圖解Protobuf編碼
圖解Protobuf編碼
Protobuf是Google釋出的訊息序列化工具。Protobuf定義了訊息描述語法(proto語法)和訊息編碼格式,並且提供了主流語言的程式碼生成器(protoc)。本文僅討論Protobuf訊息編碼格式,並且假定讀者已經熟悉Protobuf訊息描述語法(proto2或者proto3)。
基本編碼規則
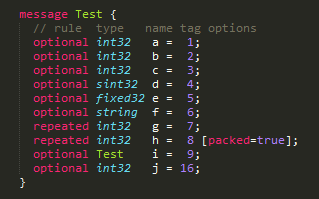
Protobuf訊息由欄位(field)構成,每個欄位有其規則(rule)、資料型別(type)、欄位名(name)、tag,以及選項(option)。比如下面這段程式碼描述了由10個欄位構成的Test訊息:
序列化時,訊息欄位會按照tag順序,以key+val的格式,編碼成二進位制資料。以下面這段Java程式碼為例:
byte[] data = Test.newBuilder()
.setA(3).setB(2).setC(1)
.build().toByteArray();序列化之後,可以把data裡的資料想象成下面這樣:

proto2語法定義了3種欄位規則:required、optional、repeated。proto3語法去掉了required規則,只剩下optional(預設)和repeated兩種。由上圖可知,如果沒有給optional和repeated欄位賦值,那麼欄位是不會出現在序列化後的資料中的。詳細的編碼規則,請繼續閱讀。
資料劃分
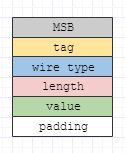
Protobuf訊息序列化之後,會產生二進位制資料。這些資料(精確到bit)按照含義不同,可以劃分為6個部分:MSB flag、tag、編碼後資料型別(wire type)、長度(length)、欄位值(value)、以及填充(padding)。後文會圖解這些部分的具體含義,這裡先約定好圖中訊息各部分使用的顏色:
Key+Value
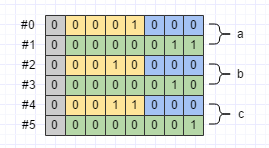
前面說過,訊息的每一個欄位,都會以key+val的形式,序列化為二進位制資料。val比較好猜測,那麼key具體是什麼呢?答案是這樣:key = tag << 3 | wire_type。也就是說,key的前3個位元是wire type,剩下的位元是tag值。Protobuf支援豐富的資料型別,但是編碼之後,只剩下Varint(0)、64-bit(1)、Length-delimited(2)和32-bit(5)這4種(還有兩種已經廢棄了,本文不討論)型別,用3個位元來表示,足夠了。以前面定義的Test訊息為例:
byte[] data = Test.newBuilder()
.setA(3).setB(2).setC(1)
.build().toByteArray();序列化之後的資料有6個位元組,是下面這個樣子:
Varint
用3個bit來表示wire type是夠了,但是tag是用剩下的5個bit來表示嗎?tag難道不能超過32(2^5)嗎?由上圖已經知道,答案是否!為了用盡可能少的位元組編碼訊息,Protobuf在多處都使用了Varint這種格式。比如資料型別裡的int32、int64,以及tag值和後面將要解釋的length值,都使用Varint型別儲存。那麼Varint到底有什麼神奇之處呢?也沒有,其實就是用每個位元組的前7個bit來表示資料,而最高位的bit(MSB,Most Significant Bit)則用作記號(flag)。文字不太好描述,看一個例子:
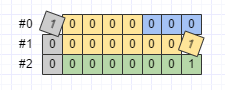
byte[] data2 = Test.newBuilder()
.setJ(1) // tag=16
.build().toByteArray();由於tag是按Varint編碼的,所以要扣掉一個bit(MSB)。再減去wire type佔用的3個位元,那麼第一個位元組裡,留給tag值的,實際只剩下4個位元,只能表示0到15。由於Test訊息j欄位的tag值是16,所以需要兩個位元組才能表示j欄位的key。data2如下圖所示(重要的bit進行了旋轉,以示提醒):
64-bit和32-bit
前面說了,為了節省位元組數,tag、length,以及int32、int64等資料型別都是用Varint編碼的。那麼這種編碼方式有什麼壞處嗎?主要有2處。第一,不利於表示大數。對於比較小的數來說,以0到127為例,用Varint很划算。以浪費1bit和少量額外的計算為代價,只要1個位元組就可以表示。但是對於比較大的數,就不划算了。以int32為例,大於2^(4*7) - 1的數,需要用5個位元組來表示。看一個例子:
byte[] data3 = Test.newBuilder()
.setA(268435456) // 2^28
.build()
.toByteArray();序列化之後的資料如下圖所示:
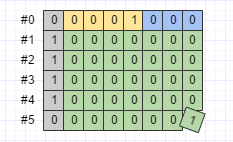
也就是說,如果某個訊息的某個int欄位大部分時候都會取比較大的數,那麼這個欄位使用Varint這種變長型別來編碼就沒什麼好處。對於這種情況,Protobuf定義了64-bit和32-bit兩種定長編碼型別。使用64-bit編碼的資料型別包括fixed64、sfixed64和double;使用32-bit編碼的資料型別包括fixed32、sfixed32和float。以Test訊息e欄位(fixed32)為例:
byte[] data4 = Test.newBuilder()
.setE(268435456) // 2^28
.build()
.toByteArray();序列化之後的資料如下圖所示:
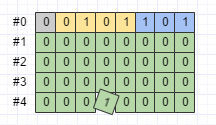
ZigZag
Varint編碼格式的第二缺點是不適合表示負數,以int32和-1為例:
byte[] data5 = Test.newBuilder()
