一次Java執行緒池誤用引發的血案和總結
這是一個十分嚴重的問題
自從最近的某年某月某天起,線上服務開始變得不那麼穩定。在高峰期,時常有幾臺機器的記憶體持續飆升,並且無法回收,導致服務不可用。
例如GC時間取樣曲線:
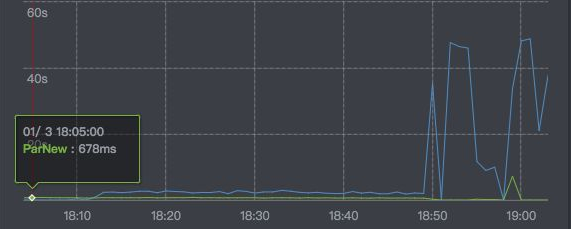
和記憶體使用曲線:
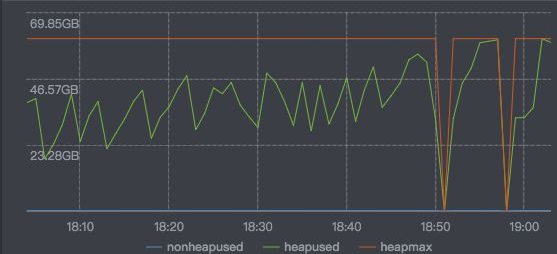
圖中所示,18:50-19:00的階段,已經處於服務不可用的狀態了。上游服務的超時異常會增加,該臺機器會觸發熔斷。熔斷觸發後,改臺機器的流量會打到其他機器,其他機器發生類似的情況的可能性會提高,極端情況會引起所有服務當機,曲線掉底。
因為線上記憶體過大,如果採用 jmap dump的方式,這個任務可能需要很久才可以執行完,同時把這麼大的檔案存放起來匯入工具也是一件很難的事情。再看JVM啟動引數,也很久沒有變更過 Xms, Xmx, -XX:NewRatio, -XX:SurvivorRatio, 雖然沒有仔細分析程式使用記憶體情況,但看起來也無大礙。
於是開始找程式碼,某年某天某月~ 嗯,注意到一段這樣的程式碼提交:
private static ExecutorService executor = Executors.newFixedThreadPool(15);
public static void push2Kafka(Object msg) {
executor.execute(new WriteTask(msg, false));
}
相關程式碼的完整功能是,每次線上呼叫,都會把計算結果的日誌打到 Kafka,Kafka消費方再繼續後續的邏輯。記憶體被耗盡可能有一個原因是,因為使用了 newFixedThreadPool 執行緒池,而它的工作機制是,固定了N個執行緒,而提交給執行緒池的任務佇列是不限制大小的,如果Kafka發訊息被阻塞或者變慢,那麼顯然佇列裡面的內容會越來越多,也就會導致這樣的問題。
為了驗證這個想法,做了個小實驗,把 newFixedThreadPool 執行緒池的執行緒個數調小一點,例如 1。果然壓測了一下,很快就復現了記憶體耗盡,服務不可用的悲劇。
最後的修復策略是使用了自定義的執行緒池引數,而非 Executors 預設實現解決了問題。下面就把執行緒池相關的原理和引數總結一下,避免未來踩坑。
1. Java執行緒池
雖然Java執行緒池理論,以及構造執行緒池的各種引數,以及 Executors 提供的預設實現之前研讀過,不過線上還沒有發生過執行緒池誤用引發的事故,所以有必要把這些引數再仔細琢磨一遍。
優先補充一些執行緒池的工作理論,有助於展開下面的內容。執行緒池顧名思義,就是由很多執行緒構成的池子,來一個任務,就從池子中取一個執行緒,處理這個任務。這個理解是我在第一次接觸到這個概念時候的理解,雖然整體基本切入到核心,但是實際上會比這個複雜。例如執行緒池肯定不會無限擴大的,否則資源會耗盡;當執行緒數到達一個階段,提交的任務會被暫時儲存在一個佇列中,如果佇列內容可以不斷擴大,極端下也會耗盡資源,那選擇什麼型別的佇列,當佇列滿如何處理任務,都有涉及很多內容。執行緒池總體的工作過程如下圖:
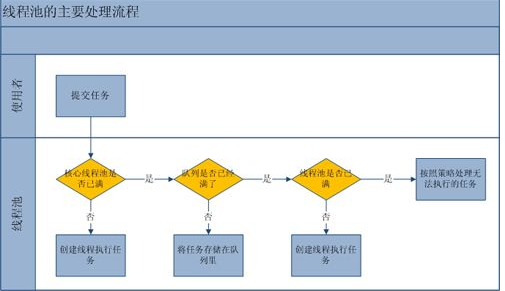
執行緒池內的執行緒數的大小相關的概念有兩個,一個是核心池大小,還有最大池大小。如果當前的執行緒個數比核心池個數小,當任務到來,會優先建立一個新的執行緒並執行任務。當已經到達核心池大小,則把任務放入佇列,為了資源不被耗盡,佇列的最大容量可能也是有上限的,如果達到佇列上限則考慮繼續建立新執行緒執行任務,如果此刻執行緒的個數已經到達最大池上限,則考慮把任務丟棄。
