圖形影象處理-之-高質量的快速的影象縮放 中篇 二次線性插值和三次卷積插值
轉自:http://blog.csdn.net/housisong/article/details/1452249
圖形影象處理-之-高質量的快速的影象縮放 中篇 二次線性插值和三次卷積插值
HouSisong@GMail.com 2006255.12.13
(2009.03.07 可以到這裡下載縮放演算法的完整的可以編譯的專案原始碼: http://blog.csdn.net/housisong/archive/2009/03/07/3967270.aspx )
(2007.11.12 替換了二次線性插值的實現(以前偷懶使用了一個近似公式),改進後在圖片邊緣的插值效果更好(包括三次卷積插值的邊界也更精確);
(2007.09.14 修正三次卷積的MMX版本中表的精度太低(7bit),造成卷積結果誤差較大的問題,該版本提高了插值質量,並且速度加快12-25%)
(2007.09.07 PicZoom_ThreeOrder2和PicZoom_ThreeOrder_MMX在縮放的圖片寬或高
小於3個畫素的時候有一個Bug(邊界計算錯誤);將unsigned long xrIntFloat_16,
yrIntFloat_16的定義改成long xrIntFloat_16,yrIntFloat_16就可以了)
(2007.07.02 ThreeOrder2_Fast一點小的改進,加快14%)
(2007.06.18 優化PicZoom_BilInear_MMX的實現(由138.5fps提高到147.9fps),
並新增更快的兩路展開的實現版本BilInear_MMX_expand2函式;
補充新的SSE2的實現PicZoom_BilInear_SSE2函式)
(2007.06.06 更新測試資料,編譯器由vc6改為vc2005,CPU由賽揚2G改為AMD64x2 4200+(2.1G) )
(2007.03.06 更新)
tag:影象縮放,速度優化,定點數優化,近鄰取樣插值,二次線性插值,三次線性插值,
MipMap鏈,三次卷積插值,MMX,SSE,SSE2,CPU快取優化
摘要:首先給出一個基本的影象縮放演算法,然後一步一步的優化其速度和縮放質量;
高質量的快速的影象縮放 全文 分為:
上篇 近鄰取樣插值和其速度優化
中篇 二次線性插值和三次卷積插值
下篇 三次線性插值和MipMap鏈
補充 使用SSE2優化
正文:
為了便於討論,這裡只處理32bit的ARGB顏色;
程式碼使用C++;涉及到彙編優化的時候假定為x86平臺;使用的編譯器為vc2005;
為了程式碼的可讀性,沒有加入異常處理程式碼;
測試使用的CPU為AMD64x2 4200+(2.37G) 和 Intel Core2 4400(2.00G);
速度測試說明:
只測試記憶體資料到記憶體資料的縮放
測試圖片都是800*600縮放到1024*768; fps表示每秒鐘的幀數,值越大表示函式越快
A:近鄰取樣插值、二次線性插值、三次卷積插值 縮放效果對比



原圖 近鄰取樣縮放到0.6倍 近鄰取樣縮放到1.6倍


二次線性插值縮放到0.6倍 二次線性插值縮放到1.6倍


三次卷積插值縮放到0.6倍 三次卷積插值縮放到1.6倍





原圖 近鄰取樣縮放到8倍 二次線性插值縮放到8倍 三次卷積插值縮放到8倍 二次線性插值(近似公式)
近鄰取樣插值縮放簡單、速度快,但很多時候縮放出的圖片質量比較差(特別是對於人物、景色等),
圖片的縮放有比較明顯的鋸齒;使用二次或更高次插值有利於改善縮放效果;
B: 首先定義影象資料結構:
typedef unsigned char TUInt8; // [0..255]
struct TARGB32 //32 bit color
{
TUInt8 b,g,r,a; //a is alpha
};
struct TPicRegion //一塊顏色資料區的描述,便於引數傳遞
{
TARGB32* pdata; //顏色資料首地址
long byte_width; //一行資料的物理寬度(位元組寬度);
//abs(byte_width)有可能大於等於width*sizeof(TARGB32);
long width; //畫素寬度
long height; //畫素高度
};
//那麼訪問一個點的函式可以寫為:
inline TARGB32& Pixels(const TPicRegion& pic,const long x,const long y)
{
return ( (TARGB32*)((TUInt8*)pic.pdata+pic.byte_width*y) )[x];
}
二次線性插值縮放:
C: 二次線性插值縮放原理和公式圖示:
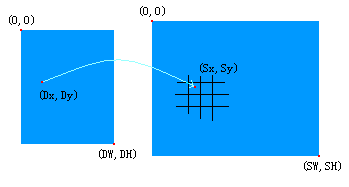
縮放後圖片 原圖片
(寬DW,高DH) (寬SW,高SH)
縮放對映原理:
(Sx-0)/(SW-0)=(Dx-0)/(DW-0) (Sy-0)/(SH-0)=(Dy-0)/(DH-0)
=> Sx=Dx*SW/DW Sy=Dy*SH/DH
聚焦看看(Sx,Sy)座標點(Sx,Sy為浮點數)附近的情況;
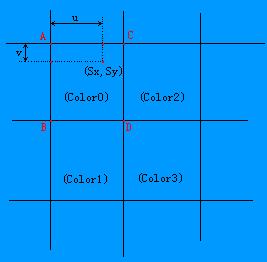
