一、前言
在分析了ArrayList了之後,緊接著必須要分析它的同胞兄弟:LinkedList,LinkedList與ArrayList在底層的實現上有所不同,其實,只要我們有資料結構的基礎,在分析原始碼的時候就會很簡單,下面進入正題,LinkedList原始碼分析。
二、LinkedList資料結構
還是老規矩,先抓住LinkedList的核心部分:資料結構,其資料結構如下

說明:如上圖所示,LinkedList底層使用的雙向連結串列結構,有一個頭結點和一個尾結點,雙向連結串列意味著我們可以從頭開始正向遍歷,或者是從尾開始逆向遍歷,並且可以針對頭部和尾部進行相應的操作。
三、LinkedList原始碼分析
3.1 類的繼承關係
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
說明:LinkedList的類繼承結構很有意思,我們著重要看是Deque介面,Deque介面表示是一個雙端佇列,那麼也意味著LinkedList是雙端佇列的一種實現,所以,基於雙端佇列的操作在LinkedList中全部有效。
3.2 類的內部類


private static class Node<E> { E item; // 資料域 Node<E> next; // 後繼 Node<E> prev; // 前驅 // 建構函式,賦值前驅後繼 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
說明:內部類Node就是實際的結點,用於存放實際元素的地方。
3.3 類的屬性
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable { // 實際元素個數 transient int size = 0; // 頭結點 transient Node<E> first; // 尾結點 transient Node<E> last; }
說明:LinkedList的屬性非常簡單,一個頭結點、一個尾結點、一個表示連結串列中實際元素個數的變數。注意,頭結點、尾結點都有transient關鍵字修飾,這也意味著在序列化時該域是不會序列化的。
3.4 類的建構函式
1. LinkedList()型建構函式
public LinkedList() { }
2. LinkedList(Collection<? extends E>)型建構函式
public LinkedList(Collection<? extends E> c) { // 呼叫無參建構函式 this(); // 新增集合中所有的元素 addAll(c); }
說明:會呼叫無參建構函式,並且會把集合中所有的元素新增到LinkedList中。
3.5 核心函式分析
1. add函式
public boolean add(E e) { // 新增到末尾 linkLast(e); return true; }
說明:add函式用於向LinkedList中新增一個元素,並且新增到連結串列尾部。具體新增到尾部的邏輯是由linkLast函式完成的。
void linkLast(E e) { // 儲存尾結點,l為final型別,不可更改 final Node<E> l = last; // 新生成結點的前驅為l,後繼為null final Node<E> newNode = new Node<>(l, e, null); // 重新賦值尾結點 last = newNode; if (l == null) // 尾結點為空 first = newNode; // 賦值頭結點 else // 尾結點不為空 l.next = newNode; // 尾結點的後繼為新生成的結點 // 大小加1 size++; // 結構性修改加1 modCount++; }
說明:對於新增一個元素至連結串列中會呼叫add方法 -> linkLast方法。
對於新增元素的情況我們使用如下示例進行說明
示例一程式碼如下(只展示了核心程式碼)
List<Integer> lists = new LinkedList<Integer>(); lists.add(5); lists.add(6);
說明:首先呼叫無參建構函式,之後新增元素5,之後再新增元素6。具體的示意圖如下:
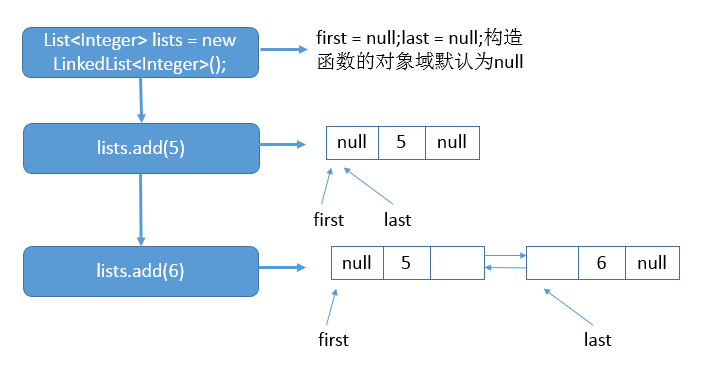
說明:上圖的表明了在執行每一條語句後,連結串列對應的狀態。
2. addAll函式
addAll有兩個過載函式,addAll(Collection<? extends E>)型和addAll(int, Collection<? extends E>)型,我們平時習慣呼叫的addAll(Collection<? extends E>)型會轉化為addAll(int, Collection<? extends E>)型,所以我們著重分析此函式即可。
