深入理解JVM讀書筆記五: Java記憶體模型與Volatile關鍵字
12.2硬體的效率與一致性
由於計算機的儲存裝置與處理器的運算速度有幾個數量級的差距,所以現代計算機系統都不得不加入一層讀寫速度儘可能接近處理器運算速度的快取記憶體(Cache)來作為記憶體與處理器之間的緩衝:將運算需要使用到的資料複製到快取中,讓運算能快速進行,當運算結束後再從快取同步回記憶體之中,這樣處理器就無須等待緩慢的記憶體讀寫了。
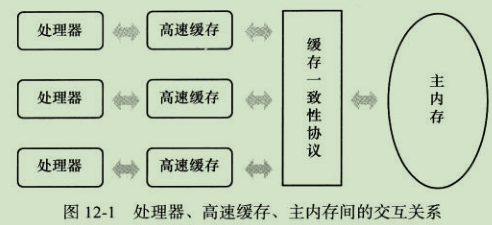
基於快取記憶體的儲存互動很好地理解了處理器與記憶體的速度矛盾,但是也為計算機系統帶來了更高的複雜度,因為它引入了一個新的問題: 快取一致性(Cache Coherence)。在多處理器系統中,每個處理器都有自己的高數快取,而它們又共享同一主記憶體(Main Memory),如圖 12-1 所示。當多個處理器的運算任務都涉及同一塊主記憶體區域時,將可能導致各自的快取資料不一致,如果真的發生這種情況,那同步回到主記憶體時以誰的快取資料為準呢?為了解決一致性的問題,需要各個處理器訪問快取時都遵循一些協議,在讀寫時要根據協議來進行操作,這類協議有 MSI、MESI(Illinois Protocol)、MOSI、Synapse、Firefly 及 Dragon Protocol 等。在本章中將會多次提到的 “記憶體模型” 一詞,可以理解為在特定的操作協議下,對特定的記憶體或快取記憶體進行讀寫訪問的過程抽象。不同架構的物理機器可以擁有不一樣的記憶體模型,而 Java 虛擬機器也有自己的記憶體模型,並且這裡介紹的記憶體訪問操作與硬體的快取訪問操作具有很高的可比性。
除了增加快取記憶體之外,為了使得處理器內部的運算單元能儘量被充分利用,處理器可能會對輸入程式碼進行亂序執行(Out-Of-Order Execution)優化,處理器會在計算之後將亂序執行的結果重組,保證該結果與順序執行的結果是一致的,但並不保證程式中各個語句計算的先後順序與輸入程式碼中的順序一致,因此,如果存在一個計算任務依賴另外一個計算任務的中間結果,那麼其順序並不能靠程式碼的先後順序來保證。與處理器的亂序執行優化型別,Java 虛擬機器的即時編譯器中有有類似的指令重排序(Instruction Reorder)優化。
12.3 Java 記憶體模型
Java 虛擬機器規範中試圖定義一種 Java 記憶體模型(Java Memory Model,JMM)來遮蔽掉各種硬體和作業系統的記憶體訪問差異,以實現讓 Java 程式在各種平臺下都能達到一致的記憶體訪問效果。
12.3.1 主記憶體與工作記憶體
Java 記憶體模型的主要目標是定義程式中各個變數的訪問規則,即在虛擬機器中將變數儲存到記憶體和從記憶體中取出變數這樣的底層細節。此處的變數(Variables)與 Java 程式設計中所說的變數有所區別,它包括了例項欄位、靜態欄位和構成陣列物件的元素,但不包括區域性變數與方法引數,因為後者是執行緒私有的,不會被共享,自然就不會存在競爭問題。為了獲得較好的執行效能,Java 記憶體模型並沒有限制執行引擎使用處理器的特定暫存器或快取和主記憶體進行互動,也沒有限制即時編譯器進行調整程式碼執行順序這類優化措施。
Java 記憶體模型規定了所有的變數都儲存在主記憶體(Main Memory)中(此處的主記憶體與介紹物理硬體時的主記憶體名字一樣,兩者也可以互相類比,但此處僅是虛擬機器記憶體的一部分)。每個執行緒還有自己的工作記憶體(Working Memory,可與前面講的處理器快取記憶體類比),執行緒的工作記憶體中儲存了被該執行緒使用到的變數的主記憶體副本拷貝,執行緒對變數的所有操作(讀取、賦值等)都必須在工作記憶體中進行,而不能直接讀寫主記憶體中的變數。不同的執行緒之間也無法直接訪問對方工作記憶體中的變數,執行緒間變數值的傳遞均需要通過主記憶體來完成,執行緒、主記憶體、工作記憶體三者的互動關係如圖 12-2 所示。
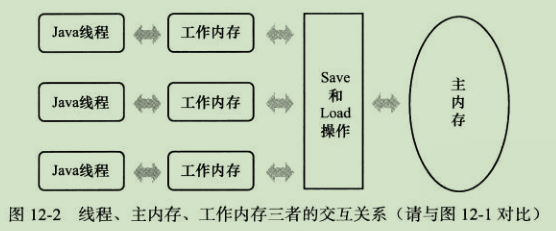
