Kafka設計解析(二)- Kafka High Availability
Kafka從0.8版本開始提供High Availability機制,從而提高了系統可用性及資料永續性。本文從Data Replication和Leader Election兩方面介紹了Kafka的HA機制。
本文轉發自技術世界,原文連結 http://www.jasongj.com/2015/04/24/KafkaColumn2
摘要
Kafka在0.8以前的版本中,並不提供High Availablity機制,一旦一個或多個Broker當機,則當機期間其上所有Partition都無法繼續提供服務。若該Broker永遠不能再恢復,亦或磁碟故障,則其上資料將丟失。而Kafka的設計目標之一即是提供資料持久化,同時對於分散式系統來說,尤其當叢集規模上升到一定程度後,一臺或者多臺機器當機的可能性大大提高,對於Failover機制的需求非常高。因此,Kafka從0.8開始提供High Availability機制。本文從Data Replication和Leader Election兩方面介紹了Kafka的HA機制。
Kafka為何需要High Available
為何需要Replication
在Kafka在0.8以前的版本中,是沒有Replication的,一旦某一個Broker當機,則其上所有的Partition資料都不可被消費,這與Kafka資料永續性及Delivery Guarantee的設計目標相悖。同時Producer都不能再將資料存於這些Partition中。
- 如果Producer使用同步模式則Producer會在嘗試重新傳送
message.send.max.retries(預設值為3)次後丟擲Exception,使用者可以選擇停止傳送後續資料也可選擇繼續選擇傳送。而前者會造成資料的阻塞,後者會造成本應發往該Broker的資料的丟失。 - 如果Producer使用非同步模式,則Producer會嘗試重新傳送
message.send.max.retries(預設值為3)次後記錄該異常並繼續傳送後續資料,這會造成資料丟失並且使用者只能通過日誌發現該問題。
由此可見,在沒有Replication的情況下,一旦某機器當機或者某個Broker停止工作則會造成整個系統的可用性降低。隨著叢集規模的增加,整個叢集中出現該類異常的機率大大增加,因此對於生產系統而言Replication機制的引入非常重要。
為何需要Leader Election
(本文所述Leader Election主要指Replica之間的Leader Election)
引入Replication之後,同一個Partition可能會有多個Replica,而這時需要在這些Replica中選出一個Leader,Producer和Consumer只與這個Leader互動,其它Replica作為Follower從Leader中複製資料。
因為需要保證同一個Partition的多個Replica之間的資料一致性(其中一個當機後其它Replica必須要能繼續服務並且即不能造成資料重複也不能造成資料丟失)。如果沒有一個Leader,所有Replica都可同時讀/寫資料,那就需要保證多個Replica之間互相(N×N條通路)同步資料,資料的一致性和有序性非常難保證,大大增加了Replication實現的複雜性,同時也增加了出現異常的機率。而引入Leader後,只有Leader負責資料讀寫,Follower只向Leader順序Fetch資料(N條通路),系統更加簡單且高效。
Kafka HA設計解析
如何將所有Replica均勻分佈到整個叢集
為了更好的做負載均衡,Kafka儘量將所有的Partition均勻分配到整個叢集上。一個典型的部署方式是一個Topic的Partition數量大於Broker的數量。同時為了提高Kafka的容錯能力,也需要將同一個Partition的Replica儘量分散到不同的機器。實際上,如果所有的Replica都在同一個Broker上,那一旦該Broker當機,該Partition的所有Replica都無法工作,也就達不到HA的效果。同時,如果某個Broker當機了,需要保證它上面的負載可以被均勻的分配到其它倖存的所有Broker上。