對於近鄰取樣插值的縮放演算法,直接取Color0顏色作為縮放後點的顏色;
二次線性插值需要考慮(Sx,Sy)座標點周圍的4個顏色值Color0/Color1/Color2/Color3,
把(Sx,Sy)到A/B/C/D座標點的距離作為係數來把4個顏色混合出縮放後點的顏色;
( u=Sx-floor(Sx); v=Sy-floor(Sy); 說明:floor函式的返回值為小於等於引數的最大整數 )
二次線性插值公式為:
tmpColor0=Color0*(1-u) + Color2*u;
tmpColor1=Color1*(1-u) + Color3*u;
DstColor =tmpColor0*(1-v) + tmpColor2*v;
展開公式為:
pm0=(1-u)*(1-v);
pm1=v*(1-u);
pm2=u*(1-v);
pm3=u*v;
則顏色混合公式為:
DstColor = Color0*pm0 + Color1*pm1 + Color2*pm2 + Color3*pm3;
引數函式圖示:
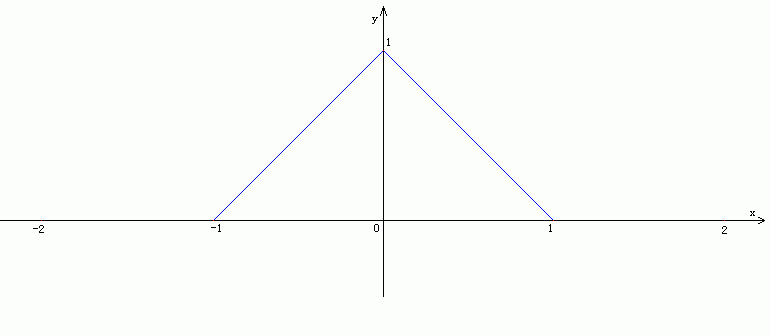
二次線性插值函式圖示
對於上面的公式,它將圖片向右下各移動了半個畫素,需要對此做一個修正;
=> Sx=(Dx+0.5)*SW/DW-0.5; Sy=(Dy+0.5)*SH/DH-0.5;
而實際的程式,還需要考慮到邊界(訪問源圖片可能超界)對於演算法的影響,邊界的處理可能有各種
方案(不處理邊界或邊界迴繞或邊界飽和或邊界對映或用背景顏色混合等;文章中預設使用邊界飽和來處理超界);
比如:邊界飽和函式:
inline TARGB32 Pixels_Bound(const TPicRegion& pic,long x,long y)
{
//assert((pic.width>0)&&(pic.height>0));
bool IsInPic=true;
if (x<0) {x=0; IsInPic=false; } else if (x>=pic.width ) {x=pic.width -1; IsInPic=false; }
if (y<0) {y=0; IsInPic=false; } else if (y>=pic.height) {y=pic.height-1; IsInPic=false; }
TARGB32 result=Pixels(pic,x,y);
if (!IsInPic) result.a=0;
return result;
}
D: 二次線性插值縮放演算法的一個參考實現:PicZoom_BilInear0
該函式並沒有做什麼優化,只是一個簡單的浮點實現版本;
{
long x=(long)fx; if (x>fx) --x; //x=floor(fx);
long y=(long)fy; if (y>fy) --y; //y=floor(fy);
TARGB32 Color0=Pixels_Bound(pic,x,y);
TARGB32 Color2=Pixels_Bound(pic,x+1,y);
TARGB32 Color1=Pixels_Bound(pic,x,y+1);
TARGB32 Color3=Pixels_Bound(pic,x+1,y+1);
float u=fx-x;
float v=fy-y;
float pm3=u*v;
float pm2=u*(1-v);
float pm1=v*(1-u);
float pm0=(1-u)*(1-v);
result->a=(pm0*Color0.a+pm1*Color1.a+pm2*Color2.a+pm3*Color3.a);
result->r=(pm0*Color0.r+pm1*Color1.r+pm2*Color2.r+pm3*Color3.r);
result->g=(pm0*Color0.g+pm1*Color1.g+pm2*Color2.g+pm3*Color3.g);
result->b=(pm0*Color0.b+pm1*Color1.b+pm2*Color2.b+pm3*Color3.b);
}
void PicZoom_Bilinear0(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
unsigned long dst_width=Dst.width;
TARGB32* pDstLine=Dst.pdata;
for (unsigned long y=0;y<Dst.height;++y)
{
float srcy=(y+0.4999999)*Src.height/Dst.height-0.5;
for (unsigned long x=0;x<dst_width;++x)
{
float srcx=(x+0.4999999)*Src.width/Dst.width-0.5;
Bilinear0(Src,srcx,srcy,&pDstLine[x]);
}
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_BilInear0 8.3 fps
////////////////////////////////////////////////////////////////////////////////