這裡所講的主記憶體、工作記憶體與前面所講的 Java 記憶體區域的 Java 堆、棧、方法區等並不是同一個層次的記憶體劃分,這兩者基本上是沒有關係的,如果兩者一定要勉強對應起來,那從變數、主記憶體、工作記憶體的定義來看,主記憶體主要對應於 Java 堆中的物件例項資料部分,而工作記憶體則對應於虛擬機器棧中的部分割槽域。從更低層次上說,主記憶體就直接對應於物理硬體的記憶體,而為了獲取更高的執行速度,虛擬機器(甚至是硬體系統本身的優化措施)可能會讓工作記憶體優先儲存於暫存器和快取記憶體中,因為程式執行時主要訪問讀寫的是工作記憶體。
副本拷貝:
假設執行緒中訪問一個10MB的物件,也會把這10MB的記憶體複製拷貝一份出來嗎?
事實上並不會如此,這個物件的引用、物件中在某個線上程中訪問到的欄位是可能存在拷貝的,但不會有虛擬機器實現成把整個物件拷貝一次的。
12.3.2記憶體間互動操作
關於主記憶體與工作記憶體之間具體的互動協議,即一個變數如何從主記憶體拷貝到工作記憶體、如何從工作記憶體同步會主記憶體之類的實現細節,Java 記憶體模型中定義了以下 8 種操作來完成,虛擬機器實現時必須保證下面提及的每一種操作都是原子的、不可再分的(對於 double 和 long 型別的變數來說,load、store、read 和 write 操作在某些平臺上允許有例外)。
- lock(鎖定):作用於主記憶體的變數,它把一個變數標識為一條執行緒獨佔的狀態。
- unlock(解鎖):作用於主記憶體的變數,它把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他執行緒鎖定。
- read(讀取):作用於主記憶體的變數,它把一個變數的值從主記憶體傳輸到執行緒的工作記憶體中,以便隨後的 load 動作使用。
- load(載入):作用於工作記憶體的變數,它把 read 操作從主記憶體中得到的變數值放入工作記憶體的變數副本中。
- use(使用):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳遞給執行引擎,每當虛擬機器遇到一個需要使用到變數的值的位元組碼指令時將會執行這個操作。
- assign(賦值):作用於工作記憶體的變數,它把一個從執行引擎接收到的值賦給工作記憶體的變數,每當虛擬機器遇到一個給變數賦值的位元組碼指令時執行這個操作。
- store(儲存):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳送到主記憶體中,以便隨後的 write 操作使用。
- write(寫入):作用於主記憶體的變數,它把 store 操作從工作記憶體中得到的變數的值放入主記憶體的變數中。
如果要把一個變數從主記憶體複製到工作記憶體,那就要順序地執行 read 和 load 操作,如果要把變數從工作記憶體同步回主記憶體,就要順序地執行 store 和 write 操作。注意,Java 記憶體模型只要求上述兩個操作必須按順序執行,而沒有保證是連續執行。也就是說,read 與 load 之間、store 與 write 之間是可插入其他指令的,如對主記憶體中的變數 a、b 進行訪問時,一種可能出現順序是 read a、read b、load b、load a。除此之外,Java 記憶體模型還規定了在執行上述 8 種基本操作時必須滿足如下規則:
- 不允許 read 和 load、store 和 write 操作之一單獨出現,即不允許一個變數從主記憶體讀取了但工作記憶體不接受,或者從工作記憶體發起回寫了但主記憶體不接受的情況出現。
- 不允許一個執行緒丟棄它的最近的 assign 操作,即變數在工作記憶體中改變了之後必須把該變化同步會主記憶體。
- 不允許一個執行緒無原因地(沒有發生過任何 assign 操作)把資料從執行緒的工作記憶體同步回主記憶體中。
- 一個新的變數只能在主記憶體中 “誕生”,不允許在工作記憶體中直接使用一個未被初始化(load 或 assign)的變數,換句話說,就是對一個變數實施 use、store 操作之前,必須先執行過了 assign 和 load 操作。