Kafka分配Replica的演算法如下:
- 將所有Broker(假設共n個Broker)和待分配的Partition排序
- 將第i個Partition分配到第(i mod n)個Broker上
- 將第i個Partition的第j個Replica分配到第((i + j) mod n)個Broker上
Data Replication
Kafka的Data Replication需要解決如下問題:
- 怎樣Propagate訊息
- 在向Producer傳送ACK前需要保證有多少個Replica已經收到該訊息
- 怎樣處理某個Replica不工作的情況
- 怎樣處理Failed Replica恢復回來的情況
Propagate訊息
Producer在釋出訊息到某個Partition時,先通過Zookeeper找到該Partition的Leader,然後無論該Topic的Replication Factor為多少(也即該Partition有多少個Replica),Producer只將該訊息傳送到該Partition的Leader。Leader會將該訊息寫入其本地Log。每個Follower都從Leader pull資料。這種方式上,Follower儲存的資料順序與Leader保持一致。Follower在收到該訊息並寫入其Log後,向Leader傳送ACK。一旦Leader收到了ISR中的所有Replica的ACK,該訊息就被認為已經commit了,Leader將增加HW(high watermark,最後 commit 的 offset)並且向Producer傳送ACK。
為了提高效能,每個Follower在接收到資料後就立馬向Leader傳送ACK,而非等到資料寫入Log中。因此,對於已經commit的訊息,Kafka只能保證它被存於多個Replica的記憶體中,而不能保證它們被持久化到磁碟中,也就不能完全保證異常發生後該條訊息一定能被Consumer消費。但考慮到這種場景非常少見,可以認為這種方式在效能和資料持久化上做了一個比較好的平衡。在將來的版本中,Kafka會考慮提供更高的永續性。
Consumer讀訊息也是從Leader讀取,只有被commit過的訊息(offset低於HW的訊息)才會暴露給Consumer。
Kafka Replication的資料流如下圖所示
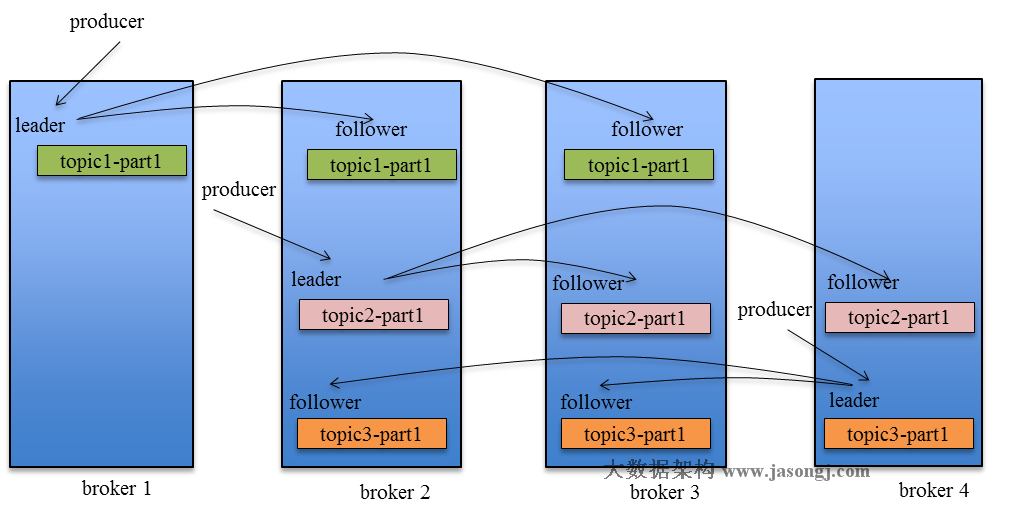
ACK前需要保證有多少個備份
和大部分分散式系統一樣,Kafka處理失敗需要明確定義一個Broker是否“活著”。對於Kafka而言,Kafka存活包含兩個條件,一是它必須維護與Zookeeper的session(這個通過Zookeeper的Heartbeat機制來實現)。二是Follower必須能夠及時將Leader的訊息複製過來,不能“落後太多”。
Leader會跟蹤與其保持同步的Replica列表,該列表稱為ISR(即in-sync Replica)。如果一個Follower當機,或者落後太多,Leader將把它從ISR中移除。這裡所描述的“落後太多”指Follower複製的訊息落後於Leader後的條數超過預定值(該值可在$KAFKA_HOME/config/server.properties中通過replica.lag.max.messages配置,其預設值是4000)或者Follower超過一定時間(該值可在$KAFKA_HOME/config/server.properties中通過replica.lag.time.max.ms來配置,其預設值是10000)未向Leader傳送fetch請求。