E: 把PicZoom_BilInear0的浮點計算改寫為定點數實現:PicZoom_BilInear1
{
long x=x_16>>16;
long y=y_16>>16;
TARGB32 Color0=Pixels_Bound(pic,x,y);
TARGB32 Color2=Pixels_Bound(pic,x+1,y);
TARGB32 Color1=Pixels_Bound(pic,x,y+1);
TARGB32 Color3=Pixels_Bound(pic,x+1,y+1);
unsigned long u_8=(x_16 & 0xFFFF)>>8;
unsigned long v_8=(y_16 & 0xFFFF)>>8;
unsigned long pm3_16=(u_8*v_8);
unsigned long pm2_16=(u_8*(unsigned long)(256-v_8));
unsigned long pm1_16=(v_8*(unsigned long)(256-u_8));
unsigned long pm0_16=((256-u_8)*(256-v_8));
result->a=((pm0_16*Color0.a+pm1_16*Color1.a+pm2_16*Color2.a+pm3_16*Color3.a)>>16);
result->r=((pm0_16*Color0.r+pm1_16*Color1.r+pm2_16*Color2.r+pm3_16*Color3.r)>>16);
result->g=((pm0_16*Color0.g+pm1_16*Color1.g+pm2_16*Color2.g+pm3_16*Color3.g)>>16);
result->b=((pm0_16*Color0.b+pm1_16*Color1.b+pm2_16*Color2.b+pm3_16*Color3.b)>>16);
}
void PicZoom_Bilinear1(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
long xrIntFloat_16=((Src.width)<<16)/Dst.width+1;
long yrIntFloat_16=((Src.height)<<16)/Dst.height+1;
const long csDErrorX=-(1<<15)+(xrIntFloat_16>>1);
const long csDErrorY=-(1<<15)+(yrIntFloat_16>>1);
unsigned long dst_width=Dst.width;
TARGB32* pDstLine=Dst.pdata;
long srcy_16=csDErrorY;
long y;
for (y=0;y<Dst.height;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear1(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_BilInear1 17.7 fps
////////////////////////////////////////////////////////////////////////////////
F: 二次線性插值需要考略邊界訪問超界的問題,我們可以將邊界區域和內部區域分開處理,這樣就可以優化內部的插值實現函式了:比如不需要判斷訪問超界、減少顏色資料複製、減少一些不必要的重複座標計算等等
{
unsigned long pm3_16=u_8*v_8;
unsigned long pm2_16=(u_8<<8)-pm3_16;
unsigned long pm1_16=(v_8<<8)-pm3_16;
unsigned long pm0_16=(1<<16)-pm1_16-pm2_16-pm3_16;
result->a=((pm0_16*PColor0[0].a+pm2_16*PColor0[1].a+pm1_16*PColor1[0].a+pm3_16*PColor1[1].a)>>16);
result->r=((pm0_16*PColor0[0].r+pm2_16*PColor0[1].r+pm1_16*PColor1[0].r+pm3_16*PColor1[1].r)>>16);
result->g=((pm0_16*PColor0[0].g+pm2_16*PColor0[1].g+pm1_16*PColor1[0].g+pm3_16*PColor1[1].g)>>16);
result->b=((pm0_16*PColor0[0].b+pm2_16*PColor0[1].b+pm1_16*PColor1[0].b+pm3_16*PColor1[1].b)>>16);
}
inline void Bilinear2_Border(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
long x=(x_16>>16);
long y=(y_16>>16);
unsigned long u_16=((unsigned short)(x_16));