- 一個變數在同一個時刻只允許一條執行緒對其進行 lock 操作,但 lock 操作可以被同一條執行緒重複執行多次,多次執行 lock 後,只有執行相同次數的 unlock 操作,變數才會被解鎖。
- 如果對一個變數執行 lock 操作,那將會清空工作記憶體中此變數的值,在執行引擎使用這個變數前,需要重新執行 load 或 assign 操縱初始化變數的值。
- 如果一個變數事先沒有被 lock 操作鎖定,那就不允許對它執行 unlock 操作,也不允許去 unlock 一個唄其他執行緒鎖定住的變數。
對一個變數執行 unlock 操作之前,必須先把此變數同步會主記憶體中(執行 store、write 操作)。
這 8 種記憶體訪問操作以及上述規則限定,再加上稍後介紹的對 volatile 的一些特殊規定,就已經完全確定了 Java 程式中哪些記憶體訪問操作在併發下是安全的。由於這種定義相當嚴謹但又十分煩瑣,實踐起來很麻煩,所以在後面筆者將介紹這種定義的一個等效判斷原則——先行發生原則,用來確定一個訪問在併發環境下是否安全。
12.3.3 對於 volatile 型變數的特殊規則
關鍵字 volatile 可以說是 Java 虛擬機器提供的最輕量級的同步機制。
當一個變數定義為 volatile 之後,它將具備兩種特性,第一是保證此變數對所有執行緒的可見性,這裡的 “可見性” 是指當一條執行緒修改了這個變數的值,新值對於其他執行緒來說是可以立即得知的。而普通變數不能做到這一點,普通變數的值線上程間傳遞均需要通過主記憶體來完成,例如,執行緒 A 修改一個普通變數的值,然後向主記憶體進行回寫,另外一條執行緒 B 線上程 A 回寫完成了之後再從主記憶體進行讀取操作,新變數值才會對執行緒 B 可見。
關於 volatile 變數的可見性,經常會被開發人員誤解,認為以下描述成立:“volatile 變數對所有執行緒是立即可見的,對 volatile 變數所有的寫操作都能立刻反應到其他執行緒之中,換句話說,volatile 變數在各個執行緒中是一致的,所以基於 volatile 變數的運算在併發下是安全的”。這句話的論據部分並沒有錯,但是其論據並不能得出 “基於 volatile 變數的運算在併發下是安全的” 這個結論。volatile 變數在各個執行緒的工作記憶體中不存在一致性問題(在各個執行緒的工作記憶體中,volatile 變數也可以存在不一致的情況,但由於每次使用之前都要先重新整理,執行引擎看不到不一致的情況,因此可以認為不存在不一致性問題),但是 Java 裡面的運算並非原子操作,導致 volatile 變數的運算在併發下一樣是不安全的,我們可以通過一段簡單的演示來說明原因,請看程式碼清單 12-1 中演示的例子。
/**
* volatile 變數自增運算測試
*
* @author mk
*/
public class VolatileTest {
public static volatile int race = 0;
public static void increase() {
race++;
}
private static final int THREADS_COUNT = 20;
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_COUNT];
for (int i = 0; i < THREADS_COUNT; i ++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
increase();
}
}
});
threads[i].start();
}
// 等待所有累加執行緒都結束
while (Thread.activeCount() > 1)
Thread.yield();
System.out.println(race);
}
} 這段程式碼發起了 20 個執行緒,每個執行緒對 race 變數進行 10000 次自增操作,如果這段程式碼能夠正確併發的話,最後輸出的結果應該是 200000。讀者執行完這段程式碼之後,並不會獲得期望的結果,而且發現每次執行程式,輸出的結果都不一樣,都是一個小於 200000 的數字,這是為什麼呢?
