Java Jdk1.8 HashMap原始碼閱讀筆記一
最近在工作用到Map等一系列的集合,於是,想仔細看一下其具體實現。
一、結構
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable1、抽象類AbstractMap
public abstract class AbstractMap<K,V> implements Map<K,V>該類實現了Map介面,具體結構如下:
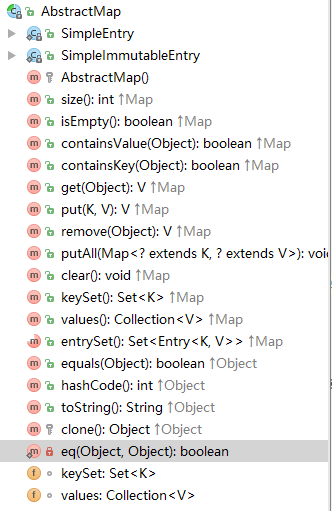
該類程式碼很簡單,不再贅述。
2、序列化介面:Serializable
該介面沒有什麼好說的,但通過該介面,就解釋了為什麼HashMap總一些欄位是用transient來修飾。
一旦變數被transient修飾,變數將不再是物件持久化的一部分,該變數內容在序列化後無法獲得訪問。
二、閱讀JDK中類註釋
1、HashMap是無序的
如果希望保持元素的輸入順序應該使用LinkedHashMap
2、除了非同步和允許使用null之外,HashMap與Hashtable基本一致。
此處的非同步指的是多執行緒訪問,並至少一個執行緒修改HashMap結構。結構修改包括任何新增、刪除對映,但僅僅修改HashMap中已存在項值得操作不屬於結構修改。
3、初始容量與載入因子是影響HashMap的兩個重要因素。
public HashMap(int initialCapacity, float loadFactor)初始容量預設值:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16載入因子預設值:
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;容量是HashMap在建立時“桶”的數量,而初始容量是雜湊表在建立時分配的空間大小。載入因子是雜湊表在其容量自動增加時能達到多滿的衡量尺度(比如預設為0.75,即桶中資料達到3/4就不能再放資料了)。
預設的負載因子大小為0.75,也就是說,當一個map填滿了75%的bucket時候,和其它集合類(如ArrayList等)一樣,將會建立原來HashMap大小的兩倍的bucket陣列,來重新調整map的大小,並將原來的物件放入新的bucket陣列中。這個過程叫作rehashing,因為它呼叫hash方法找到新的bucket位置。
當重新調整HashMap大小的時候,會存在條件競爭,因為如果兩個執行緒都發現HashMap需要重新調整大小了,它們會同時試著調整大小。在調整大小的過程中,儲存在連結串列中的元素的次序會反過來,因為移動到新的bucket位置的時候,HashMap並不會將元素放在連結串列的尾部,而是放在頭部,這是為了避免尾部遍歷(tail traversing)。如果條件競爭發生了,那麼就死迴圈了。
所以 HashMap應該避免在多執行緒環境下使用
預設0.75這是時間和空間成本上一種折衷:增大負載因子可以減少 Hash 表(就是那個 Entry 陣列)所佔用的記憶體空間,但會增加查詢資料的時間開銷,而查詢是最頻繁的的操作(HashMap 的 get() 與 put() 方法都要用到查詢);減小負載因子會提高資料查詢的效能,但會增加 Hash 表所佔用的記憶體空間。
4、儲存形式
(樹形儲存在treemap中再探討)
連結串列形式儲存?樹形結構?