unsigned long v_16=((unsigned short)(y_16));
TARGB32 pixel[4];
pixel[0]=Pixels_Bound(pic,x,y);
pixel[1]=Pixels_Bound(pic,x+1,y);
pixel[2]=Pixels_Bound(pic,x,y+1);
pixel[3]=Pixels_Bound(pic,x+1,y+1);
Bilinear2_Fast(&pixel[0],&pixel[2],u_16>>8,v_16>>8,result);
}
void PicZoom_Bilinear2(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
long xrIntFloat_16=((Src.width)<<16)/Dst.width+1;
long yrIntFloat_16=((Src.height)<<16)/Dst.height+1;
const long csDErrorX=-(1<<15)+(xrIntFloat_16>>1);
const long csDErrorY=-(1<<15)+(yrIntFloat_16>>1);
unsigned long dst_width=Dst.width;
//計算出需要特殊處理的邊界
long border_y0=-csDErrorY/yrIntFloat_16+1; //y0+y*yr>=0; y0=csDErrorY => y>=-csDErrorY/yr
if (border_y0>=Dst.height) border_y0=Dst.height;
long border_x0=-csDErrorX/xrIntFloat_16+1;
if (border_x0>=Dst.width ) border_x0=Dst.width;
long border_y1=(((Src.height-2)<<16)-csDErrorY)/yrIntFloat_16+1; //y0+y*yr<=(height-2) => y<=(height-2-csDErrorY)/yr
if (border_y1<border_y0) border_y1=border_y0;
long border_x1=(((Src.width-2)<<16)-csDErrorX)/xrIntFloat_16+1;
if (border_x1<border_x0) border_x1=border_x0;
TARGB32* pDstLine=Dst.pdata;
long Src_byte_width=Src.byte_width;
long srcy_16=csDErrorY;
long y;
for (y=0;y<border_y0;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear2_Border(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y0;y<border_y1;++y)
{
long srcx_16=csDErrorX;
long x;
for (x=0;x<border_x0;++x)
{
Bilinear2_Border(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
{
unsigned long v_8=(srcy_16 & 0xFFFF)>>8;
TARGB32* PSrcLineColor= (TARGB32*)((TUInt8*)(Src.pdata)+Src_byte_width*(srcy_16>>16)) ;
for (unsigned long x=border_x0;x<border_x1;++x)
{
TARGB32* PColor0=&PSrcLineColor[srcx_16>>16];
TARGB32* PColor1=(TARGB32*)((TUInt8*)(PColor0)+Src_byte_width);
Bilinear2_Fast(PColor0,PColor1,(srcx_16 & 0xFFFF)>>8,v_8,&pDstLine[x]);
srcx_16+=xrIntFloat_16;
}
}
for (x=border_x1;x<dst_width;++x)
{
Bilinear2_Border(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y1;y<Dst.height;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear2_Border(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_BilInear2 43.4 fps
////////////////////////////////////////////////////////////////////////////////
(F'補充:
如果不想處理邊界訪問超界問題,可以考慮擴大源圖片的尺寸,加一個邊框 (“哨兵”優化);
這樣插值演算法就不用考慮邊界問題了,程式寫起來也簡單很多!
