一、前言
前面學習了Zookeeper服務端的相關細節,其中對於叢集啟動而言,很重要的一部分就是Leader選舉,接著就開始深入學習Leader選舉。
二、Leader選舉
2.1 Leader選舉概述
Leader選舉是保證分散式資料一致性的關鍵所在。當Zookeeper叢集中的一臺伺服器出現以下兩種情況之一時,需要進入Leader選舉。
(1) 伺服器初始化啟動。
(2) 伺服器執行期間無法和Leader保持連線。
下面就兩種情況進行分析講解。
1. 伺服器啟動時期的Leader選舉
若進行Leader選舉,則至少需要兩臺機器,這裡選取3臺機器組成的伺服器叢集為例。在叢集初始化階段,當有一臺伺服器Server1啟動時,其單獨無法進行和完成Leader選舉,當第二臺伺服器Server2啟動時,此時兩臺機器可以相互通訊,每臺機器都試圖找到Leader,於是進入Leader選舉過程。選舉過程如下
(1) 每個Server發出一個投票。由於是初始情況,Server1和Server2都會將自己作為Leader伺服器來進行投票,每次投票會包含所推舉的伺服器的myid和ZXID,使用(myid, ZXID)來表示,此時Server1的投票為(1, 0),Server2的投票為(2, 0),然後各自將這個投票發給叢集中其他機器。
(2) 接受來自各個伺服器的投票。叢集的每個伺服器收到投票後,首先判斷該投票的有效性,如檢查是否是本輪投票、是否來自LOOKING狀態的伺服器。
(3) 處理投票。針對每一個投票,伺服器都需要將別人的投票和自己的投票進行PK,PK規則如下
· 優先檢查ZXID。ZXID比較大的伺服器優先作為Leader。
· 如果ZXID相同,那麼就比較myid。myid較大的伺服器作為Leader伺服器。
對於Server1而言,它的投票是(1, 0),接收Server2的投票為(2, 0),首先會比較兩者的ZXID,均為0,再比較myid,此時Server2的myid最大,於是更新自己的投票為(2, 0),然後重新投票,對於Server2而言,其無須更新自己的投票,只是再次向叢集中所有機器發出上一次投票資訊即可。
(4) 統計投票。每次投票後,伺服器都會統計投票資訊,判斷是否已經有過半機器接受到相同的投票資訊,對於Server1、Server2而言,都統計出叢集中已經有兩臺機器接受了(2, 0)的投票資訊,此時便認為已經選出了Leader。
(5) 改變伺服器狀態。一旦確定了Leader,每個伺服器就會更新自己的狀態,如果是Follower,那麼就變更為FOLLOWING,如果是Leader,就變更為LEADING。
2. 伺服器執行時期的Leader選舉
在Zookeeper執行期間,Leader與非Leader伺服器各司其職,即便當有非Leader伺服器當機或新加入,此時也不會影響Leader,但是一旦Leader伺服器掛了,那麼整個叢集將暫停對外服務,進入新一輪Leader選舉,其過程和啟動時期的Leader選舉過程基本一致。假設正在執行的有Server1、Server2、Server3三臺伺服器,當前Leader是Server2,若某一時刻Leader掛了,此時便開始Leader選舉。選舉過程如下
(1) 變更狀態。Leader掛後,餘下的非Observer伺服器都會講自己的伺服器狀態變更為LOOKING,然後開始進入Leader選舉過程。
(2) 每個Server會發出一個投票。在執行期間,每個伺服器上的ZXID可能不同,此時假定Server1的ZXID為123,Server3的ZXID為122;在第一輪投票中,Server1和Server3都會投自己,產生投票(1, 123),(3, 122),然後各自將投票傳送給叢集中所有機器。
(3) 接收來自各個伺服器的投票。與啟動時過程相同。
(4) 處理投票。與啟動時過程相同,此時,Server1將會成為Leader。
(5) 統計投票。與啟動時過程相同。