.setA(-1)
.build()
.toByteArray();Protobuf想讓int32和int64在編碼格式上相容,所以-1需要佔用10個位元組,如下圖所示:
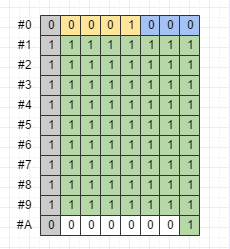
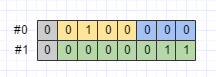
為了克服這個缺陷,Protobuf提供了sint32和sint64兩種資料型別。如果某個訊息的某個欄位出現負數值的可能性比較大,那麼應該使用sint32或sint64。這兩種資料型別在編碼時,會先使用ZigZig編碼將負數對映成正數,然後再使用Varint編碼。ZigZag編碼規則如下圖所示:
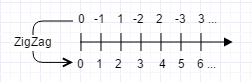
以Test訊息的d欄位(sint32)為例:
byte[] data6 = Test.newBuilder()
.setD(-2) // sint32
.build()
.toByteArray();序列化之後的資料如下圖所示:
Length-delimited
如前所述,64-bit和32-bit是定長編碼格式,長度固定。Varint是變長編碼格式,長度由位元組的MSB決定。Length-delimited編碼格式則會將資料的length也編碼進最終資料,使用Length-delimited編碼格式的資料型別包括string、bytes和自定義訊息。以string為例:
byte[] data7 = Test.newBuilder()
.setF("hello") // string
.build()
.toByteArray();序列化之後的資料如下圖所示:
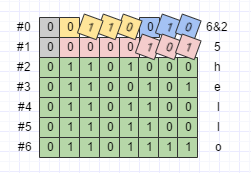
下面是自定義訊息的例子:
byte[] data8 = Test.newBuilder()
.setI(Test.newBuilder().setA(1))
.build()
.toByteArray();序列化之後的資料如下圖所示:
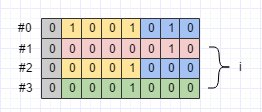
repeated
前面討論的欄位都是optional型別,最多隻有一個val,但是repeated欄位卻可以有多個val。那麼repeated欄位是如何序列化的呢?以Test訊息的g欄位為例:
byte[] data9 = Test.newBuilder()
.addG(1).addG(2).addG(3)
.build()
.toByteArray();序列化之後的資料如下圖所示:
可見,repeated欄位就是簡單的把每個欄位值依次序列化而已。
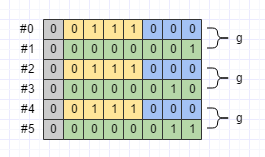
packed
如果repeated欄位包含的val比較多,那麼每個val都帶上key是不是比較浪費呢?是的,所以Protobuf提供了packed選項,以Test訊息的h欄位為例:
byte[] data10 = Test.newBuilder()
.addH(1).addH(2).addH(3) // packed
.build()
.toByteArray();序列化之後的資料如下圖所示:
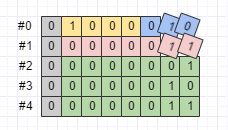
可見,如果repeated欄位設定了packed選項,則會使用Length-delimited格式來編碼欄位值。
結束。
相關文章
- Protobuf 編碼指南
- google protocol buffer——protobuf的編碼原理二GoProtocol
- 用Go例項學習Protobuf編碼Go
- 高效的資料壓縮編碼方式 Protobuf
- google protocol buffer——protobuf的使用特性及編碼原理GoProtocol
- eKuiper Newsletter 2022-05|protobuf 編解碼支援、視覺化拖拽編寫規則UI視覺化
- cygwin下ndk編譯protobuf編譯
- ubuntu編譯grpc & protobufUbuntu編譯RPC
- protobuf 生成 Go 程式碼外掛 gogo/protobufGo
- ProtoBuf 反射詳解反射
- 如何編寫 ProtoBuf 外掛 (一) ?
- 如何編寫 ProtoBuf 外掛 (二) ?
- 如何編寫 ProtoBuf 外掛 (三) ?
- 深入瞭解圖片Base64編碼
- protobuf 編譯工具安裝與使用編譯
- Go - 如何編寫 ProtoBuf 外掛 (三) ?Go
- Go - 如何編寫 ProtoBuf 外掛(二)?Go
- Go - 如何編寫 ProtoBuf 外掛 (一) ?Go
- protobuf 的交叉編譯使用(C++)編譯C++
- 圖解字元編碼圖解字元
- Derek解讀Bytom原始碼-protobuf生成比原核心程式碼原始碼
- Protobuf 生成 Go 程式碼指南Go
- grpc系列- protobuf詳解RPC
- 【記錄】編譯安裝 ProtoBuf 擴充套件編譯套件
- [記錄] 編譯安裝 ProtoBuf 擴充套件編譯套件
- Javascript編碼解碼URLJavaScript
- Unicode編碼解碼Unicode
- IM通訊協議專題學習(三):由淺入深,從根上理解Protobuf的編解碼原理協議
- URL編碼與解碼原理
- iOS Emoji表情編碼/解碼iOS
- OpenLR 的編碼與解碼
- Protobuf
- 《Grpc+Protobuf學習筆記》一、protobuf安裝生成程式碼外掛RPC筆記
- 《Grpc+Protobuf學習筆記》二、protobuf安裝生成程式碼外掛RPC筆記
- Go JSON編碼與解碼?GoJSON
- 3.3 編碼/解碼演算法演算法
- Base64 編碼解碼原理
- Sql Server UniCode編碼解碼SQLServerUnicode