如果對縮放結果的邊界畫素級精度要求不是太高,我還有一個方案,一個稍微改變的縮放公式:
Sx=Dx*(SW-1)/DW; Sy=Dy*(SH-1)/DH; (源圖片寬和高:SW>=2;SH>=2)
證明這個公式不會造成記憶體訪問超界:
要求Dx=DW-1時: sx+1=int( (dw-1)/dw*(dw-1) ) +1 <= (sw-1)
有: int( (sw-1)*(dw-1)/dw ) <=sw-2
(sw-1)*(dw-1)/dw <(sw-1)
(dw-1) /dw<1
(dw-1) <dw
比如,按這個公式的一個簡單實現: (縮放效果見前面的"二次線性插值(近似公式)"圖示)
{
if ( (0==Dst.width)||(0==Dst.height)
||(2>Src.width)||(2>Src.height)) return;
long xrIntFloat_16=((Src.width-1)<<16)/Dst.width;
long yrIntFloat_16=((Src.height-1)<<16)/Dst.height;
unsigned long dst_width=Dst.width;
long Src_byte_width=Src.byte_width;
TARGB32* pDstLine=Dst.pdata;
long srcy_16=0;
for (unsigned long y=0;y<Dst.height;++y)
{
unsigned long v_8=(srcy_16 & 0xFFFF)>>8;
TARGB32* PSrcLineColor= (TARGB32*)((TUInt8*)(Src.pdata)+Src_byte_width*(srcy_16>>16)) ;
long srcx_16=0;
for (unsigned long x=0;x<dst_width;++x)
{
TARGB32* PColor0=&PSrcLineColor[srcx_16>>16];
Bilinear_Fast_Common(PColor0,(TARGB32*)((TUInt8*)(PColor0)+Src_byte_width),(srcx_16 & 0xFFFF)>>8,v_8,&pDstLine[x]);
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
}
)
G:利用單指令多資料處理的MMX指令一般都可以加快顏色的運算;在使用MMX改寫之前,利用
32bit暫存器(或變數)來模擬單指令多資料處理;
資料儲存原理:一個顏色資料分量只有一個位元組,用2個位元組來儲存單個顏色分量的計算結果,
對於很多顏色計算來說精度就夠了;那麼一個32bit暫存器(或變數)就可以儲存2個計算出的
臨時顏色分量;從而達到了單個指令兩路資料處理的目的;
單個指令兩路資料處理的計算:
乘法: ((0x00AA*a)<<16) | (0x00BB*a) = 0x00AA00BB * a
可見只要保證0x00AA*a和0x00BB*a都小於(1<<16)那麼乘法可以直接使用無符號數乘法了
加法: ((0x00AA+0x00CC)<<16) | (0x00BB+0x00DD) = 0x00AA00BB + 0x00CC00DD
可見只要0x00AA+0x00CC和0x00BB+0x00DD小於(1<<16)那麼加法可以直接使用無符號數加法了
(移位、減法等稍微複雜一點,因為這裡沒有用到就不推倒運算公式了)
{
unsigned long pm3_8=(u_8*v_8)>>8;
unsigned long pm2_8=u_8-pm3_8;
unsigned long pm1_8=v_8-pm3_8;
unsigned long pm0_8=256-pm1_8-pm2_8-pm3_8;
unsigned long Color=*(unsigned long*)(PColor0);
unsigned long BR=(Color & 0x00FF00FF)*pm0_8;
unsigned long GA=((Color & 0xFF00FF00)>>8)*pm0_8;
Color=((unsigned long*)(PColor0))[1];
GA+=((Color & 0xFF00FF00)>>8)*pm2_8;
BR+=(Color & 0x00FF00FF)*pm2_8;
Color=*(unsigned long*)(PColor1);
GA+=((Color & 0xFF00FF00)>>8)*pm1_8;
BR+=(Color & 0x00FF00FF)*pm1_8;
Color=((unsigned long*)(PColor1))[1];
GA+=((Color & 0xFF00FF00)>>8)*pm3_8;
BR+=(Color & 0x00FF00FF)*pm3_8;
*(unsigned long*)(result)=(GA & 0xFF00FF00)|((BR & 0xFF00FF00)>>8);
}
inline void Bilinear_Border_Common(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
long x=(x_16>>16);
long y=(y_16>>16);
unsigned long u_16=((unsigned short)(x_16));
unsigned long v_16=((unsigned short)(y_16));
TARGB32 pixel[4];
pixel[0]=Pixels_Bound(pic,x,y);
pixel[1]=Pixels_Bound(pic,x+1,y);
pixel[2]=Pixels_Bound(pic,x,y+1);
pixel[3]=Pixels_Bound(pic,x+1,y+1);
Bilinear_Fast_Common(&pixel[0],&pixel[2],u_16>>8,v_16>>8,result);
}