Kafka的複製機制既不是完全的同步複製,也不是單純的非同步複製。事實上,同步複製要求所有能工作的Follower都複製完,這條訊息才會被認為commit,這種複製方式極大的影響了吞吐率(高吞吐率是Kafka非常重要的一個特性)。而非同步複製方式下,Follower非同步的從Leader複製資料,資料只要被Leader寫入log就被認為已經commit,這種情況下如果Follower都複製完都落後於Leader,而如果Leader突然當機,則會丟失資料。而Kafka的這種使用ISR的方式則很好的均衡了確保資料不丟失以及吞吐率。Follower可以批量的從Leader複製資料,這樣極大的提高複製效能(批量寫磁碟),極大減少了Follower與Leader的差距。
需要說明的是,Kafka只解決fail/recover,不處理“Byzantine”(“拜占庭”)問題。一條訊息只有被ISR裡的所有Follower都從Leader複製過去才會被認為已提交。這樣就避免了部分資料被寫進了Leader,還沒來得及被任何Follower複製就當機了,而造成資料丟失(Consumer無法消費這些資料)。而對於Producer而言,它可以選擇是否等待訊息commit,這可以通過request.required.acks來設定。這種機制確保了只要ISR有一個或以上的Follower,一條被commit的訊息就不會丟失。
Leader Election演算法
上文說明了Kafka是如何做Replication的,另外一個很重要的問題是當Leader當機了,怎樣在Follower中選舉出新的Leader。因為Follower可能落後許多或者crash了,所以必須確保選擇“最新”的Follower作為新的Leader。一個基本的原則就是,如果Leader不在了,新的Leader必須擁有原來的Leader commit過的所有訊息。這就需要作一個折衷,如果Leader在標明一條訊息被commit前等待更多的Follower確認,那在它當機之後就有更多的Follower可以作為新的Leader,但這也會造成吞吐率的下降。
一種非常常用的Leader Election的方式是“Majority Vote”(“少數服從多數”),但Kafka並未採用這種方式。這種模式下,如果我們有2f+1個Replica(包含Leader和Follower),那在commit之前必須保證有f+1個Replica複製完訊息,為了保證正確選出新的Leader,fail的Replica不能超過f個。因為在剩下的任意f+1個Replica裡,至少有一個Replica包含有最新的所有訊息。這種方式有個很大的優勢,系統的latency只取決於最快的幾個Broker,而非最慢那個。Majority Vote也有一些劣勢,為了保證Leader Election的正常進行,它所能容忍的fail的follower個數比較少。如果要容忍1個follower掛掉,必須要有3個以上的Replica,如果要容忍2個Follower掛掉,必須要有5個以上的Replica。也就是說,在生產環境下為了保證較高的容錯程度,必須要有大量的Replica,而大量的Replica又會在大資料量下導致效能的急劇下降。這就是這種演算法更多用在Zookeeper這種共享叢集配置的系統中而很少在需要儲存大量資料的系統中使用的原因。例如HDFS的HA Feature是基於majority-vote-based journal,但是它的資料儲存並沒有使用這種方式。
實際上,Leader Election演算法非常多,比如Zookeeper的Zab, Raft和Viewstamped Replication。而Kafka所使用的Leader Election演算法更像微軟的PacificA演算法。
Kafka在Zookeeper中動態維護了一個ISR(in-sync replicas),這個ISR裡的所有Replica都跟上了leader,只有ISR裡的成員才有被選為Leader的可能。在這種模式下,對於f+1個Replica,一個Partition能在保證不丟失已經commit的訊息的前提下容忍f個Replica的失敗。在大多數使用場景中,這種模式是非常有利的。事實上,為了容忍f個Replica的失敗,Majority Vote和ISR在commit前需要等待的Replica數量是一樣的,但是ISR需要的總的Replica的個數幾乎是Majority Vote的一半。
