學習GBDT+LR
最近看了facebook的Practical Lessons from Predicting Clicks on Ads at Facebook的這篇文章
下面簡單的介紹一下該演算法:
1.GBDT+LR 模型
首先,該模型不算是新的模型了,在一些大公司的ctr的模型中已經使用了。
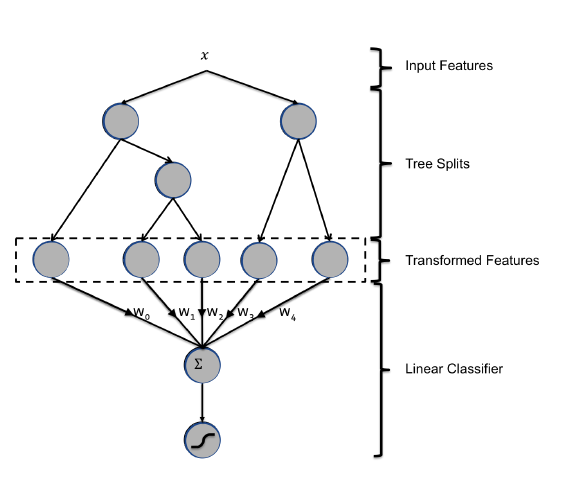
如圖就是該論文中提出的組合模型GBDT+LR,可以將GBDT看做是對特徵一種組合編碼的過程,最後的LR才是最終的分類(迴歸)模型。
1)資料的灌入,一般特徵會有連續的和離散的,樹模型還是更適合處理一下連續的特徵(網上可以查詢)。
方案一:
將連續的資料和離散的資料分開輸入到GBDT中,最終使用的葉子進行編碼,然後約定離散值和連續值的位置。
這過程中可以考慮只對連續值使用GBDT進行編碼,而離散的特徵就使用原本的onehot編碼,最終拼接起來。完成特徵的編碼
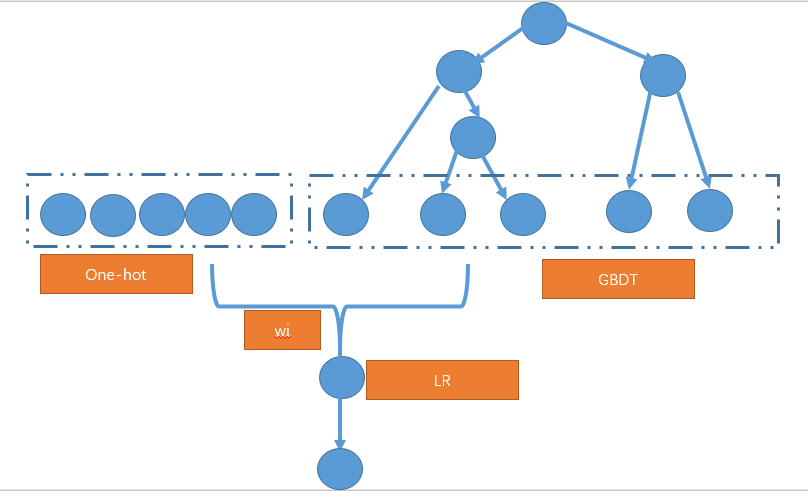
方案二:
可以對離散的特徵也進行GBDT編碼,之後組合起來(參考GBDT+FFM這個裡面改進),對離散型的資料新進行統計,
對於出現頻次高的特徵進行保留,過濾掉稀疏的少的特徵值,這樣就可以使用GBDT學習編碼。
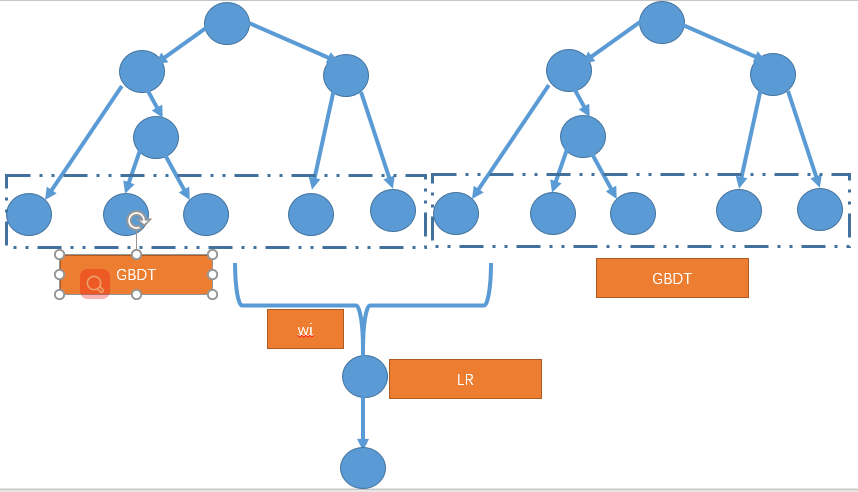
GBDT+FFM中就是這樣處理的,但是那些離散的非異常值,其實仍可以使用onehot的形式進行編碼,在最後一層中使用。
使用GBDT的組合作用,但是樹形的組合是重複的,其一個特徵可以在樹的不同層中出現參與構造組合,這個要比FM
和FFM的組合要更深一些。
其編碼的結果含有上下文的一些屬性。在進行資料的輸入,不是固定的,可以使用不同的輸入方式,上面只是列舉了兩種比較
常見的方法,使用樹形來進行編碼。
2. NE(Normalized Entropy)歸一化熵
使用NE(歸一化熵)進行評估,
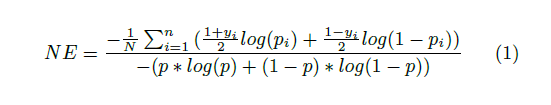
其中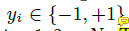
上新增了訓練樣本的影響,(在計算時應該注意y的範圍是-1 和1 )
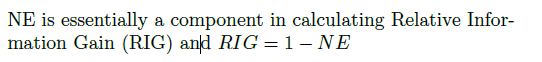
可以作為一種評價指標來使用,但是後來的論文中很少見有使用這種NE的。具體可以根據場景進行選使用。
3.Data freshness
使用新資料對模型進行更新,在實際的使用當中資料的分佈是動態的,不是不變的,使用新資料來更新模型可以獲得不錯的
收益,文中指出GBDT樹模型是每天更新,LR模型是實時更新的。以此來保持模型的準度。歷史資料特徵(統計型特徵)對於
資料新鮮的變化不敏感,但是上下文特徵就比較明顯。這一點在很多機器學習模型中都會有實時或者近實時的更新模型,保證模型的能力。
4.Calibrate