void PicZoom_Bilinear_Common(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
long xrIntFloat_16=((Src.width)<<16)/Dst.width+1;
long yrIntFloat_16=((Src.height)<<16)/Dst.height+1;
const long csDErrorX=-(1<<15)+(xrIntFloat_16>>1);
const long csDErrorY=-(1<<15)+(yrIntFloat_16>>1);
unsigned long dst_width=Dst.width;
//計算出需要特殊處理的邊界
long border_y0=-csDErrorY/yrIntFloat_16+1; //y0+y*yr>=0; y0=csDErrorY => y>=-csDErrorY/yr
if (border_y0>=Dst.height) border_y0=Dst.height;
long border_x0=-csDErrorX/xrIntFloat_16+1;
if (border_x0>=Dst.width ) border_x0=Dst.width;
long border_y1=(((Src.height-2)<<16)-csDErrorY)/yrIntFloat_16+1; //y0+y*yr<=(height-2) => y<=(height-2-csDErrorY)/yr
if (border_y1<border_y0) border_y1=border_y0;
long border_x1=(((Src.width-2)<<16)-csDErrorX)/xrIntFloat_16+1;
if (border_x1<border_x0) border_x1=border_x0;
TARGB32* pDstLine=Dst.pdata;
long Src_byte_width=Src.byte_width;
long srcy_16=csDErrorY;
long y;
for (y=0;y<border_y0;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y0;y<border_y1;++y)
{
long srcx_16=csDErrorX;
long x;
for (x=0;x<border_x0;++x)
{
Bilinear_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
{
unsigned long v_8=(srcy_16 & 0xFFFF)>>8;
TARGB32* PSrcLineColor= (TARGB32*)((TUInt8*)(Src.pdata)+Src_byte_width*(srcy_16>>16)) ;
for (unsigned long x=border_x0;x<border_x1;++x)
{
TARGB32* PColor0=&PSrcLineColor[srcx_16>>16];
TARGB32* PColor1=(TARGB32*)((TUInt8*)(PColor0)+Src_byte_width);
Bilinear_Fast_Common(PColor0,PColor1,(srcx_16 & 0xFFFF)>>8,v_8,&pDstLine[x]);
srcx_16+=xrIntFloat_16;
}
}
for (x=border_x1;x<dst_width;++x)
{
Bilinear_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y1;y<Dst.height;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_BilInear_Common 65.3 fps
////////////////////////////////////////////////////////////////////////////////
H:使用MMX指令改寫:PicZoom_Bilinear_MMX
{
asm
{
MOVD MM6,v_8
MOVD MM5,u_8
mov edx,PColor0
mov eax,PColor1
PXOR mm7,mm7
MOVD MM2,dword ptr [eax]
MOVD MM0,dword ptr [eax+4]
PUNPCKLWD MM5,MM5
PUNPCKLWD MM6,MM6
MOVD MM3,dword ptr [edx]
MOVD MM1,dword ptr [edx+4]
PUNPCKLDQ MM5,MM5
PUNPCKLBW MM0,MM7
PUNPCKLBW MM1,MM7
PUNPCKLBW MM2,MM7
PUNPCKLBW MM3,MM7
PSUBw MM0,MM2
PSUBw MM1,MM3
PSLLw MM2,8
PSLLw MM3,8
PMULlw MM0,MM5
PMULlw MM1,MM5
PUNPCKLDQ MM6,MM6
PADDw MM0,MM2
PADDw MM1,MM3
PSRLw MM0,8
PSRLw MM1,8
PSUBw MM0,MM1
PSLLw MM1,8
PMULlw MM0,MM6
mov eax,result
PADDw MM0,MM1
PSRLw MM0,8
PACKUSwb MM0,MM7
movd [eax],MM0
//emms
}
}
void Bilinear_Border_MMX(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
long x=(x_16>>16);
long y=(y_16>>16);
unsigned long u_16=((unsigned short)(x_16));
unsigned long v_16=((unsigned short)(y_16));
