【演算法】2 由股票收益問題再看分治演算法和遞迴式
回顧分治演算法
分治演算法的英文名叫做“divide and conquer”,它的意思是將一塊領土分解為若干塊小部分,然後一塊塊的佔領征服,讓它們彼此異化。這就是英國人的軍事策略,但我們今天要看的是演算法。
如前所述,分治演算法有3步,在上一篇中已有介紹,它們對應的英文名分別是:divide、conquer、combine。
接下來我們通過多個小演算法來深化對分治演算法的理解。
二分查詢演算法
問題描述:在已排序的陣列A中查詢是否存在數字n。
1)分:取得陣列A中的中間數,並將其與n比較
2)治:假設陣列為遞增陣列,若n比中間數小,則在陣列左半部分繼續遞迴查詢執行“分”步驟
3)組合:由於在陣列A中找到n後便直接返回了,因此這一步就無足輕重了
平方演算法
問題描述:計算x的n次方
我們有原始演算法:用x乘以x,再乘以x,再乘以x,一直有n個x相乘
這樣一來演算法的複雜度就是
分治演算法:我們可以將n一分為二,於是,
當n為奇數時,
當x為偶數時,
此時的複雜度就變成了
斐波那契數
斐波那契數的定義如下:
當然,可以直接用遞迴來求解,但是這樣一來花費的時間就是指數級的
然後我們可以更進一步讓其為多項式時間。
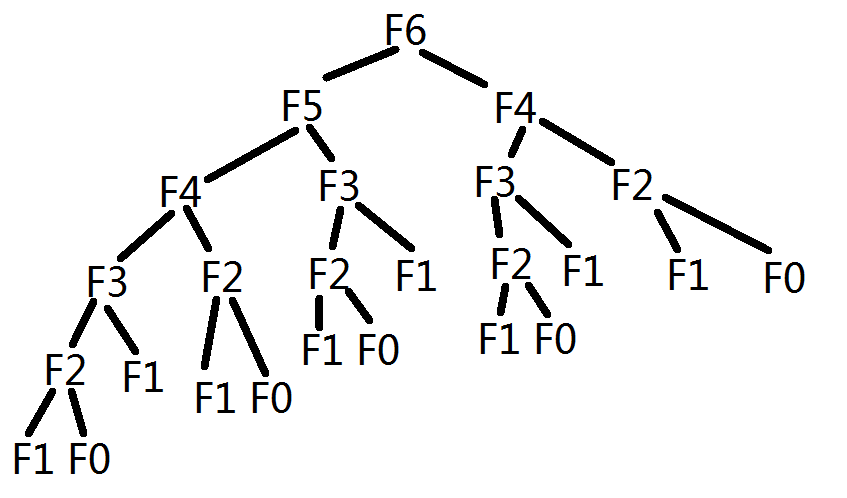
上面這幅圖雖然比較簡略,在求n為6時的斐波那契數,我們卻求解了3次F3,F1和F0的求解次數則更多了,我們完全可以讓其只求解一次。
對此,還有一個計算公式:
其中
然後這個公式只存在與理論中,在當今計算機中仍舊無法計算,因為我們只能使用浮點型,而浮點型都有一定的精度,最後計算的時候鐵定了會丟失一些精度的。
下面再介紹一種平方遞迴演算法:

一時忘了矩陣怎麼計算乘機,感謝@fireworkpark 相助。
最大子陣列問題
最近有一個比較火的話題,股票,那麼這一篇就由此引入來進一步學習分治演算法。在上一篇部落格中已經對插入排序和歸併排序做了初步的介紹,大家可以看看:【演算法基礎】由插入排序看如何分析和設計演算法
當然了,這篇部落格主要用來介紹演算法而非講解股票,所以這裡已經有了股票的價格,如下所示。
| 天 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 股票價格 | 50 | 57 | 65 | 75 | 67 | 60 | 54 | 51 | 48 | 44 | 47 | 43 | 56 | 64 | 71 | 65 | 61 | 73 | 70 |
| 價格波動 | 0 | 7 | 8 | 18 | -8 | -7 | -6 | -3 | -3 | -4 | 3 | -4 | 13 | 10 | 7 | -6 | -4 | 12 | -3 |
價格表已經有了問題是從哪一天買進、哪一天賣出會使得收益最高呢?你可以認為在價格最低的時候買入,在價格最高的時候賣出,這是對的,但不一定任何時候都適用。在這裡的價格表中,股票價格最高的時候是第3天、價格最低的時候是第11天,怎麼辦?讓時間反向行駛?