(6) 改變伺服器的狀態。與啟動時過程相同。
2.2 Leader選舉演算法分析
在3.4.0後的Zookeeper的版本只保留了TCP版本的FastLeaderElection選舉演算法。當一臺機器進入Leader選舉時,當前叢集可能會處於以下兩種狀態
· 叢集中已經存在Leader。
· 叢集中不存在Leader。
對於叢集中已經存在Leader而言,此種情況一般都是某臺機器啟動得較晚,在其啟動之前,叢集已經在正常工作,對這種情況,該機器試圖去選舉Leader時,會被告知當前伺服器的Leader資訊,對於該機器而言,僅僅需要和Leader機器建立起連線,並進行狀態同步即可。而在叢集中不存在Leader情況下則會相對複雜,其步驟如下
(1) 第一次投票。無論哪種導致進行Leader選舉,叢集的所有機器都處於試圖選舉出一個Leader的狀態,即LOOKING狀態,LOOKING機器會向所有其他機器傳送訊息,該訊息稱為投票。投票中包含了SID(伺服器的唯一標識)和ZXID(事務ID),(SID, ZXID)形式來標識一次投票資訊。假定Zookeeper由5臺機器組成,SID分別為1、2、3、4、5,ZXID分別為9、9、9、8、8,並且此時SID為2的機器是Leader機器,某一時刻,1、2所在機器出現故障,因此叢集開始進行Leader選舉。在第一次投票時,每臺機器都會將自己作為投票物件,於是SID為3、4、5的機器投票情況分別為(3, 9),(4, 8), (5, 8)。
(2) 變更投票。每臺機器發出投票後,也會收到其他機器的投票,每臺機器會根據一定規則來處理收到的其他機器的投票,並以此來決定是否需要變更自己的投票,這個規則也是整個Leader選舉演算法的核心所在,其中術語描述如下
· vote_sid:接收到的投票中所推舉Leader伺服器的SID。
· vote_zxid:接收到的投票中所推舉Leader伺服器的ZXID。
· self_sid:當前伺服器自己的SID。
· self_zxid:當前伺服器自己的ZXID。
每次對收到的投票的處理,都是對(vote_sid, vote_zxid)和(self_sid, self_zxid)對比的過程。
規則一:如果vote_zxid大於self_zxid,就認可當前收到的投票,並再次將該投票傳送出去。
規則二:如果vote_zxid小於self_zxid,那麼堅持自己的投票,不做任何變更。
規則三:如果vote_zxid等於self_zxid,那麼就對比兩者的SID,如果vote_sid大於self_sid,那麼就認可當前收到的投票,並再次將該投票傳送出去。
規則四:如果vote_zxid等於self_zxid,並且vote_sid小於self_sid,那麼堅持自己的投票,不做任何變更。
結合上面規則,給出下面的叢集變更過程。

(3) 確定Leader。經過第二輪投票後,叢集中的每臺機器都會再次接收到其他機器的投票,然後開始統計投票,如果一臺機器收到了超過半數的相同投票,那麼這個投票對應的SID機器即為Leader。此時Server3將成為Leader。
由上面規則可知,通常那臺伺服器上的資料越新(ZXID會越大),其成為Leader的可能性越大,也就越能夠保證資料的恢復。如果ZXID相同,則SID越大機會越大。
2.3 Leader選舉實現細節
1. 伺服器狀態
伺服器具有四種狀態,分別是LOOKING、FOLLOWING、LEADING、OBSERVING。
LOOKING:尋找Leader狀態。當伺服器處於該狀態時,它會認為當前叢集中沒有Leader,因此需要進入Leader選舉狀態。
FOLLOWING:跟隨者狀態。表明當前伺服器角色是Follower。
LEADING:領導者狀態。表明當前伺服器角色是Leader。
OBSERVING:觀察者狀態。表明當前伺服器角色是Observer。
2. 投票資料結構