TARGB32 pixel[4];
pixel[0]=Pixels_Bound(pic,x,y);
pixel[1]=Pixels_Bound(pic,x+1,y);
pixel[2]=Pixels_Bound(pic,x,y+1);
pixel[3]=Pixels_Bound(pic,x+1,y+1);
Bilinear_Fast_MMX(&pixel[0],&pixel[2],u_16>>8,v_16>>8,result);
}
void PicZoom_Bilinear_MMX(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
long xrIntFloat_16=((Src.width)<<16)/Dst.width+1;
long yrIntFloat_16=((Src.height)<<16)/Dst.height+1;
const long csDErrorX=-(1<<15)+(xrIntFloat_16>>1);
const long csDErrorY=-(1<<15)+(yrIntFloat_16>>1);
unsigned long dst_width=Dst.width;
//計算出需要特殊處理的邊界
long border_y0=-csDErrorY/yrIntFloat_16+1; //y0+y*yr>=0; y0=csDErrorY => y>=-csDErrorY/yr
if (border_y0>=Dst.height) border_y0=Dst.height;
long border_x0=-csDErrorX/xrIntFloat_16+1;
if (border_x0>=Dst.width ) border_x0=Dst.width;
long border_y1=(((Src.height-2)<<16)-csDErrorY)/yrIntFloat_16+1; //y0+y*yr<=(height-2) => y<=(height-2-csDErrorY)/yr
if (border_y1<border_y0) border_y1=border_y0;
long border_x1=(((Src.width-2)<<16)-csDErrorX)/xrIntFloat_16+1;
if (border_x1<border_x0) border_x1=border_x0;
TARGB32* pDstLine=Dst.pdata;
long Src_byte_width=Src.byte_width;
long srcy_16=csDErrorY;
long y;
for (y=0;y<border_y0;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y0;y<border_y1;++y)
{
long srcx_16=csDErrorX;
long x;
for (x=0;x<border_x0;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
{
unsigned long v_8=(srcy_16 & 0xFFFF)>>8;
TARGB32* PSrcLineColor= (TARGB32*)((TUInt8*)(Src.pdata)+Src_byte_width*(srcy_16>>16)) ;
for (unsigned long x=border_x0;x<border_x1;++x)
{
TARGB32* PColor0=&PSrcLineColor[srcx_16>>16];
TARGB32* PColor1=(TARGB32*)((TUInt8*)(PColor0)+Src_byte_width);
Bilinear_Fast_MMX(PColor0,PColor1,(srcx_16 & 0xFFFF)>>8,v_8,&pDstLine[x]);
srcx_16+=xrIntFloat_16;
}
}
for (x=border_x1;x<dst_width;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y1;y<Dst.height;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
asm emms
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_BilInear_MMX 132.9 fps
////////////////////////////////////////////////////////////////////////////////
H' 對BilInear_MMX簡單改進:PicZoom_Bilinear_MMX_Ex
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
long xrIntFloat_16=((Src.width)<<16)/Dst.width+1;
long yrIntFloat_16=((Src.height)<<16)/Dst.height+1;
const long csDErrorX=-(1<<15)+(xrIntFloat_16>>1);
const long csDErrorY=-(1<<15)+(yrIntFloat_16>>1);
unsigned long dst_width=Dst.width;
//計算出需要特殊處理的邊界
long border_y0=-csDErrorY/yrIntFloat_16+1; //y0+y*yr>=0; y0=csDErrorY => y>=-csDErrorY/yr
if (border_y0>=Dst.height) border_y0=Dst.height;
long border_x0=-csDErrorX/xrIntFloat_16+1;
if (border_x0>=Dst.width ) border_x0=Dst.width;