就像我以前參加學校裡的程式設計競賽時一樣,也可以用多個for迴圈不斷的進行比較。這裡就是將每對可能的買進和賣出日期進行組合,只要賣出日期在買進日期之前就好,這樣在18天中就有
然後,我們在學習演算法,自然要以演算法的角度來看這個問題。比起股票價格,我們更應該關注價格波動。如果將這個波動定義為陣列A,那麼問題就轉換為尋找A的和最大的非空連續子陣列。這種連續子陣列就是標題中的最大子陣列(maximum subarray)。將原表簡化如下:
| 陣列 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 7 | 8 | 18 | -8 | -7 | -6 | -3 | -3 | -4 | 3 | -4 | 13 | 10 | 7 | -6 | -4 | 12 | -3 |
在這個演算法中,常常被說成是“一個最大子陣列”而不是“最大子陣列”,因為可能有多個子陣列達到最大和。
只有當陣列中包含負數時,最大子陣列問題才有意義。如果所有陣列元素都是非負的,最大子陣列問題沒有任何難度,因為整個陣列的和肯定是最大的。
使用分治思想解決問題
我們將實際問題轉換為演算法問題,在這裡也就是要尋找子陣列
1)完全位於子陣列
2)完全位於子陣列
3)跨越中點
FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)
1 left-sum = -10000
2 sum = 0
3 for i = mid downto low
4 sum = sum + A[i]
5 if sum > left-sum
6 left-sum = sum
7 max-left = i
8 right-sum = -10000
9 sum = 0
10 for j = mid + 1 to high
11 sum = sum + A[i]
12 if sum > right-sum
13 right-sum = sum
14 max-right = j
15 return (max-left, max-right, left-sum + right-sum)下面是以上程式的一個簡易程式。
#include <iostream>
#include <cstdio>
using namespace std;
int const n=18;
int A[n]={7,8,18,-8,-7,-6,-3,-3,-4,3,-4,13,10,7,-6,-4,12,-3};
int B[3];
int low,high,mid;
int max_left,max_right;
int sum;
void find_max_crossing_subarray(int A[],int low,int mid,int high);
int main()
{
find_max_crossing_subarray(A,0,7,15);
for(int i=0;i<3;i++)
{
printf("%d ",B[i]);
}
return 0;
}
void find_max_crossing_subarray(int A[],int low,int mid,int high)
{
int left_sum=-10000;
sum=0;
for(int i=mid;i>=low;i--)
{
sum=sum+A[i];
if(sum>left_sum)
{
left_sum=sum;
max_left=i;
}
}
int right_sum=-10000;
sum=0;
for(int j=mid+1;j<=high;j++)
{
sum=sum+A[j];
if(sum>right_sum)
{
right_sum=sum;
max_right=j;
}
}