雖然Majority Vote與ISR相比有不需等待最慢的Broker這一優勢,但是Kafka作者認為Kafka可以通過Producer選擇是否被commit阻塞來改善這一問題,並且節省下來的Replica和磁碟使得ISR模式仍然值得。
如何處理所有Replica都不工作
上文提到,在ISR中至少有一個follower時,Kafka可以確保已經commit的資料不丟失,但如果某個Partition的所有Replica都當機了,就無法保證資料不丟失了。這種情況下有兩種可行的方案:
- 等待ISR中的任一個Replica“活”過來,並且選它作為Leader
- 選擇第一個“活”過來的Replica(不一定是ISR中的)作為Leader
這就需要在可用性和一致性當中作出一個簡單的折衷。如果一定要等待ISR中的Replica“活”過來,那不可用的時間就可能會相對較長。而且如果ISR中的所有Replica都無法“活”過來了,或者資料都丟失了,這個Partition將永遠不可用。選擇第一個“活”過來的Replica作為Leader,而這個Replica不是ISR中的Replica,那即使它並不保證已經包含了所有已commit的訊息,它也會成為Leader而作為consumer的資料來源(前文有說明,所有讀寫都由Leader完成)。Kafka0.8.*使用了第二種方式。根據Kafka的文件,在以後的版本中,Kafka支援使用者通過配置選擇這兩種方式中的一種,從而根據不同的使用場景選擇高可用性還是強一致性。
如何選舉Leader
最簡單最直觀的方案是,所有Follower都在Zookeeper上設定一個Watch,一旦Leader當機,其對應的ephemeral znode會自動刪除,此時所有Follower都嘗試建立該節點,而建立成功者(Zookeeper保證只有一個能建立成功)即是新的Leader,其它Replica即為Follower。
但是該方法會有3個問題:
- split-brain 這是由Zookeeper的特性引起的,雖然Zookeeper能保證所有Watch按順序觸發,但並不能保證同一時刻所有Replica“看”到的狀態是一樣的,這就可能造成不同Replica的響應不一致
- herd effect 如果當機的那個Broker上的Partition比較多,會造成多個Watch被觸發,造成叢集內大量的調整
- Zookeeper負載過重 每個Replica都要為此在Zookeeper上註冊一個Watch,當叢集規模增加到幾千個Partition時Zookeeper負載會過重。
Kafka 0.8.*的Leader Election方案解決了上述問題,它在所有broker中選出一個controller,所有Partition的Leader選舉都由controller決定。controller會將Leader的改變直接通過RPC的方式(比Zookeeper Queue的方式更高效)通知需為此作出響應的Broker。同時controller也負責增刪Topic以及Replica的重新分配。
broker failover過程簡介
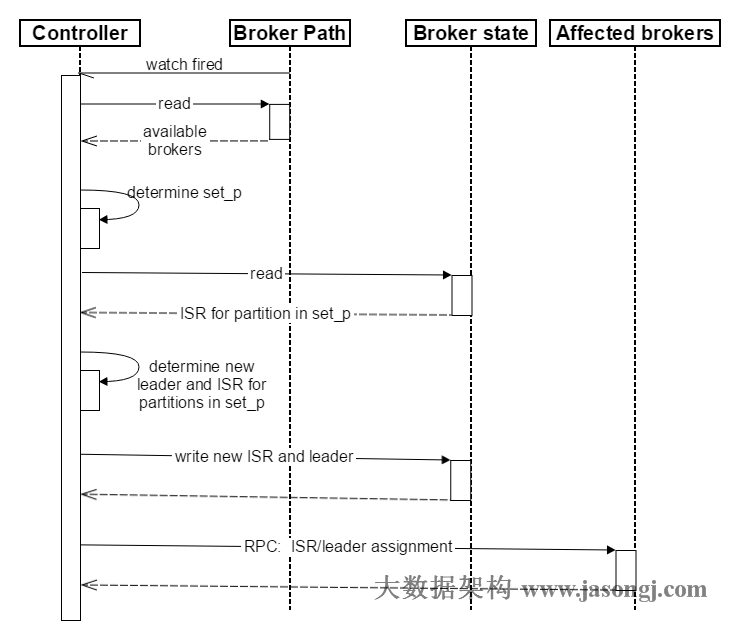
- Controller在Zookeeper註冊Watch,一旦有Broker當機(這是用當機代表任何讓系統認為其die的情景,包括但不限於機器斷電,網路不可用,GC導致的Stop The World,程式crash等),其在Zookeeper對應的znode會自動被刪除,Zookeeper會fire Controller註冊的watch,Controller讀取最新的倖存的Broker
- Controller決定set_p,該集合包含了當機的所有Broker上的所有Partition
- 對set_p中的每一個Partition
3.1 從/brokers/topics/[topic]/partitions/[partition]/state讀取該Partition當前的ISR
