一、前言
在前面的解決亂碼的一文中,只找到瞭解決辦法,但是沒有為什麼,說白了,就是對編碼還是不是太熟悉,編碼問題是一個很簡單的問題,計算機從業人員應該也必須弄清楚,基於編碼的應用有Base64加密演算法,然後,這個問題一直放著,想找個機會解決。於是乎,終於逮到機會,開始下手。
二、編碼
關於ASCII、Unicode編碼、UTF-8編碼等問題,可以參見筆者另外一篇部落格【字元編碼】徹底理解字元編碼。
三、Base64演算法
Base64是網路上最常見的用於傳輸8Bit位元組程式碼的編碼方式之一,關於Base64的介紹可以參見這兩篇文章base64,BASE64演算法,下面我們通過Java來實現Base64編碼演算法並且詳細解析其中遇到的問題。
Base64編碼演算法的流程圖如下:
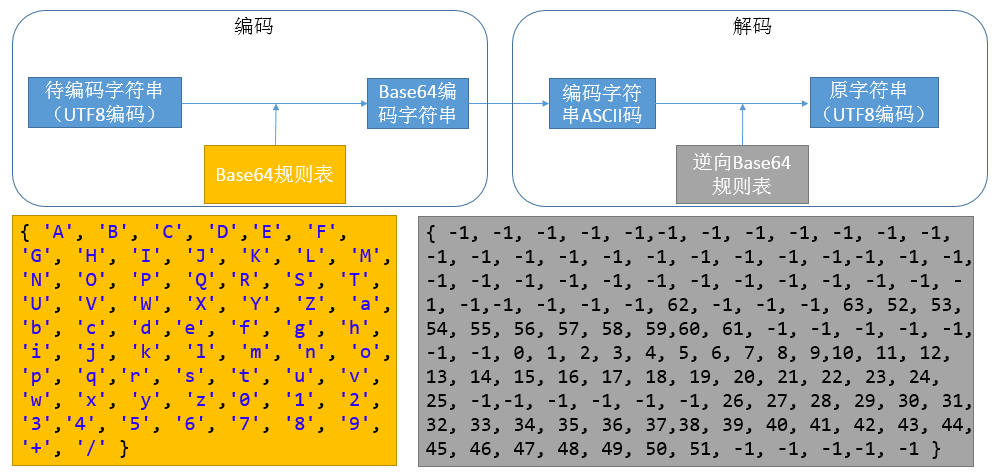
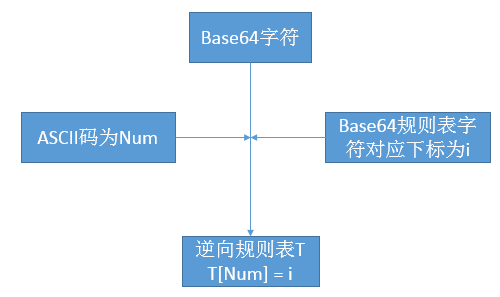
說明:Base64規則表由Base64的規定的規則得到,而逆向Base64規則表則通過少量的計算獲得,如某Base64的編碼字串為QQ==,對於字元Q而言,Q的ASCII編碼為81,Base64規則中,16對應Q,則將逆向Base64表中下標為81的項置為16。其餘不在Base64中的元素在逆向表中值為-1,逆向表的計算流程如下:
四、Base64演算法的Java實現
Java中的字元都是以Unicode格式進行儲存的,如何檢視任一個字元在Java中的表示?使用如下程式碼即可


import java.io.UnsupportedEncodingException; public class Test { public static void main(String[] args) throws UnsupportedEncodingException { String str = "張"; byte[] bytes = str.getBytes("utf-8"); for (int i = 0; i < bytes.length; i++) { System.out.print(Integer.toHexString(bytes[i] & 0xff).toUpperCase() + " "); } } }
執行結果:
E5 BC A0
說明:假設中文張的編碼為GBK,則轉化為UTF-8編碼經過了GBK->Unicode->UTF-8的步驟。
Base64演算法程式碼清單
package com.leesf.chapter10; import java.io.UnsupportedEncodingException; public class Base64 { private static char[] base64EncodeChars = new char[] { 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/' }; private static byte[] base64DecodeChars = new byte[] { -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1 }; public static String encode(byte[] data) { StringBuffer sb = new StringBuffer(); int len = data.length; int i = 0; int b1, b2, b3; while (i < len) { // 提取b1 b1 = data[i++] & 0xff; if (i == len) { // len % 3 == 1 // 向右無符號移動2位,保留b1的0-5位(前六位) sb.append(base64EncodeChars[b1 >>> 2]); // 保留b1的6-7位(後兩位),其餘位為0,然後向左移動4位,低位補0 sb.append(base64EncodeChars[(b1 & 0x3) << 4]); // 新增兩個等號(Base64規則) sb.append("=="); // 跳出迴圈 break; } // 提取b2 b2 = data[i++] & 0xff; if (i == len) { // len % 3 == 2 // 保留b1的0-5位(前六位),其餘位為0 sb.append(base64EncodeChars[b1 >>> 2]); // 保留b1的6-7位(後兩位),其餘位為0,然後向左移動4位,低位補0 // 然後保留b2的0-3位(前四位),然後合併 sb.append(base64EncodeChars[((b1 & 0x03) << 4) | ((b2 & 0xf0) >>> 4)]); sb.append(base64EncodeChars[(b2 & 0x0f) << 2]); // 新增兩個等號(Base64規則) sb.append("="); // 跳出迴圈 break; } // 提取b3 b3 = data[i++] & 0xff; // 向右無符號移動2位,保留b1的0-5位(前六位) sb.append(base64EncodeChars[b1 >>> 2]); // 保留b1的6-7位(後兩位),其餘位為0,然後向左移動4位,低位補0 // 然後保留b2的0-3位(前四位),然後合併 sb.append(base64EncodeChars[((b1 & 0x03) << 4) | ((b2 & 0xf0) >>> 4)]); // 保留b2的4-7位(後四位),然後向右移2位,低位補0, // 然後保留b3的0-1位(前兩位),然後合併 sb.append(base64EncodeChars[((b2 & 0x0f) << 2) | ((b3 & 0xc0) >>> 6)]); // 保留b3的2-7位(後六位) sb.append(base64EncodeChars[b3 & 0x3f]); } return sb.toString(); } public static byte[] decode(String str) throws UnsupportedEncodingException { // 使用ISO8859-1搭配其他編碼如UTF-8,GBK可以顯示中文 StringBuffer sb = new StringBuffer(); // 獲取ASCII碼 byte[] data = str.getBytes("US-ASCII"); int len = data.length; int i = 0; int b1, b2, b3, b4; while (i < len) { do { b1 = base64DecodeChars[data[i++]]; } while (i < len && b1 == -1); if (b1 == -1) break; do { b2 = base64DecodeChars[data[i++]]; } while (i < len && b2 == -1); if (b2 == -1) break; // b1向左移2位,然後b2保留2-3位,再向右無符號移動4位,再合併 sb.append((char) ((b1 << 2) | ((b2 & 0x30) >>> 4))); do { b3 = data[i++]; if (b3 == 61) // 遇到了=號,結束,返回 return sb.toString().getBytes("ISO8859-1"); b3 = base64DecodeChars[b3]; } while (i < len && b3 == -1); if (b3 == -1) break; // 提取b2的4-7位(後四位),再向左移動4位,b3保留2-5位,再向右無符號移動2位 sb.append((char) (((b2 & 0x0f) << 4) | ((b3 & 0x3c) >>> 2))); do { b4 = data[i++]; if (b4 == 61) // 遇到了=號,結束,返回 return sb.toString().getBytes("ISO8859-1"); b4 = base64DecodeChars[b4]; } while (i < len && b4 == -1); if (b4 == -1) break; // 提取b3的6-7位(最後兩位),再向左移動6位,再取b4的2-7位(後六位),然後合併b4 sb.append((char) (((b3 & 0x03) << 6) | (b4 & 0x3f))); } return sb.toString().getBytes("ISO8859-1"); } public static void main(String[] args) throws UnsupportedEncodingException { String s = "張"; System.out.println("編碼前:" + s); String x = encode(s.getBytes()); System.out.println("編碼後:" + x); String x1 = new String(decode(x)); System.out.println("解碼後:" + x1); } }
執行結果:
編碼前:張
編碼後:5byg
解碼後:張
說明:理解了Base64的編碼解碼過程,那麼程式碼也很好理解。
五、總結
經過此篇博文,對字元編碼的理解更深刻了,明白了字元編碼之間的如何進行轉化,有了這個基礎後,再看其他與字元編碼相關的知識將更容易,特此記錄,以後遇到與字元編碼相關的問題還會進行記錄。謝謝各位園友觀看~