B[0]=max_left;
B[1]=max_right;
B[2]=left_sum+right_sum;
}
如果子陣列
可以看出上面的演算法所花費的時間是線性的,這樣我們就可以來求解最大子陣列問題的分治演算法的虛擬碼咯:
FIND-MAXIMUM-SUBARRAY(A,low,high)
1 if high==low
2 return (low,high,A[low])
4 (left-low,left-high,left-sum)=FIND-MAXIMUM-SUBARRAY(A,low,mid)
5 (right-low,right-high,right-sum)=FIND-MAXIMUM-SUBARRAY(A,mid+1,high)
6 (cross-low,cross-high,cross-sum)=FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)
7 if left-sum>=right-sum and left-sum>=cross-sum)
return (left-low,left-high,left-sum)
8 else if(right-sum>=left-sum and right-sum>=cross-sum)
return (right-low,right-high,right-sum)
9 else return (cross-low,cross-high,cross-sum)只要初始呼叫FIND-MAXIMUM-SUBARRAY(A,1,A.length)就可以求出
分析分治演算法和漸近記號中的省略問題
下面我們又來使用遞迴式來求解前面的遞迴過程FIND-MAXIMUM-SUBARRAY的執行時間了,就像上一篇分析歸併排序那樣,對問題進行簡化,假設原問題的規模為2的冪,這樣所有子陣列的規模均為整數。
第1行花費常量時間。當n=1時,直接在第二行return後跳出函式,因此
當n>1時,為遞迴情況。第1行和第3行都花費常量時間,第4行和第5行求解的子問題均為n/2個元素的子陣列,因此每個子問題的求解總執行時間增加了2T(n/2)。第6行呼叫FIND-MAX-CROSSING-SUBARRAY花費
在上面的步驟中,將
回顧前面n=1的情況,第一行花費了常量時間,第二行同樣也花費了常量時間,但這兩步花費的總時間卻是
但是為什麼第4行和第5行中卻是
如果省略了這個因子2會發生什麼呢?不要以為就是一個2這麼小的數而已哦,後果可嚴重了,看下圖……左側是一棵4層的樹,右側就是因子為1的樹(它已經是線性結構了)。
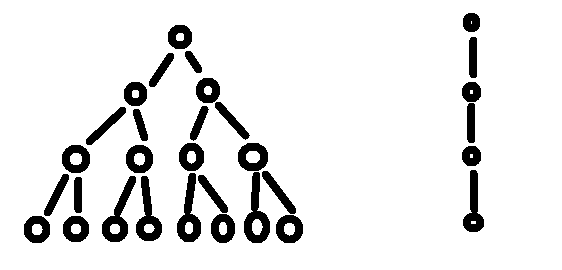
總結來說,漸近記號都包含了常量因子,但遞迴符號卻不包含它們。
藉助遞迴樹求解遞迴式
前面我們已經看到了遞迴式,也看到了遞迴樹,那麼如何藉助遞迴樹來求解遞迴式呢?接下來就來看看吧。
在遞迴樹中,每個結點都表示一個單一問題的代價,子問題對應某次遞迴函式呼叫。
通過對樹中每層的代價進行求和,就可以得到每層的代價;然後將所有層的代價求和,就可以得要到所有層次的遞迴呼叫的總代價。
我們通常用遞迴樹來得出一個較好的猜測結果,然後用代入法來證明猜測是否正確。但是通過遞迴樹來得到結果時,不可避免的要忍受一些”不精確“,得在稍後才能驗證猜測是否正確。
因為下面的示例圖太難用鍵盤敲出來了,我就用了手寫,希望大家不介意。
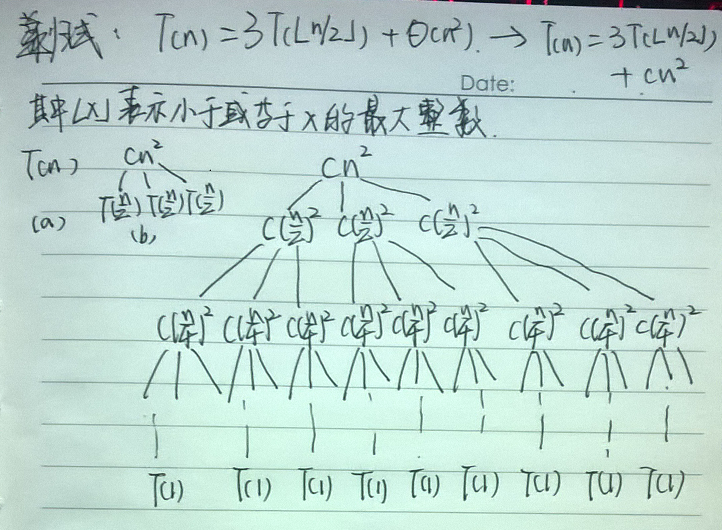
如下所示,有一個遞迴式,我們要藉助它的遞迴樹來求解最終的結果。前面所說的忍受“不精確”這裡就有2點:
1)我們要關注的更應該是解的上界,因為我們知道舍入對求解遞迴式沒有影響,因此可以將
2)我們還將
圖a所示的是
這棵樹有多高(深)呢?
