大資料時代之hadoop(三):hadoop資料流(生命週期)
瞭解hadoop,首先就需要先了解hadoop的資料流,就像瞭解servlet的生命週期似的。hadoop是一個分散式儲存(hdfs)和分散式計算框架(mapreduce),但是hadoop也有一個很重要的特性:hadoop會將mapreduce計算移動到儲存有部分資料的各臺機器上。
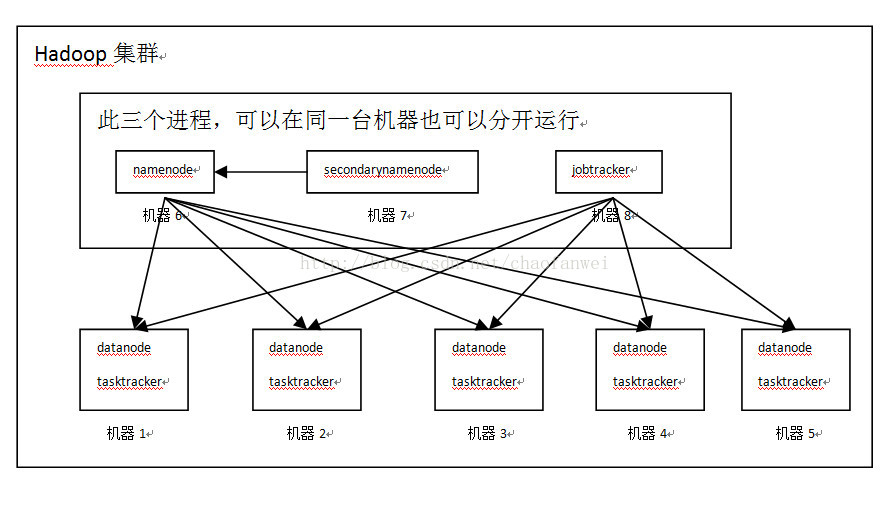
術語
MapReduce 作業(job)是客戶端需要執行的一個工作單元:它包括輸入資料、mapreduce程式和配置資訊。hadoop將作業分成若干個小任務(task)來執行,其中包括兩類任務:map任務和reduce任務。
有兩類節點控制著作業執行過程:一個jobtracker及一系列tasktracker。jobtracker通過排程tasktracker上執行的任務,來協調所有執行在系統上的作業。tasktracker在執行任務的同時將執行進度報告傳送給jobtracker,jobtracker由此記錄每項作業任務的整體進度情況。如果其中一個任務失敗,jobtracker可以在另外一個tasktracker節點上重新排程該任務。
有兩類節點控制著作業執行過程:一個jobtracker及一系列tasktracker。jobtracker通過排程tasktracker上執行的任務,來協調所有執行在系統上的作業。tasktracker在執行任務的同時將執行進度報告傳送給jobtracker,jobtracker由此記錄每項作業任務的整體進度情況。如果其中一個任務失敗,jobtracker可以在另外一個tasktracker節點上重新排程該任務。
輸入
hadoop將mapreduce的輸入資料劃分成等長的小資料塊,稱為輸入分片(input split)或簡稱分片。hadoop為每個分片構建一個map任務,並由該任務來執行使用者自定義的map函式從而處理分片中的每條記錄。
對於大多數作業來說,一個合理的分片大小趨向於HDFS的一個塊的大小,預設是64M,不過可以針對叢集調整這個預設值。分片的大小一定要根據執行的任務來定,如果分片過小,那麼管理分片的總時間和構建map任務的總時間將決定著作業的整個執行時間。