問題就出現在自增運算 “race++” 之中,我們用 javap 反編譯這段程式碼後會得到程式碼清單 12-2,發現只有一行程式碼的 increase() 方法在 Class 檔案中是由 4 條位元組碼指令構成的(return 指令不是由 race++ 產生的,這條指令可以不計算),從位元組碼層面上很容易就分析出併發失敗的原因了:當 getstatic 指令把 race 的值取到操作棧頂時,volatile 關鍵字保證了 race 的值在此時是正確的,但是在執行 iconst_1、iadd 這些指令的時候,其他執行緒可能已經把 race 的值加大了,而在操作棧頂的值就變成了過期的資料,所以 putstatic 指令執行後就可能把較小的 race 值同步會主記憶體之中。
程式碼清單 12-2 VolatileTest 的位元組碼
public static void increase();
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=0, args_size=0
0: getstatic #13 // Field race:I
3: iconst_1
4: iadd
5: putstatic #13 // Field race:I
8: return
LineNumberTable:
line 13: 0
line 14: 8
客觀地說,筆者在此使用位元組碼來分析併發問題,仍然是不嚴謹的,因為即使編譯出來只有一條位元組碼指令,也並不意味著執行這條指令就是一個原子操作。一條位元組碼指令在解釋執行時,直譯器將要執行許多行程式碼才能實現它的語義,如果是編譯執行,一條位元組碼指令也可能轉化成若干條本地機器碼指令,此處使用 -XX:+PrintAssembly引數輸出反彙編來分析會更嚴峻一些,但考慮讀者閱讀的方便,並且位元組碼已經能說明問題,所以此處使用位元組碼來分析。
由於 volatile 變數只能保證可見性,在不符合以下兩條規則的運算場景中,我們仍然需要通過加鎖(使用 synchronized 或 java.util.concurrent 中的原子類)來保證原子性。
- 運算結果並不依賴變數的當前值,或者能夠確保只有單一的執行緒修改變數的值。
- 變數不需要與其他狀態變數共同參與不變約束。
而在像如下的程式碼清單 12-3 所示的這類場景就很適合使用 volatile 變數來控制併發,當 shutdown() 方法被呼叫時,能保證所有執行緒中執行的 doWork() 方法都立即停下來。
程式碼清單 12-3 volatile 的使用場景
volatile boolean shutdownRequested;
public void shutdown() {
shutdownRequested = true;
}
public void doWork() {
while (!shutdownRequested) {
//do stuff
}
} 使用 volatile 變數的第二個語義是禁止指令重排序優化,普通的變數僅僅會保證在該方法的執行過程中所有依賴賦值結果的地方都能獲取到正確的結果,而不能保證變數賦值操作的順序與程式程式碼中的執行順序一致。因為在一個執行緒的方法執行過程中無法感知到這點,這也就是 Java 記憶體模型中描述的所謂的 “執行緒內表現為序列的語義”(Within-Thread As-If-Serial Semantics)。
上面的描述仍然不太容易理解,我們還是繼續通過一個例子來看看為何指令重排序會干擾程式的併發執行,演示程式如程式碼清單 12-4 所示。
程式碼清單 12-4 指令重排序
Map configOptions;
char[] configText;
// 此變數必須定義為 volatile
volatile boolean initialized = false;
// 假設以下程式碼線上程 A 中執行
// 模擬讀取配置資訊,當讀取完成後將 initialized 設定為 true 以通知其他執行緒配置可用
configOptions = new HashMap();