3.2 決定該Partition的新Leader。如果當前ISR中有至少一個Replica還倖存,則選擇其中一個作為新Leader,新的ISR則包含當前ISR中所有幸存的Replica。否則選擇該Partition中任意一個倖存的Replica作為新的Leader以及ISR(該場景下可能會有潛在的資料丟失)。如果該Partition的所有Replica都當機了,則將新的Leader設定為-1。
3.3 將新的Leader,ISR和新的leader_epoch及controller_epoch寫入/brokers/topics/[topic]/partitions/[partition]/state。注意,該操作只有其version在3.1至3.3的過程中無變化時才會執行,否則跳轉到3.1 - 直接通過RPC向set_p相關的Broker傳送LeaderAndISRRequest命令。Controller可以在一個RPC操作中傳送多個命令從而提高效率。
Broker failover順序圖如下所示。
個人微信公眾號:

作者:jiankunking 出處:http://blog.csdn.net/jiankunking
相關文章
- Kafka設計解析(二)- Kafka High Availability (上)KafkaAI
- kafka檔案系統設計解析Kafka
- 流式處理界的新貴 Kafka Stream - Kafka設計解析(七)Kafka
- kafka詳解四:Kafka的設計思想、理念Kafka
- Kafka 的設計思想Kafka
- Apache Kafka設計思考ApacheKafka
- Kafka 學習筆記(二) :初探 KafkaKafka筆記
- kafka學習(二)-------- 什麼是KafkaKafka
- Kafka學習筆記(二) :初探KafkaKafka筆記
- kafka原理解析Kafka
- Kafka程式碼解析Kafka
- Kafka深度解析(1)Kafka
- 詳細解析kafka之kafka分割槽和副本Kafka
- Kafka詳解二、如何配置Kafka叢集Kafka
- 《Kafka官方文件》設計(一)Kafka
- Kafka學習之(二)Centos下安裝KafkaKafkaCentOS
- Kafka 生產者解析Kafka
- Kafka 消費者解析Kafka
- Apache Kafka 程式設計實戰ApacheKafka程式設計
- KafKa Java程式設計例項KafkaJava程式設計
- 深入理解Kafka核心設計及原理(二):生產者Kafka
- kafka原始碼剖析(二)之kafka-server的啟動Kafka原始碼Server
- kafka 三高架構設計剖析Kafka架構
- Kafka設計解析(八)- Exactly Once語義與事務機制原理Kafka
- Performance and High-Availability OptionsORMAI
- High Availability (HA) in SQL ServerAISQLServer
- 記一次kafka的high level和low levelKafka
- kafka-ngx_kafka_moduleKafka
- 【Kafka】Kafka叢集搭建Kafka
- Kafka實戰-Kafka ClusterKafka
- Kafka Broker原始碼:網路層設計Kafka原始碼
- flume+kafka+storm+mysql架構設計KafkaORMMySql架構
- kafka之一:kafka簡介Kafka
- kafka工具kafka-topic.shKafka
- Kafka實戰-Flume到KafkaKafka
- Kafka實戰-Kafka到StormKafkaORM
- Flink kafka source & sink 原始碼解析Kafka原始碼
- kafka-log日誌程式碼解析Kafka