我們發現對於深度為
有了深度還需要計算每一層的代價。其中每層的結點數都是上一層的3倍,因此深度為
因此對於
遞迴樹的最底層深度為
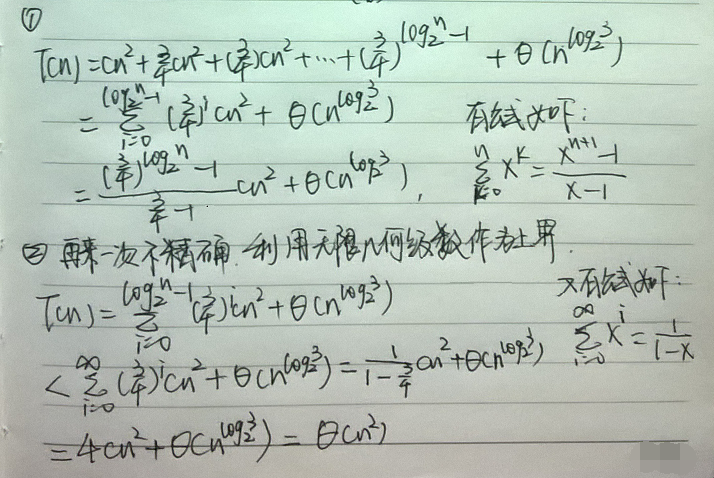
至於這最後的

不知道大家看不看得清,上面的兩行文字是“我們要證的是
寫一篇部落格本來不會這麼漫長的,可是這是演算法,結果就不一樣了……
感謝您的訪問,希望對您有所幫助。 歡迎大家關注、收藏以及評論。
為使本文得到斧正和提問,轉載請註明出處:
http://blog.csdn.net/nomasp
相關文章
- 遞迴 & 分治演算法深度理解遞迴演算法
- 遞迴與分治演算法練習遞迴演算法
- 揹包問題的遞迴與非遞迴演算法遞迴演算法
- 遞迴演算法程式設計整數因子分解問題的遞迴演算法遞迴演算法程式設計
- 資料結構和演算法——遞迴-八皇后問題(回溯演算法)資料結構演算法遞迴
- 分治演算法-眾數問題演算法
- 【演算法】遞迴演算法演算法遞迴
- 遞迴演算法遞迴演算法
- c++迷宮問題回溯法遞迴演算法C++遞迴演算法
- 計算機演算法設計與分析——遞迴與分治策略(一)計算機演算法遞迴
- 演算法設計--眾數和重數問題(分治法)演算法
- 演算法初探--遞迴演算法演算法遞迴
- 遞迴演算法轉換為非遞迴演算法的技巧遞迴演算法
- 資料結構和演算法面試題系列—遞迴演算法總結資料結構演算法面試題遞迴
- 分治演算法-求解棋盤覆蓋問題演算法
- 計算機演算法設計與分析筆記(二)——遞迴與分治計算機演算法筆記遞迴
- Java遞迴演算法Java遞迴演算法
- 遞迴演算法要素遞迴演算法
- 資料結構和演算法:遞迴資料結構演算法遞迴
- 演算法小專欄:遞迴與尾遞迴演算法遞迴
- 淺談遞迴演算法遞迴演算法
- JavaScript演算法之遞迴JavaScript演算法遞迴
- 每日一演算法:遞迴演算法遞迴
- 每天刷個演算法題20160524:阿克曼函式的遞迴轉非遞迴解法演算法函式遞迴
- 【演算法】3 由招聘問題看隨機演算法演算法隨機
- 分治演算法演算法
- 一個vuepress配置問題,引發的js遞迴演算法思考VueJS遞迴演算法
- 快速排序(遞迴及非遞迴演算法原始碼)排序遞迴演算法原始碼
- 馬踏棋盤演算法(騎士周遊問題)----遞迴與貪心優化演算法演算法遞迴優化
- Java遞迴演算法的使用Java遞迴演算法
- 演算法分析__遞迴跟蹤演算法遞迴
- 演算法學習-遞迴排序演算法遞迴排序
- 漢諾塔非遞迴演算法遞迴演算法
- 什麼是遞迴演算法遞迴演算法
- 30、java中遞迴演算法Java遞迴演算法
- 歸併排序(C++_分治遞迴)排序C++遞迴
- 原:八皇后問題的遞迴和非遞迴Java實現遞迴Java
- 演算法基礎--遞迴和動態規劃演算法遞迴動態規劃