configText = readConfigFile(fileName);
processConfigOptions(configText, configOptions);
initialized = true;
// 假設以下程式碼線上程 B 中執行
// 等待 initialized 為 true,代表執行緒 A 已經把配置資訊初始化完成
while (!initialized) {
sleep();
}
// 使用執行緒 A 中初始化好的配置資訊
doSomethingWithConfig(); 程式碼清單 12-4 中的程式是一段虛擬碼,其中描述的場景十分場景,只是我們在處理配置檔案時一般不會出現併發而已。如果定義 initialized 變數時沒有使用 volatile 修飾,就可能由於指令重排序的優化,導致位於執行緒 A 中最後一句的程式碼 “initialized=true” 被提前執行(這裡雖然使用 Java 作為虛擬碼,但所指的重排序優化是機器級的優化操作,提前執行是指這句話對應的彙編程式碼被提前執行),這樣線上程 B 中使用配置資訊的程式碼就可能出現錯誤,而 volatile 關鍵字則可以避免此類情況的發生。(注:volatile 遮蔽指令重排序的語義在 JDK 1.5 中才被完全修復,此前的 JDK 中即使將變數宣告為 volatile 也仍然不能完全避免重排序所導致的問題(主要是 volatile 變數前後的程式碼仍然存在重排序問題),這點也是在 JDK 1.5 之前的 Java 中無法按期地使用 DCL(雙鎖檢測)來實現單例模式的原因。)
指令重排序是併發程式設計中最容易讓開發人員產生疑惑的地方,除了上面虛擬碼的例子之外,筆者再舉一個可以實際操作執行的例子來分析 volatile 關鍵字是如何禁止指令重排序優化的。程式碼清單 12-5 是一段標準的 DCL 單例程式碼,可以觀察加入 volatile 和未加入 volatile 關鍵字時所生成彙編程式碼的差別
public class Singleton {
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
public static void main(String[] args) {
Singleton.getInstance();
}
} 編譯後,這段程式碼對 instance 變數賦值部分如程式碼清單 12-6 所示。
0x01a3de0f: mov $0x3375cdb0,%esi ;...beb0cd75 33
; {oop('Singleton')}
0x01a3de14: mov %eax,0x150(%esi) ;...89865001 0000
0x01a3de1a: shr $0x9,%esi ;...c1ee09
0x01a3de1d: movb $0x0,0x1104800(%esi) ;...c6860048 100100
0x01a3de24: lock addl $0x0,(%esp) ;...f0830424 00
;*putstatic instance
; - Singleton::getInstance@24 通過對比就會發現,關鍵變化在於有 volatile 修飾的變數,賦值後(前面 mov %eax,0x150(%esi) 這句便是賦值操作)多執行了一個操作:
lock addl $0x0,(%esp)這個操作相當於一個記憶體屏障(Memory Barrier 或 Memory Fence,指重排序時不能把後面的指令重排序到記憶體屏障之前的位置),只有一個 CPU 訪問記憶體時,並不需要記憶體屏障;但如果有兩個或更多 CPU 訪問同一塊記憶體,且其中有一個在觀測另一個,就需要記憶體屏障來保證一致性了。這句指令中的 “addl $ 0x0, (%esp)”(把 ESP 暫存器的值加 0)顯然是一個空操作(採用這個空操作而不是空操作指令 nop 是因為 IA32 手冊規定 lock 字首不允許配合 nop 指令使用),關鍵在於 lock 字首,查詢 IA32 手冊,它的作用是使得本 CPU 的 Cache 寫入了記憶體,該寫入動作也會引起別的 CPU 或者別的核心無效化(Invalidate)其 Cache,這種操作相當於對 Cache 中變數做了一次前面介紹 Java 記憶體模式中所說的 “store 和 write” 操作。所以通過這樣一個空操作,可以讓前面 volatile 變數的修改對其他 CPU 立即可見。