這個校準不是所有都需要,一般我們在訓練模型時,都會對樣本進行取樣,或是負取樣等,這樣會改變原來樣本的資料分佈,對於資料預測時的影響是很微弱的,但是對於像LR這種我們在得到預測的資料之後可能使用這個資料參與新的計算,就會出現偏差。為了解決這個偏差,就需要對模型的輸出進行Calibrate(校準)。
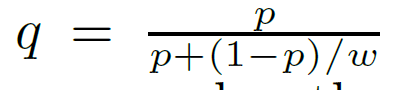
其中p是模型預測出的正例的概率值,w是取樣的比例w(是原始樣本中正負的比例)一般是小數,來將模型的輸出值校準到一個正常的資料。
小結:
GDBT+LR算是經典的CTR與預估模型,其使用了GBDT的非線性進行組合特徵的學習,使用LR來學習特徵的關聯,最終預測出點選率。目前LR也仍是主流,只是輸入的特徵組合是使用其他的一些方式產出的,如FM,FFM,GBDT,DNN等。因此如何將原始的資料與這些模型結合得到最大的效果,仍需不斷的去嘗試,根據不同的場景去調節。
相關文章
- GBDT+LR原理和實戰
- 【推薦系統】GBDT+LR
- 學習學習再學習
- 推薦系統 Task05:GBDT+LR(知識腦圖整理)
- 深度學習——學習目錄——學習中……深度學習
- 深度學習(一)深度學習學習資料深度學習
- 深度學習學習框架深度學習框架
- 強化學習-學習筆記3 | 策略學習強化學習筆記
- 學習產品快報09 | “CSDN學習”:增加學習提醒,提示學習不忘記
- 【強化學習】強化學習/增強學習/再勵學習介紹強化學習
- 學習ThinkPHP,學習OneThinkPHP
- 前端學習之Bootstrap學習前端boot
- 學而習之,成就學習
- 前端週刊第62期:學習學習再學習前端
- 深度學習+深度強化學習+遷移學習【研修】深度學習強化學習遷移學習
- 強化學習-學習筆記2 | 價值學習強化學習筆記
- Golang 學習——interface 介面學習(一)Golang
- Golang 學習——interface 介面學習(二)Golang
- 深度學習學習7步驟深度學習
- 《JAVA學習指南》學習筆記Java筆記
- Go學習【二】學習資料Go
- java學習之道 --- 如何學習java?Java
- 免殺學習-基礎學習
- 強化學習10——迭代學習強化學習
- 程式設計學習MarkDown學習程式設計
- this學習
- 學習
- 【區塊鏈學習】《區塊鏈學習指南》學習筆記區塊鏈筆記
- Flutter學習記錄(一)Dart學習FlutterDart
- 從學習語文聊聊如何學習
- kitten 學習教程(一) 學習筆記筆記
- 整合學習(一):簡述整合學習
- 學習態度和學習計劃
- 學習筆記----圖論學習中筆記圖論
- 酷學習:學習可以很酷很好玩
- 強化學習-學習筆記13 | 多智慧體強化學習強化學習筆記智慧體
- 學習程式設計 vs 學習電腦科學程式設計
- 駁 《駁 《駁 《駁 《停止學習框架》》》》、《駁 《駁 《停止學習框架》》》、《駁 《停止學習框架》》、《停止學習框架》框架