問題解決PythonFlask
- COD的移動化道路曾艱難曲折?探其成功背後的買量策略
- 關於Spring Cloud Zuul網管上傳檔案亂碼問題SpringCloudZuul
- ubuntu 7.10 的 evince 看部分PDF檔案亂碼問題解決Ubuntu
- RTC 科普視訊丨聊聊空間音訊的原理與其背後的聲學原理音訊
- 大體積XML檔案處理效能問題XML
- flex亂碼問題Flex
- mysql亂碼問題MySql
- 請教高手關於解析xml檔案的問題 急~~XML
- javaweb 中的亂碼問題JavaWeb
- 從SpringMvc原始碼分析其工作原理SpringMVC原始碼