每個投票中包含了兩個最基本的資訊,所推舉伺服器的SID和ZXID,投票(Vote)在Zookeeper中包含欄位如下
id:被推舉的Leader的SID。
zxid:被推舉的Leader事務ID。
electionEpoch:邏輯時鐘,用來判斷多個投票是否在同一輪選舉週期中,該值在服務端是一個自增序列,每次進入新一輪的投票後,都會對該值進行加1操作。
peerEpoch:被推舉的Leader的epoch。
state:當前伺服器的狀態。
3. QuorumCnxManager:網路I/O
每臺伺服器在啟動的過程中,會啟動一個QuorumPeerManager,負責各臺伺服器之間的底層Leader選舉過程中的網路通訊。
(1) 訊息佇列。QuorumCnxManager內部維護了一系列的佇列,用來儲存接收到的、待傳送的訊息以及訊息的傳送器,除接收佇列以外,其他佇列都按照SID分組形成佇列集合,如一個叢集中除了自身還有3臺機器,那麼就會為這3臺機器分別建立一個傳送佇列,互不干擾。
· recvQueue:訊息接收佇列,用於存放那些從其他伺服器接收到的訊息。
· queueSendMap:訊息傳送佇列,用於儲存那些待傳送的訊息,按照SID進行分組。
· senderWorkerMap:傳送器集合,每個SenderWorker訊息傳送器,都對應一臺遠端Zookeeper伺服器,負責訊息的傳送,也按照SID進行分組。
· lastMessageSent:最近傳送過的訊息,為每個SID保留最近傳送過的一個訊息。
(2) 建立連線。為了能夠相互投票,Zookeeper叢集中的所有機器都需要兩兩建立起網路連線。QuorumCnxManager在啟動時會建立一個ServerSocket來監聽Leader選舉的通訊埠(預設為3888)。開啟監聽後,Zookeeper能夠不斷地接收到來自其他伺服器的建立連線請求,在接收到其他伺服器的TCP連線請求時,會進行處理。為了避免兩臺機器之間重複地建立TCP連線,Zookeeper只允許SID大的伺服器主動和其他機器建立連線,否則斷開連線。在接收到建立連線請求後,伺服器通過對比自己和遠端伺服器的SID值來判斷是否接收連線請求,如果當前伺服器發現自己的SID更大,那麼會斷開當前連線,然後自己主動和遠端伺服器建立連線。一旦連線建立,就會根據遠端伺服器的SID來建立相應的訊息傳送器SendWorker和訊息接收器RecvWorker,並啟動。
(3) 訊息接收與傳送。訊息接收:由訊息接收器RecvWorker負責,由於Zookeeper為每個遠端伺服器都分配一個單獨的RecvWorker,因此,每個RecvWorker只需要不斷地從這個TCP連線中讀取訊息,並將其儲存到recvQueue佇列中。訊息傳送:由於Zookeeper為每個遠端伺服器都分配一個單獨的SendWorker,因此,每個SendWorker只需要不斷地從對應的訊息傳送佇列中獲取出一個訊息傳送即可,同時將這個訊息放入lastMessageSent中。在SendWorker中,一旦Zookeeper發現針對當前伺服器的訊息傳送佇列為空,那麼此時需要從lastMessageSent中取出一個最近傳送過的訊息來進行再次傳送,這是為了解決接收方在訊息接收前或者接收到訊息後伺服器掛了,導致訊息尚未被正確處理。同時,Zookeeper能夠保證接收方在處理訊息時,會對重複訊息進行正確的處理。
4. FastLeaderElection:選舉演算法核心
· 外部投票:特指其他伺服器發來的投票。
· 內部投票:伺服器自身當前的投票。
· 選舉輪次:Zookeeper伺服器Leader選舉的輪次,即logicalclock。
· PK:對內部投票和外部投票進行對比來確定是否需要變更內部投票。
(1) 選票管理
· sendqueue:選票傳送佇列,用於儲存待傳送的選票。
· recvqueue:選票接收佇列,用於儲存接收到的外部投票。