// 新增一個集合 public boolean addAll(int index, Collection<? extends E> c) { // 檢查插入的的位置是否合法 checkPositionIndex(index); // 將集合轉化為陣列 Object[] a = c.toArray(); // 儲存集合大小 int numNew = a.length; if (numNew == 0) // 集合為空,直接返回 return false; Node<E> pred, succ; // 前驅,後繼 if (index == size) { // 如果插入位置為連結串列末尾,則後繼為null,前驅為尾結點 succ = null; pred = last; } else { // 插入位置為其他某個位置 succ = node(index); // 尋找到該結點 pred = succ.prev; // 儲存該結點的前驅 } for (Object o : a) { // 遍歷陣列 @SuppressWarnings("unchecked") E e = (E) o; // 向下轉型 // 生成新結點 Node<E> newNode = new Node<>(pred, e, null); if (pred == null) // 表示在第一個元素之前插入(索引為0的結點) first = newNode; else pred.next = newNode; pred = newNode; } if (succ == null) { // 表示在最後一個元素之後插入 last = pred; } else { pred.next = succ; succ.prev = pred; } // 修改實際元素個數 size += numNew; // 結構性修改加1 modCount++; return true; }
說明:引數中的index表示在索引下標為index的結點(實際上是第index + 1個結點)的前面插入。在addAll函式中,addAll函式中還會呼叫到node函式,get函式也會呼叫到node函式,此函式是根據索引下標找到該結點並返回,具體程式碼如下
Node<E> node(int index) { // 判斷插入的位置在連結串列前半段或者是後半段 if (index < (size >> 1)) { // 插入位置在前半段 Node<E> x = first; for (int i = 0; i < index; i++) // 從頭結點開始正向遍歷 x = x.next; return x; // 返回該結點 } else { // 插入位置在後半段 Node<E> x = last; for (int i = size - 1; i > index; i--) // 從尾結點開始反向遍歷 x = x.prev; return x; // 返回該結點 } }
說明:在根據索引查詢結點時,會有一個小優化,結點在前半段則從頭開始遍歷,在後半段則從尾開始遍歷,這樣就保證了只需要遍歷最多一半結點就可以找到指定索引的結點。
下面通過示例來更深入瞭解呼叫addAll函式後的連結串列狀態。
List<Integer> lists = new LinkedList<Integer>(); lists.add(5); lists.addAll(0, Arrays.asList(2, 3, 4, 5));
上述程式碼內部的連結串列結構如下:
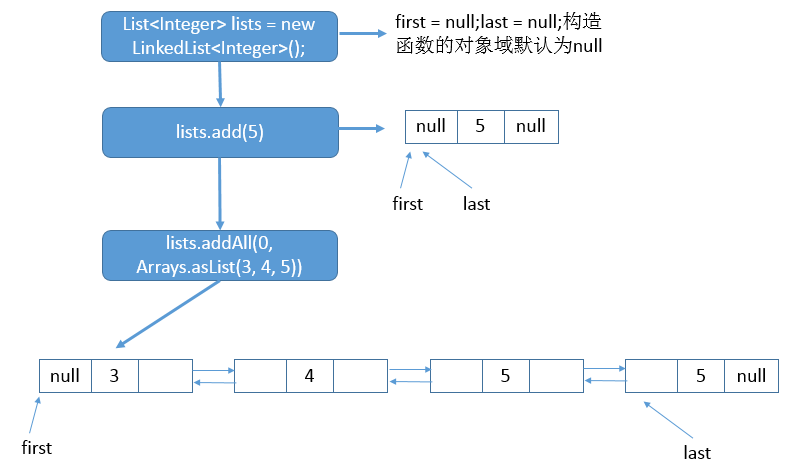
3. unlink函式
在呼叫remove移除結點時,會呼叫到unlink函式,unlink函式具體如下:
E unlink(Node<E> x) { // 儲存結點的元素 final E element = x.item; // 儲存x的後繼 final Node<E> next = x.next; // 儲存x的前驅 final Node<E> prev = x.prev; if (prev == null) { // 前驅為空,表示刪除的結點為頭結點 first = next; // 重新賦值頭結點 } else { // 刪除的結點不為頭結點 prev.next = next; // 賦值前驅結點的後繼 x.prev = null; // 結點的前驅為空,切斷結點的前驅指標 } if (next == null) { // 後繼為空,表示刪除的結點為尾結點 last = prev; // 重新賦值尾結點 } else { // 刪除的結點不為尾結點 next.prev = prev; // 賦值後繼結點的前驅 x.next = null; // 結點的後繼為空,切斷結點的後繼指標 } x.item = null; // 結點元素賦值為空 // 減少元素實際個數 size--; // 結構性修改加1 modCount++; // 返回結點的舊元素 return element; }
說明:將指定的結點從連結串列中斷開,不再累贅。
四、針對LinkedList的思考
1. 對addAll函式的思考
在addAll函式中,傳入一個集合引數和插入位置,然後將集合轉化為陣列,然後再遍歷陣列,挨個新增陣列的元素,但是問題來了,為什麼要先轉化為陣列再進行遍歷,而不是直接遍歷集合呢?從效果上兩者是完全等價的,都可以達到遍歷的效果。關於為什麼要轉化為陣列的問題,我的思考如下:1. 如果直接遍歷集合的話,那麼在遍歷過程中需要插入元素,在堆上分配記憶體空間,修改指標域,這個過程中就會一直佔用著這個集合,考慮正確同步的話,其他執行緒只能一直等待。2. 如果轉化為陣列,只需要遍歷集合,而遍歷集合過程中不需要額外的操作,所以佔用的時間相對是較短的,這樣就利於其他執行緒儘快的使用這個集合。說白了,就是有利於提高多執行緒訪問該集合的效率,儘可能短時間的阻塞。
五、總結
分析完了LinkedList原始碼,其實很簡單,值得注意的是LinkedList可以作為雙端佇列使用,這也是佇列結構在Java中一種實現,當需要使用佇列結構時,可以考慮LinkedList。謝謝各位園友觀看~