* This map usually acts as a binned (bucketed) hash table, but
* when bins get too large, they are transformed into bins of
* TreeNodes, each structured similarly to those in
* java.util.TreeMap. Most methods try to use normal bins, but
* relay to TreeNode methods when applicable (simply by checking
* instanceof a node). 三、原始碼閱讀
1、新增元素
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//hashmap第一次新增元素,呼叫resize()方法初始化table
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//通過與運算判斷tab[hash]位置是否有值
//從newNode這裡可以看出,hashmap中key value是以Node<K,V>例項的形式存放的
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//tab[i]有元素,則需要遍歷結點後再新增
else {
Node<K,V> e; K k;
// hash、key均等,說明待插入元素和第一個元素相等,直接更新
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果p型別為TreeNode,呼叫樹的新增元素方法(紅黑樹衝突插入)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//不是TreeNode,即為連結串列,遍歷連結串列,查詢給定關鍵字
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//到達連結串列的尾端也沒有找到key值相同的節點,則生成一個新的Node
p.next = newNode(hash, key, value, null);
//建立新節點後若超出樹形化閾值,則轉換為樹形儲存
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//當桶中連結串列的數量>=9的時候,底層則改為紅黑樹實現
break;
}
//如果找到關鍵字相同的結點
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//更新p指向下一個節點
p = e;
}
}
// e不為空,即map中存在要新增的關鍵字
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();//擴容
afterNodeInsertion(evict);
return null;
}小注:
1、回撥
afterNodeAccess(e);
afterNodeInsertion(evict);是為LinkedHashMap回撥準備的。
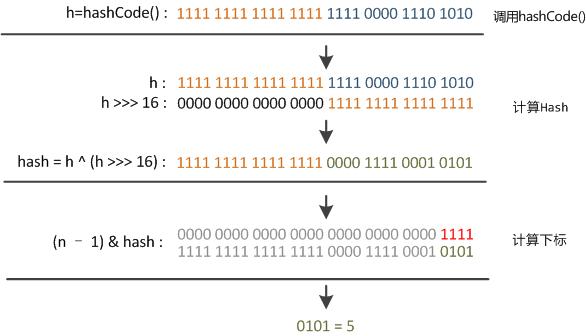
2、計算hash值
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}‘>>>’:無符號右移,忽略符號位,空位都以0補齊
value >>> num – num 指定要移位值value 移動的位數。
即按二進位制形式把所有的數字向右移動對應位數,低位移出(捨棄),高位的空位補零。對於正數來說和帶符號右移相同,對於負數來說不同。
^異或:兩個運算元的位中,相同則結果為0,不同則結果為1。
這也正好解釋了為什麼HashMap底層陣列的長度總是 2 的 n 次方。因為這樣(陣列長度-1)正好相當於一個“低位掩碼”。“異或”操作的結果就是雜湊值的高位全部歸零,只保留低位值,用來做陣列下標訪問。
以初始長度16為例,16-1=15。
2進製表示是00000000 00000000 00001111。
和某hash值做“異或”操作如下,結果就是擷取了最低的四位值。
```
10100101 11000100 00100101
00000000 00000000 00001111
----------------------------------
00000000 00000000 00000101 //高位全部歸零,只保留末四位更詳細的步驟如下:
3、儲存結構
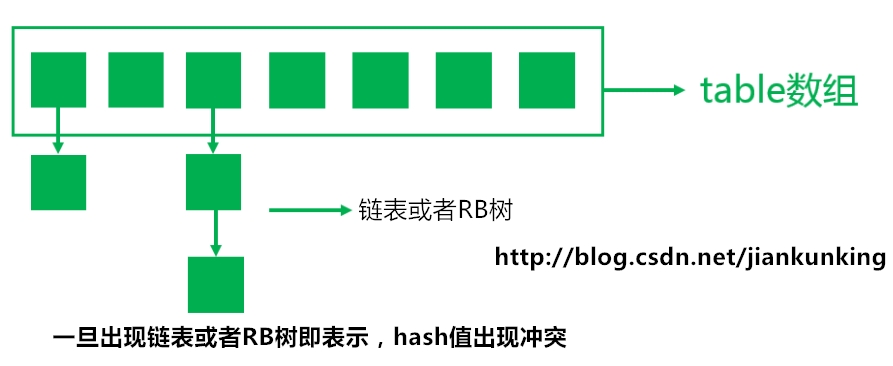
下圖來自網路
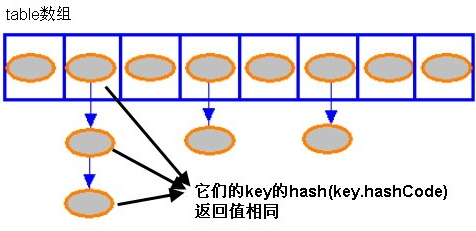
2、獲取元素
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
//hash & length-1 定位陣列下標
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//第一個節點是TreeNode,則採用位桶+紅黑樹結構,
//呼叫TreeNode.getTreeNode(hash,key),
//遍歷紅黑樹,得到節點的value
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}樹節點的查詢:
/**
* Calls find for root node.
*/
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
/**
* Finds the node starting at root p with the given hash and key.
* The kc argument caches comparableClassFor(key) upon first use
* comparing keys.
*通過hash值的比較,遞迴的去遍歷紅黑樹,
compareableClassFor(Class k):判斷例項k對應的類是否實現了Comparable介面,如果實現了該介面並
在某些時候如果紅黑樹節點的元素are of the same "class C implements Comparable<C>" type
*利用他們的compareTo()方法來比較大小,這裡需要通過反射機制來check他們到底是不是屬於同一個類,是不是具有可比較性.