hadoop在儲存有輸入資料的節點上執行map任務,可以獲得最佳效能,這就是所謂的資料本地化優化。因為塊是hdfs儲存資料的最小單元,每個塊可以在多個節點上同時存在(備份),一個檔案被分成的各個塊被隨機分部在多個節點上,因此如果一個map任務的輸入分片跨越多個資料塊,那麼基本上沒有一個節點能夠恰好同時存在這幾個連續的資料塊,那麼map任務就需要首先通過網路將不存在於此節點上的資料塊遠端複製到本節點上再執行map函式,那麼這種任務顯然效率非常低。
輸出
map任務將其輸出寫入到本地磁碟,而非HDFS。這是因為map的輸出是中間結果:該中間結果有reduce任務處理後才產生最終結果(儲存在hdfs中)。而一旦作業完成,map的輸出結果可以被刪除。
reduce任務並不具備資料本地化優勢:單個reduce任務的輸入通常來自於所有的mapper任務的輸出。reduce任務的輸出通常儲存於HDFS中以實現可靠儲存。
資料流
作業根據設定的reduce任務的個數不同,資料流也不同,但大同小異。reduce任務的數量並非由輸入資料的大小決定的,而是可以通過手動配置指定的。
單個reduce任務
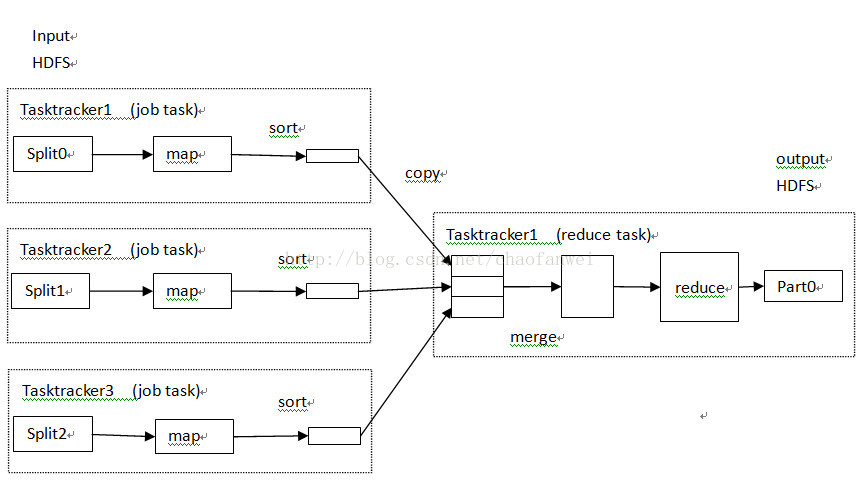
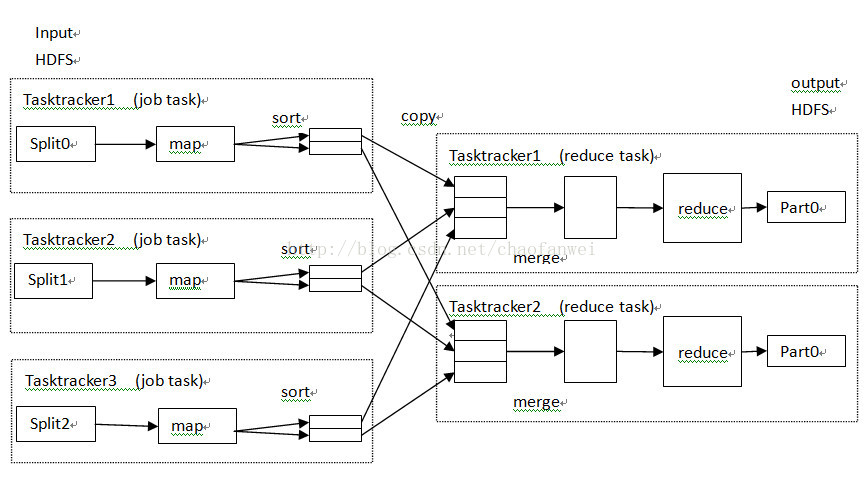
多個reduce任務
如果是多個reduce任務的話,則每個map任務都會對其輸出進行分割槽(partition),即為每個reduce任務建立一個分割槽。分割槽有使用者定義的分割槽函式控制,預設的分割槽器(partitioner) 通過雜湊函式來分割槽。
map任務和reduce任務之間的資料流稱為shuffle(混洗)。
map任務和reduce任務之間的資料流稱為shuffle(混洗)。
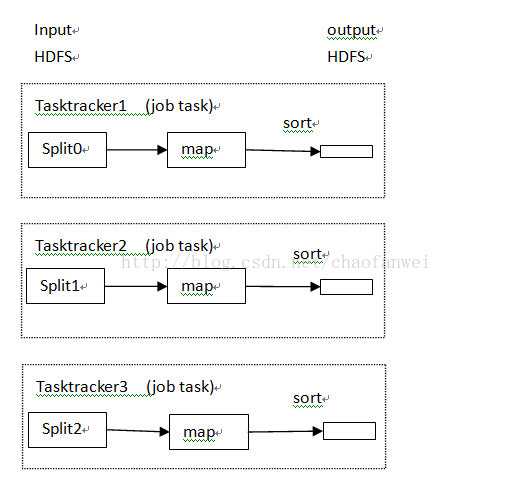
沒有reduce任務
當然也可能出現不需要執行reduce任務的情況,即資料可以完全的並行。
combiner(合併函式)
順便在這說下combiner吧,hadoop執行使用者針對map任務的輸出指定一個合併函式,合併函式的輸出作為reduce函式的輸入。其實合併函式就是一個優化方案,說白了就是在map任務執行後在本機先執行合併函式(通常就是reduce函式的拷貝),減少網路傳輸量。
相關文章
- 大資料時代之hadoop(一):hadoop安裝大資料Hadoop
- 大資料時代之hadoop(二):hadoop指令碼解析大資料Hadoop指令碼
- 大資料時代之hadoop(五):hadoop 分散式計算框架(MapReduce)大資料Hadoop分散式框架
- ReactJS 生命週期、資料流與事件ReactJS事件