那為何說它禁止指令重排序呢?從硬體架構上講,指令重排序是指 CPU 採用了允許將多條指令不按程式規定的順序分開傳送給各相應電路單元處理。但並不是說指令任意重排,CPU 需要能正確處理指令依賴情況以保障程式能得出正確的執行結果。譬如指令 1 把地址 A 中的值加 10,指令 2 把地址 A 中的值乘以 2,指令 3 把地址 B 中的值減去 3,這時指令 1 和 指令 2 是有依賴的,它們之間的順序不能重排——(A + 10)* 2 與 A * 2 + 10 顯然不相等,但指令 3 可以重排到指令 1、2 之前或者中間,只要保證 CPU 執行後面依賴到 A、B 值的操作是能獲取到正確的 A 和 B 值即可。所以在本內 CPU 中,重排序看起來依然是有序的。因此 lock addl $0x0, (%esp) 指令把修改同步到記憶體時,意味著所有之前的操作都已經執行完成,這樣便形成了“指令重排序無法越過記憶體屏障” 的效果。
volatile 能讓我們的程式碼比使用其他的同步工具更快嗎?
在某些情況下,volatile 的同步機制的效能確實要優於鎖(使用 synchronized 關鍵字或 java.util.concurrent 包裡面的鎖),但是由於虛擬機器對鎖實行的許多消除和優化,使得我們很難量化地認為 volatile 就會比 synchronized 快多少。如果讓 volatile 自己與自己比較,那可以確定一個原則:volatile 變數讀操作的效能消耗與普通變數幾乎沒有什麼差別,但是寫操作則可能會慢一些,因為它需要在原生程式碼中插入許多記憶體屏障指令來保證處理器不發生亂序執行。不過即便如此,大多數場景下 volatile 的總開銷仍然要比鎖低,我們在 volatile 與鎖之中選擇的唯一依據僅僅是volatile 的語義能否滿足使用場景的需求。
在本節的最後,我們回頭看一下 Java 記憶體模型中對 volatile 變數定義的特殊規則。假定 T 表示一個執行緒,V 和 W 分別表示兩個 volatile 型變數,那麼在進行 read、load、use、assign、store 和 write 操作時需要滿足如下規則:
- 只有當執行緒 T 對變數 V 執行的前一個動作是 load 的時候,執行緒 T 才能對變數 V 執行 use 動作;並且,只有當執行緒 T 對變數 V 執行的後一個動作是 use 的時候,執行緒 T 才能對變數 V 執行 load 動作。執行緒 T 對變數 V 的 use 動作可以認為是和執行緒 T 對變數 V 的 load、read 動作相關聯,必須連續一起出現(這套規則要求在工作記憶體中,每次使用 V 前都必須先從主記憶體重新整理最新的值,用於保證能看見其他執行緒對變數 V 所做的修改後的值)。
- 只有當執行緒 T 對變數的前一個動作是 assign 的時候,執行緒 T 才能對變數 V 執行 store 動作;並且,只有當執行緒 T 對變數 V 執行的後一個動作是 store 的時候,執行緒 T 才能對變數 V 執行 assign 動作。執行緒 T 對變數 V 的 assign 動作可以認為是和執行緒 T 對變數 V 的 store、write 動作相關聯,必須連續一起出現(這條規則要求在工作記憶體中,每次修改 V 後都必須立刻同步回主記憶體中,用於保證其他執行緒可以看到自己對變數 V 所做的修改)。