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}四、小結
在建立 HashMap 時根據實際需要適當地調整 load factor 的值;如果程式比較關心空間開銷、記憶體比較緊張,可以適當地增加負載因子;如果程式比較關心時間開銷,記憶體比較寬裕則可以適當的減少負載因子。通常情況下,程式設計師無需改變負載因子的值。
如果開始就知道 HashMap 會儲存多個 key-value 對,可以在建立時就使用較大的初始化容量,如果 HashMap 中 Entry 的數量一直不會超過極限容量(capacity * load factor),HashMap 就無需呼叫 resize() 方法重新分配 table 陣列,從而保證較好的效能。當然,開始就將初始容量設定太高可能會浪費空間(系統需要建立一個長度為 capacity 的 Entry 陣列),因此建立 HashMap 時初始化容量設定也需要小心對待。
1.8中的HashMap類程式碼大約2000多行,此處只挑選了插入、獲取元素兩個比較重要的點,先閱讀記錄一下,後續有時間繼續更新。
個人微信公眾號:

作者:jiankunking 出處:http://blog.csdn.net/jiankunking
相關文章
- JDK原始碼閱讀(4):HashMap類閱讀筆記JDK原始碼HashMap筆記
- JDK1.8原始碼分析筆記-HashMapJDK原始碼筆記HashMap
- java 8 HashMap 原始碼閱讀JavaHashMap原始碼
- JDK1.8原始碼閱讀筆記(1)Object類JDK原始碼筆記Object
- HashMap 原始碼閱讀HashMap原始碼
- HashMap原始碼閱讀HashMap原始碼
- 原始碼閱讀-HashMap原始碼HashMap
- String(JDK1.8)原始碼閱讀記錄JDK原始碼
- JDK1.8 ConcurrentHashMap原始碼閱讀JDKHashMap原始碼
- Java HashMap 原始碼逐行解析(JDK1.8)JavaHashMap原始碼JDK
- python原始碼閱讀筆記Python原始碼筆記
- CopyOnWriteArrayList原始碼閱讀筆記原始碼筆記
- ArrayList原始碼閱讀筆記原始碼筆記
- LinkedList原始碼閱讀筆記原始碼筆記
- guavacache原始碼閱讀筆記Guava原始碼筆記
- LongAdder原始碼閱讀筆記原始碼筆記
- Koa 原始碼閱讀筆記原始碼筆記
- 閱讀原始碼,HashMap回顧原始碼HashMap
- JDK原始碼閱讀:Object類閱讀筆記JDK原始碼Object筆記
- JDK原始碼閱讀:String類閱讀筆記JDK原始碼筆記
- Java原始碼閱讀之TreeMap(紅黑樹) - JDK1.8Java原始碼JDK
- Express Session 原始碼閱讀筆記ExpressSession原始碼筆記
- JDK原始碼閱讀(5):HashTable類閱讀筆記JDK原始碼筆記
- JDK原始碼閱讀(7):ConcurrentHashMap類閱讀筆記JDK原始碼HashMap筆記
- JDK1.8 hashMap原始碼分析JDKHashMap原始碼
- HashMap原始碼分析 JDK1.8HashMap原始碼JDK
- goroutine排程原始碼閱讀筆記Go原始碼筆記
- 【iOS印象】GLPubSub 原始碼閱讀筆記iOS原始碼筆記
- Flask 原始碼閱讀筆記 開篇Flask原始碼筆記
- Redux 學習筆記 – 原始碼閱讀Redux筆記原始碼
- Spring Boot Transactional註解原始碼閱讀筆記(一)Spring Boot原始碼筆記
- JDK原始碼閱讀(3):AbstractStringBuilder、StringBuffer、StringBuilder類閱讀筆記JDK原始碼UI筆記
- JDK1.8原始碼分析之HashMapJDK原始碼HashMap
- 【初學】Spring原始碼筆記之零:閱讀原始碼Spring原始碼筆記
- tomcat8.5.57原始碼閱讀筆記1Tomcat原始碼筆記
- Laravel 訊息通知原始碼閱讀筆記Laravel原始碼筆記
- 【原始碼閱讀】Glide原始碼閱讀之with方法(一)原始碼IDE
- Jdk1.8下的HashMap原始碼分析JDKHashMap原始碼
- 如何閱讀Java原始碼?Java原始碼