- 大資料時代之hadoop(四):hadoop 分散式檔案系統(HDFS)大資料Hadoop分散式
- 大資料hadoop資料大資料Hadoop
- 大資料測試之hadoop初探大資料Hadoop
- 大資料時代之hadoop(六):hadoop 生態圈(pig,hive,hbase,ZooKeeper,Sqoop)大資料HadoopHive
- 大資料hadoop工具大資料Hadoop
- Hadoop大資料部署Hadoop大資料
- 大資料學習之Hadoop如何高效處理大資料大資料Hadoop
- hadoop 大資料精品視訊資料Hadoop大資料
- 大資料之 Hadoop學習筆記大資料Hadoop筆記
- Hadoop大資料平臺之HBase部署Hadoop大資料
- Hadoop大資料平臺之Kafka部署Hadoop大資料Kafka
- 大資料hadoop入門之hadoop家族產品詳解大資料Hadoop
- Hadoop大資料實戰系列文章之安裝HadoopHadoop大資料
- Django ORM 資料庫生命週期DjangoORM資料庫
- 淺談資料庫生命週期資料庫
- **大資料hadoop瞭解**大資料Hadoop
- 大資料技術之Hadoop(入門) 第2章 從Hadoop框架討論大資料生態大資料Hadoop框架
- 大資料之Hadoop偽分散式的搭建大資料Hadoop分散式
- 小白學習大資料測試之hadoop大資料Hadoop
- 感知生命週期的資料 -- LiveDataLiveData
- 淺析大資料框架 Hadoop大資料框架Hadoop
- 大資料技術之Hadoop(入門)第1章 大資料概論大資料Hadoop
- 大資料和Hadoop什麼關係?為什麼大資料要學習Hadoop?大資料Hadoop
- Hadoop系列之HDFS 資料塊Hadoop
- Hadoop大資料實戰系列文章之HiveHadoop大資料Hive
- Hadoop大資料實戰系列文章之HBaseHadoop大資料
- Hadoop大資料實戰系列文章之ZookeeperHadoop大資料
- 12c ILM資料生命週期管理
- Hadoop資料模型Hadoop模型
- 大資料7.1 - hadoop叢集搭建大資料Hadoop
- Hadoop的大資料分析技術Hadoop大資料
- Hadoop資料傳輸:如何將資料移入和移出Hadoop?Hadoop
- Hadoop 之 NameNode 後設資料原理Hadoop
- 大資料系列分享第二期:《Hadoop生態圈》大資料Hadoop