MySql 學習筆記三:常用SQL優化
一、group by
在使用group by 分組查詢是,預設分組後,還會排序,可能會降低速度.
比如:
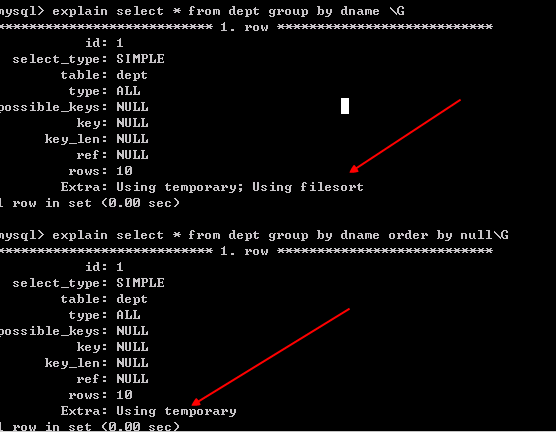
在group by 後面增加 order by null 就可以防止排序.
二、join與子查詢
有些情況下,可以使用連線來替代子查詢。因為使用join,MySQL不需要在記憶體中建立臨時表。
三、如何選擇mysql的儲存引擎?
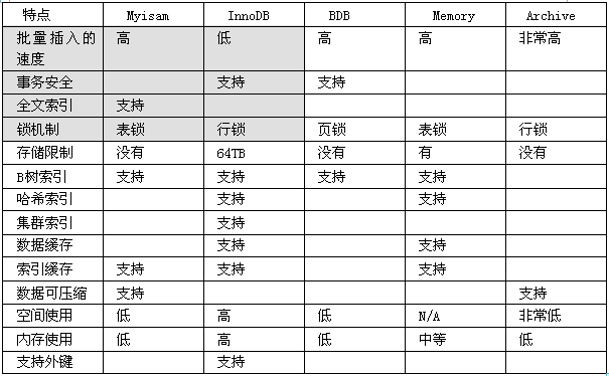
在開發中,我們經常使用的儲存引擎 myisam / innodb/ memory
myisam 儲存: 預設的MySQL儲存引擎。如果應用是以讀操作和插入操作為主,只有很少的更新和刪除操作,並且對事務的完整性要求不是很高。其優勢是訪問的速度快。比如 bbs 中的 發帖表,回覆表.
INNODB 儲存: 提供了具有提交、回滾和崩潰恢復能力的事務安全。但是對比MyISAM,寫的處理效率差一些並且會佔用更多的磁碟空間。儲存的資料都是重要資料,我們建議使用INNODB,比如訂單表,賬號表.
問 MyISAM 和 INNODB的區別
- 事務安全
- 查詢和新增速度
- 支援全文索引
- 鎖機制
- 外來鍵 MyISAM 不支援外來鍵, INNODB支援外來鍵.
Memory 儲存,比如我們資料變化頻繁,不需要入庫,同時又頻繁的查詢和修改,我們考慮使用memory, 速度極快.
如果你的資料庫的儲存引擎是myisam,請一定記住要定時進行碎片整理
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
如果您已經刪除了表的一大部分,或者如果您已經對含有可變長度行的表(含有VARCHAR, BLOB或TEXT列的表)進行了很多更改,則應使用OPTIMIZE TABLE。被刪除的記錄被保持在連結清單中,後續的INSERT操作會重新使用舊的記錄位置。您可以使用OPTIMIZE TABLE來重新利用未使用的空間,並整理資料檔案的碎片。
在多數的設定中,您根本不需要執行OPTIMIZE TABLE。即使您對可變長度的行進行了大量的更新,您也不需要經常執行,每週一次或每月一次即可,只對特定的表執行。
OPTIMIZE TABLE只對MyISAM, BDB和InnoDB表起作用。
對於MyISAM表,OPTIMIZE TABLE按如下方式操作:
如果表已經刪除或分解了行,則修復表。
如果未對索引頁進行分類,則進行分類。
如果表的統計資料沒有更新(並且通過對索引進行分類不能實現修復),則進行更新。
對於BDB表,OPTIMIZE TABLE目前被對映到ANALYZE TABLE上。對於InnoDB表,OPTIMIZE TABLE被對映到ALTER TABLE上,這會重建表。重建操作能更新索引統計資料並釋放成簇索引中的未使用的空間。
使用—skip-new或—safe-mode選項可以啟動mysqld。通過啟動mysqld,您可以使OPTIMIZE TABLE對其它表型別起作用。
注意,在OPTIMIZE TABLE執行過程中,MySQL會鎖定表。
OPTIMIZE TABLE語句被寫入到二進位制日誌中,除非使用了自選的NO_WRITE_TO_BINLOG關鍵詞(或其別名LOCAL)。已經這麼做了,因此,用於MySQL伺服器的OPTIMIZE TABLE命令的作用相當於一個複製主伺服器,在預設情況下,這些命令將被複制到複製從屬伺服器中。
四、大批量插入資料
對於MyISAM:
//防止一邊插入資料一邊建索引
alter table table_name disable keys;
alter table table_name enable keys;對於Innodb:
- 將要匯入的資料按照主鍵排序
- set unique_checks=0,關閉唯一性校驗(防止一邊插入一邊校驗)。
- set autocommit=0,關閉自動提交。
五、選擇合適的資料型別
- 在精度要求高的應用中,建議使用定點數來儲存數值,以保證結果的準確性。deciaml 不要用float
- 對於儲存引擎是MyISAM的資料庫,如果經常做刪除和修改記錄的操作,要定時執行optimize table table_name;功能對錶進行碎片整理。
- 日期型別要根據實際需要選擇能夠滿足應用的最小儲存的早期型別
- 選擇適當的欄位型別,特別是主鍵