在 java.util.concurrent 包中,提供了 ThreadPoolExecutor 的實現。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
既然有了剛剛對執行緒池工作原理對概述,這些引數就很容易理解了:
corePoolSize- 核心池大小,既然如前原理部分所述。需要注意的是在初建立執行緒池時執行緒不會立即啟動,直到有任務提交才開始啟動執行緒並逐漸時執行緒數目達到corePoolSize。若想一開始就建立所有核心執行緒需呼叫prestartAllCoreThreads方法。
maximumPoolSize-池中允許的最大執行緒數。需要注意的是當核心執行緒滿且阻塞佇列也滿時才會判斷當前執行緒數是否小於最大執行緒數,並決定是否建立新執行緒。
keepAliveTime - 當執行緒數大於核心時,多於的空閒執行緒最多存活時間
unit - keepAliveTime 引數的時間單位。
workQueue - 當執行緒數目超過核心執行緒數時用於儲存任務的佇列。主要有3種型別的BlockingQueue可供選擇:無界佇列,有界佇列和同步移交。將在下文中詳細闡述。從引數中可以看到,此佇列僅儲存實現Runnable介面的任務。 別看這個引數位置很靠後,但是真的很重要,因為樓主的坑就因這個引數而起,這些細節有必要仔細瞭解清楚。
threadFactory - 執行程式建立新執行緒時使用的工廠。
handler - 阻塞佇列已滿且執行緒數達到最大值時所採取的飽和策略。java預設提供了4種飽和策略的實現方式:中止、拋棄、拋棄最舊的、呼叫者執行。將在下文中詳細闡述。
2. 可選擇的阻塞佇列BlockingQueue詳解
在重複一下新任務進入時執行緒池的執行策略:
如果執行的執行緒少於corePoolSize,則 Executor始終首選新增新的執行緒,而不進行排隊。(如果當前執行的執行緒小於corePoolSize,則任務根本不會存入queue中,而是直接執行)
如果執行的執行緒大於等於 corePoolSize,則 Executor始終首選將請求加入佇列,而不新增新的執行緒。
如果無法將請求加入佇列,則建立新的執行緒,除非建立此執行緒超出 maximumPoolSize,在這種情況下,任務將被拒絕。
主要有3種型別的BlockingQueue:
無界佇列
佇列大小無限制,常用的為無界的LinkedBlockingQueue,使用該佇列做為阻塞佇列時要尤其當心,當任務耗時較長時可能會導致大量新任務在佇列中堆積最終導致OOM。閱讀程式碼發現,Executors.newFixedThreadPool 採用就是 LinkedBlockingQueue,而樓主踩到的就是這個坑,當QPS很高,傳送資料很大,大量的任務被新增到這個無界LinkedBlockingQueue 中,導致cpu和記憶體飆升伺服器掛掉。
有界佇列
常用的有兩類,一類是遵循FIFO原則的佇列如ArrayBlockingQueue與有界的LinkedBlockingQueue,另一類是優先順序佇列如PriorityBlockingQueue。PriorityBlockingQueue中的優先順序由任務的Comparator決定。
使用有界佇列時佇列大小需和執行緒池大小互相配合,執行緒池較小有界佇列較大時可減少記憶體消耗,降低cpu使用率和上下文切換,但是可能會限制系統吞吐量。