· WorkerReceiver:選票接收器。其會不斷地從QuorumCnxManager中獲取其他伺服器發來的選舉訊息,並將其轉換成一個選票,然後儲存到recvqueue中,在選票接收過程中,如果發現該外部選票的選舉輪次小於當前伺服器的,那麼忽略該外部投票,同時立即傳送自己的內部投票。
· WorkerSender:選票傳送器,不斷地從sendqueue中獲取待傳送的選票,並將其傳遞到底層QuorumCnxManager中。
(2) 演算法核心
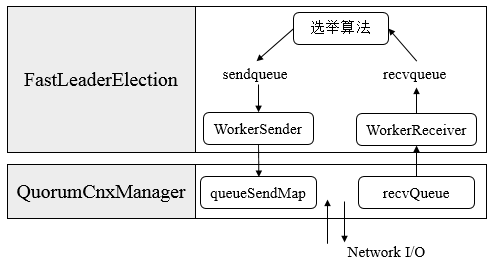
上圖展示了FastLeaderElection模組是如何與底層網路I/O進行互動的。Leader選舉的基本流程如下
1. 自增選舉輪次。Zookeeper規定所有有效的投票都必須在同一輪次中,在開始新一輪投票時,會首先對logicalclock進行自增操作。
2. 初始化選票。在開始進行新一輪投票之前,每個伺服器都會初始化自身的選票,並且在初始化階段,每臺伺服器都會將自己推舉為Leader。
3. 傳送初始化選票。完成選票的初始化後,伺服器就會發起第一次投票。Zookeeper會將剛剛初始化好的選票放入sendqueue中,由傳送器WorkerSender負責傳送出去。
4. 接收外部投票。每臺伺服器會不斷地從recvqueue佇列中獲取外部選票。如果伺服器發現無法獲取到任何外部投票,那麼就會立即確認自己是否和叢集中其他伺服器保持著有效的連線,如果沒有連線,則馬上建立連線,如果已經建立了連線,則再次傳送自己當前的內部投票。
5. 判斷選舉輪次。在傳送完初始化選票之後,接著開始處理外部投票。在處理外部投票時,會根據選舉輪次來進行不同的處理。
· 外部投票的選舉輪次大於內部投票。若伺服器自身的選舉輪次落後於該外部投票對應伺服器的選舉輪次,那麼就會立即更新自己的選舉輪次(logicalclock),並且清空所有已經收到的投票,然後使用初始化的投票來進行PK以確定是否變更內部投票。最終再將內部投票傳送出去。
· 外部投票的選舉輪次小於內部投票。若伺服器接收的外選票的選舉輪次落後於自身的選舉輪次,那麼Zookeeper就會直接忽略該外部投票,不做任何處理,並返回步驟4。
· 外部投票的選舉輪次等於內部投票。此時可以開始進行選票PK。
6. 選票PK。在進行選票PK時,符合任意一個條件就需要變更投票。
· 若外部投票中推舉的Leader伺服器的選舉輪次大於內部投票,那麼需要變更投票。
· 若選舉輪次一致,那麼就對比兩者的ZXID,若外部投票的ZXID大,那麼需要變更投票。
· 若兩者的ZXID一致,那麼就對比兩者的SID,若外部投票的SID大,那麼就需要變更投票。
7. 變更投票。經過PK後,若確定了外部投票優於內部投票,那麼就變更投票,即使用外部投票的選票資訊來覆蓋內部投票,變更完成後,再次將這個變更後的內部投票傳送出去。
8. 選票歸檔。無論是否變更了投票,都會將剛剛收到的那份外部投票放入選票集合recvset中進行歸檔。recvset用於記錄當前伺服器在本輪次的Leader選舉中收到的所有外部投票(按照服務隊的SID區別,如{(1, vote1), (2, vote2)...})。
9. 統計投票。完成選票歸檔後,就可以開始統計投票,統計投票是為了統計叢集中是否已經有過半的伺服器認可了當前的內部投票,如果確定已經有過半伺服器認可了該投票,則終止投票。否則返回步驟4。
10. 更新伺服器狀態。若已經確定可以終止投票,那麼就開始更新伺服器狀態,伺服器首選判斷當前被過半伺服器認可的投票所對應的Leader伺服器是否是自己,若是自己,則將自己的伺服器狀態更新為LEADING,若不是,則根據具體情況來確定自己是FOLLOWING或是OBSERVING。
以上10個步驟就是FastLeaderElection的核心,其中步驟4-9會經過幾輪迴圈,直到有Leader選舉產生。
三、總結
經過本篇博文的學習,瞭解了Leader選舉的具體細節,這對於之後的程式碼分析會打下很好的基礎。也謝謝各位園友的觀看~