選擇欄位的一般原則是保小不保大,能用佔用位元組小的欄位就不用大欄位。比如主鍵, 建議使用自增型別,這樣省空間,空間就是效率!按4個位元組和按32個位元組定位一條記錄,誰快誰慢太明顯了。涉及到 幾個表做join時,效果就更明顯了。
建議使用一個不含業務邏輯的id做主角
六、資料庫引數配置
- 最重要的引數就是記憶體,我們主要用的innodb引擎,所以下面兩個引數調的很大:
innodb_additional_mem_pool_size = 64M
innodb_buffer_pool_size =1G- 對於myisam,需要調整key_buffer_size
當然調整引數還是要看狀態,用show status語句可以看到當前狀態,以決定改調整哪些引數 - 在my.ini修改埠3306,預設儲存引擎和最大連線數
- 如果你的機器記憶體超過4G,那麼毋庸置疑應當採用64位作業系統和64位mysql
- 讀寫分離(mark一下,未用過)
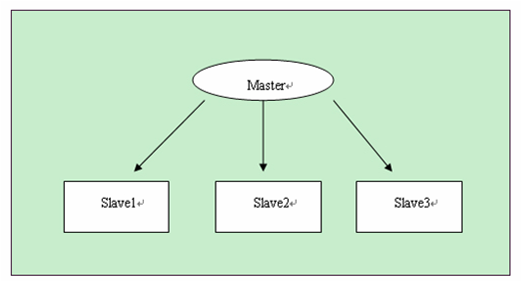
如果資料庫壓力很大,一臺機器支撐不了,那麼可以用mysql複製實現多臺機器同步,將資料庫的壓力分散。
Master
Slave1
Slave2
Slave3
主庫master用來寫入,slave1—slave3都用來做select,每個資料庫分擔的壓力小了很多。
要實現這種方式,需要程式特別設計,寫都操作master,讀都操作slave,給程式開發帶來了額外負擔。當然目前已經有中介軟體來實現這個代理,對程 序來讀寫哪些資料庫是透明的。官方有個mysql-proxy。新浪有個amobe for mysql,也可達到這個目的,結構如下:
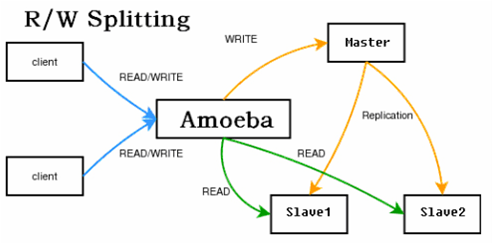
讀寫分離配置檔案下載:http://download.csdn.net/detail/xunzaosiyecao/9646817
本文部分內容整理自itcast講義,在此表示感謝。
作者:jiankunking 出處:http://blog.csdn.net/jiankunking
相關文章
- MySql 學習筆記一:SQL語句優化MySql筆記優化
- mysql優化學習筆記MySql優化筆記
- Mysql 優化(學習筆記二十)MySql優化筆記
- MySQL優化學習筆記之索引MySql優化筆記索引
- MySQL優化學習筆記之explainMySql優化筆記AI
- MySQL優化學習手札(三)MySql優化
- 斜率優化學習筆記優化筆記
- SQL優化筆記SQL優化筆記
- oracle 學習筆記---效能優化學習(1)Oracle筆記優化
- MySQL 優化筆記MySql優化筆記
- 筆記mysql優化筆記MySql優化
- MySQl優化筆記MySql優化筆記
- Oracle Sql優化筆記OracleSQL優化筆記
- [PL/SQL]10g PL/SQL學習筆記(三)SQL筆記
- Android卡頓優化學習筆記Android優化筆記
- HTTPS 效能優化學習筆記HTTP優化筆記
- ORACLE學習筆記--效能優化FAQ。Oracle筆記優化
- oracle 學習筆記---效能優化(1)Oracle筆記優化
- oracle 學習筆記---效能優化(2)Oracle筆記優化
- oracle 學習筆記---效能優化(3)Oracle筆記優化
- oracle 學習筆記---效能優化(4)Oracle筆記優化
- oracle 學習筆記---效能優化(5)Oracle筆記優化
- oracle 學習筆記---效能優化(6)Oracle筆記優化
- oracle 學習筆記---效能優化(7)Oracle筆記優化
- SQL學習筆記SQL筆記
- MySQL 筆記 - 索引優化MySql筆記索引優化
- MySql學習筆記MySql筆記
- SQL優化筆記 [final]SQL優化筆記
- MySQL之SQL優化詳解(三)MySql優化
- Linux學習筆記:常用100條命令(三)Linux筆記
- 面試複習筆記三(sql)面試筆記SQL
- ORACLE學習筆記--效能最佳化三Oracle筆記
- mssql最佳化學習筆記之三SQL筆記
- MySQL事務學習筆記(三) 甚歡篇MySql筆記
- 【記錄】MySQL 學習筆記MySql筆記
- [記錄] MySQL 學習筆記MySql筆記
- Oracle效能優化視訊學習筆記-效能優化概念(一)Oracle優化筆記
- Oracle效能優化視訊學習筆記-效能優化概念(二)Oracle優化筆記