在我們的修復方案中,選擇的就是這個型別的佇列,雖然會有部分任務被丟失,但是我們線上是排序日誌蒐集任務,所以對部分對丟失是可以容忍的。
同步移交佇列
如果不希望任務在佇列中等待而是希望將任務直接移交給工作執行緒,可使用SynchronousQueue作為等待佇列。SynchronousQueue不是一個真正的佇列,而是一種執行緒之間移交的機制。要將一個元素放入SynchronousQueue中,必須有另一個執行緒正在等待接收這個元素。只有在使用無界執行緒池或者有飽和策略時才建議使用該佇列。
3. 可選擇的飽和策略RejectedExecutionHandler詳解
JDK主要提供了4種飽和策略供選擇。4種策略都做為靜態內部類在ThreadPoolExcutor中進行實現。
3.1 AbortPolicy中止策略
該策略是預設飽和策略。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
使用該策略時在飽和時會丟擲RejectedExecutionException(繼承自RuntimeException),呼叫者可捕獲該異常自行處理。
3.2 DiscardPolicy拋棄策略
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
如程式碼所示,不做任何處理直接拋棄任務
3.3 DiscardOldestPolicy拋棄舊任務策略
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
如程式碼,先將阻塞佇列中的頭元素出隊拋棄,再嘗試提交任務。如果此時阻塞佇列使用PriorityBlockingQueue優先順序佇列,將會導致優先順序最高的任務被拋棄,因此不建議將該種策略配合優先順序佇列使用。
3.4 CallerRunsPolicy呼叫者執行
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
既不拋棄任務也不丟擲異常,直接執行任務的run方法,換言之將任務回退給呼叫者來直接執行。使用該策略時執行緒池飽和後將由呼叫執行緒池的主執行緒自己來執行任務,因此在執行任務的這段時間裡主執行緒無法再提交新任務,從而使執行緒池中工作執行緒有時間將正在處理的任務處理完成。
4. Java提供的四種常用執行緒池解析
既然樓主踩坑就是使用了 JDK 的預設實現,那麼再來看看這些預設實現到底幹了什麼,封裝了哪些引數。簡而言之 Executors 工廠方法Executors.newCachedThreadPool() 提供了無界執行緒池,可以進行自動執行緒回收;Executors.newFixedThreadPool(int) 提供了固定大小執行緒池,內部使用無界佇列;Executors.newSingleThreadExecutor() 提供了單個後臺執行緒。
詳細介紹一下上述四種執行緒池。
4.1 newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
在newCachedThreadPool中如果執行緒池長度超過處理需要,可靈活回收空閒執行緒,若無可回收,則新建執行緒。
初看該建構函式時我有這樣的疑惑:核心執行緒池為0,那按照前面所講的執行緒池策略新任務來臨時無法進入核心執行緒池,只能進入 SynchronousQueue中進行等待,而SynchronousQueue的大小為1,那豈不是第一個任務到達時只能等待在佇列中,直到第二個任務到達發現無法進入佇列才能建立第一個執行緒?