- 假定動作 A 是執行緒 T 對變數 V 實施的 use 或 assign 動作,假定動作 F 是和動作 A 相關聯的 load 或 store 動作,假定動作 P 是和動作 F 相應的對變數 V 的 read 或 write 動作;類似的,假定動作 B 是執行緒 T 對變數 W 實施的 use 或 assign 動作,假定動作 G 是和動作 B 相關聯的 load 或 store 動作,假定動作 Q 是和動作 G 相應的對變數 W 的 read 或 write 動作。如果 A 先於 B,那麼 P 先於 Q(這條規則要求 volatile 修飾的變數不會被指令重排序優化,保證程式碼的執行順序與程式的順序相同)。
博主備註:
volatile並不能保證操作的原子性,在讀取、寫入變數的過程中仍然可能被其他執行緒打斷導致意外結果發生。
volatile關鍵字只能保證執行緒讀到最新的,但是不能控制執行緒寫的瞬間那個值還是最新的。
深入理解Java虛擬機器——JVM高階特性與最佳實踐(第2版)PDF版下載:
http://download.csdn.net/detail/xunzaosiyecao/9648998
作者:jiankunking 出處:http://blog.csdn.net/jiankunking
相關文章
- 深入理解Java記憶體模型JMM與volatile關鍵字Java記憶體模型
- Java記憶體模型與volatile關鍵字Java記憶體模型
- Java記憶體模型——volatile關鍵字Java記憶體模型
- 全面理解Java記憶體模型(JMM)及volatile關鍵字Java記憶體模型
- java記憶體模型及volatile關鍵字Java記憶體模型
- 深入理解JVM讀書筆記一: Java記憶體區域與記憶體溢位異常JVM筆記Java記憶體溢位
- 深入理解JVM讀書筆記二: 垃圾收集器與記憶體分配策略JVM筆記記憶體
- 深入理解Java記憶體模型(五)——鎖Java記憶體模型
- 深入理解JVM(一)——JVM記憶體模型JVM記憶體模型
- 深入理解JVM(一)JVM記憶體模型JVM記憶體模型
- JVM讀書筆記之java記憶體結構JVM筆記Java記憶體
- 深入理解JVM(③)學習Java的記憶體模型JVMJava記憶體模型
- 深入理解JVM(1)之--JVM記憶體模型JVM記憶體模型
- JVM讀書筆記之記憶體管理JVM筆記記憶體
- JVM讀書筆記之垃圾收集與記憶體分配JVM筆記記憶體
- JVM記憶體模型(五)JVM記憶體模型
- 《深入理解java虛擬機器》讀書筆記2(java記憶體區域與OOM)Java虛擬機筆記記憶體OOM
- Java併發程式設計:JMM (Java記憶體模型) 以及與volatile關鍵字詳解Java程式設計記憶體模型
- Java記憶體模型_volatileJava記憶體模型
- 深入理解jvm記憶體模型以及gc原理JVM記憶體模型GC
- JVM資料區域與垃圾收集<深入理解JVM讀書筆記>JVM筆記
- Java多執行緒-帶你認識Java記憶體模型,記憶體分割槽,從原理剖析Volatile關鍵字Java執行緒記憶體模型
- 《深入理解Java虛擬機器》讀書筆記:垃圾收集器與記憶體分配策略Java虛擬機筆記記憶體
- Java記憶體模型及volatileJava記憶體模型
- 深入理解JVM-記憶體模型(jmm)和GCJVM記憶體模型GC
- 深入理解Java中的volatile關鍵字Java
- 深入彙編指令理解Java關鍵字volatileJava
- 深入理解JVM之記憶體區域與記憶體溢位JVM記憶體溢位
- 《深入理解java虛擬機器》讀書筆記3(垃圾收集器與記憶體分配策略)Java虛擬機筆記記憶體
- JVM記憶體結構、Java記憶體模型和Java物件模型JVM記憶體Java模型物件
- 《深入java虛擬機器》讀書筆記之Java記憶體區域Java虛擬機筆記記憶體
- 深入理解JVM虛擬機器-JVM記憶體區域與記憶體溢位JVM虛擬機記憶體溢位
- Volatile之Java記憶體模型概念Java記憶體模型
- Java記憶體模型深度解析:volatileJava記憶體模型
- 理解Java記憶體模型Java記憶體模型
- 深入理解JVM之記憶體管理JVM記憶體
- 深入理解 JVM 之 JVM 記憶體結構JVM記憶體
- 深入理解Java記憶體模型(二)——重排序Java記憶體模型排序