這個問題的答案在上面講SynchronousQueue時其實已經給出了,要將一個元素放入SynchronousQueue中,必須有另一個執行緒正在等待接收這個元素。因此即便SynchronousQueue一開始為空且大小為1,第一個任務也無法放入其中,因為沒有執行緒在等待從SynchronousQueue中取走元素。因此第一個任務到達時便會建立一個新執行緒執行該任務。
4.2 newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
看程式碼一目瞭然了,執行緒數量固定,使用無限大的佇列。再次強調,樓主就是踩的這個無限大佇列的坑。
4.3 newScheduledThreadPool
建立一個定長執行緒池,支援定時及週期性任務執行。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
在來看看ScheduledThreadPoolExecutor()的建構函式
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
ScheduledThreadPoolExecutor的父類即ThreadPoolExecutor,因此這裡各引數含義和上面一樣。值得關心的是DelayedWorkQueue這個阻塞對列,在上面沒有介紹,它作為靜態內部類就在ScheduledThreadPoolExecutor中進行了實現。簡單的說,DelayedWorkQueue是一個無界佇列,它能按一定的順序對工作佇列中的元素進行排列。
4.4 newSingleThreadExecutor
建立一個單執行緒化的執行緒池,它只會用唯一的工作執行緒來執行任務,保證所有任務按照指定順序(FIFO, LIFO, 優先順序)執行。
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
首先new了一個執行緒數目為 1 的ScheduledThreadPoolExecutor,再把該物件傳入DelegatedScheduledExecutorService中,看看DelegatedScheduledExecutorService的實現程式碼:
DelegatedScheduledExecutorService(ScheduledExecutorService executor) {
super(executor);
e = executor;
}
在看看它的父類
DelegatedExecutorService(ExecutorService executor) {
e = executor;
}
其實就是使用裝飾模式增強了ScheduledExecutorService(1)的功能,不僅確保只有一個執行緒順序執行任務,也保證執行緒意外終止後會重新建立一個執行緒繼續執行任務。
結束語
雖然之前學習了不少相關知識,但是隻有在實踐中踩坑才能印象深刻吧
原文地址:https://zhuanlan.zhihu.com/p/32867181?utm_source=wechat_session&utm_medium=social
個人微信公眾號:

作者:jiankunking 出處:http://blog.csdn.net/jiankunking相關文章
- 多執行緒:執行緒池理解和使用總結執行緒
- Java執行緒池總結和常用開源庫的使用Java執行緒
- Java-ThreadPool執行緒池總結Javathread執行緒
- Java 併發:執行緒、執行緒池和執行器全面教程Java執行緒
- MYSQL執行緒池總結(一)MySql執行緒
- MySQL執行緒池總結(二)MySql執行緒
- Java執行緒池二:執行緒池原理Java執行緒
- SpringBoot執行緒池和Java執行緒池的實現原理Spring Boot執行緒Java
- Java面試必問之執行緒池的建立使用、執行緒池的核心引數、執行緒池的底層工作原理Java面試執行緒
- Java執行緒總結Java執行緒
- Java執行緒池的使用和原理Java執行緒
- 執行緒和執行緒池執行緒
- Java多執行緒——執行緒池Java執行緒
- 《Java 高階篇》七:執行緒和執行緒池Java執行緒
- Java併發系列 — 執行緒池Java執行緒
- Java併發 之 執行緒池系列 (1) 讓多執行緒不再坑爹的執行緒池Java執行緒
- Java多執行緒-執行緒池的使用Java執行緒
- Java執行緒池Java執行緒
- java 執行緒池Java執行緒
- 執行緒和執行緒池的理解與java簡單例子執行緒Java單例
- 深入理解Java多執行緒與併發框(第⑪篇)——執行緒池引數Java執行緒
- Java中命名執行器服務執行緒和執行緒池Java執行緒
- java執行緒池趣味事:這不是執行緒池Java執行緒
- java多執行緒總結Java執行緒
- java多執行緒與併發 - 執行緒池詳解Java執行緒
- java多執行緒9:執行緒池Java執行緒
- Java多執行緒18:執行緒池Java執行緒
- Android的執行緒和執行緒池Android執行緒
- java 執行緒池的初始化引數解釋和引數設定Java執行緒
- JAVA執行緒池的使用Java執行緒
- java--執行緒池--建立執行緒池的幾種方式與執行緒池操作詳解Java執行緒
- 多執行緒(三)、執行緒池 ThreadPoolExecutor 知識點總結執行緒thread
- Java併發——執行緒池ThreadPoolExecutorJava執行緒thread
- 高併發面試:執行緒池的七大引數?手寫一個執行緒池?面試執行緒
- 搞懂Java執行緒池Java執行緒
- Java Executors(執行緒池)Java執行緒
- Java執行緒池(Executor)Java執行緒
- 執行緒併發總結執行緒