long border_y1=(((Src.height-2)<<16)-csDErrorY)/yrIntFloat_16+1; //y0+y*yr<=(height-2) => y<=(height-2-csDErrorY)/yr
if (border_y1<border_y0) border_y1=border_y0;
long border_x1=(((Src.width-2)<<16)-csDErrorX)/xrIntFloat_16+1;
if (border_x1<border_x0) border_x1=border_x0;
TARGB32* pDstLine=Dst.pdata;
long Src_byte_width=Src.byte_width;
long srcy_16=csDErrorY;
long y;
for (y=0;y<border_y0;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y0;y<border_y1;++y)
{
long srcx_16=csDErrorX;
long x;
for (x=0;x<border_x0;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
{
long dst_width_fast=border_x1-border_x0;
if (dst_width_fast>0)
{
unsigned long v_8=(srcy_16 & 0xFFFF)>>8;
TARGB32* PSrcLineColor= (TARGB32*)((TUInt8*)(Src.pdata)+Src_byte_width*(srcy_16>>16)) ;
TARGB32* PSrcLineColorNext= (TARGB32*)((TUInt8*)(PSrcLineColor)+Src_byte_width) ;
TARGB32* pDstLine_Fast=&pDstLine[border_x0];
asm
{
movd mm6,v_8
pxor mm7,mm7 //mm7=0
PUNPCKLWD MM6,MM6
PUNPCKLDQ MM6,MM6//mm6=v_8
mov esi,PSrcLineColor
mov ecx,PSrcLineColorNext
mov edx,srcx_16
mov ebx,dst_width_fast
mov edi,pDstLine_Fast
lea edi,[edi+ebx*4]
push ebp
mov ebp,xrIntFloat_16
neg ebx
loop_start:
mov eax,edx
shl eax,16
shr eax,24
//== movzx eax,dh //eax=u_8
MOVD MM5,eax
mov eax,edx
shr eax,16 //srcx_16>>16
MOVD MM2,dword ptr [ecx+eax*4]
MOVD MM0,dword ptr [ecx+eax*4+4]
PUNPCKLWD MM5,MM5
MOVD MM3,dword ptr [esi+eax*4]
MOVD MM1,dword ptr [esi+eax*4+4]
PUNPCKLDQ MM5,MM5 //mm5=u_8
PUNPCKLBW MM0,MM7
PUNPCKLBW MM1,MM7
PUNPCKLBW MM2,MM7
PUNPCKLBW MM3,MM7
PSUBw MM0,MM2
PSUBw MM1,MM3
PSLLw MM2,8
PSLLw MM3,8
PMULlw MM0,MM5
PMULlw MM1,MM5
PADDw MM0,MM2
PADDw MM1,MM3
PSRLw MM0,8
PSRLw MM1,8
PSUBw MM0,MM1
PSLLw MM1,8
PMULlw MM0,MM6
PADDw MM0,MM1
PSRLw MM0,8
PACKUSwb MM0,MM7
MOVd dword ptr [edi+ebx*4],MM0 //write DstColor
add edx,ebp //srcx_16+=xrIntFloat_16
inc ebx
jnz loop_start
pop ebp
mov srcx_16,edx
}
}
}
for (x=border_x1;x<dst_width;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y1;y<Dst.height;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
Bilinear_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
asm emms
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_Bilinear_MMX_Ex 157.0 fps
////////////////////////////////////////////////////////////////////////////////
I: 把測試成績放在一起:
////////////////////////////////////////////////////////////////////////////////
//CPU: AMD64x2 4200+(2.37G) zoom 800*600 to 1024*768
//==============================================================================
// StretchBlt 232.7 fps
// PicZoom3_SSE 711.7 fps
//
// PicZoom_BilInear0 8.3 fps
// PicZoom_BilInear1 17.7 fps
// PicZoom_BilInear2 43.4 fps
// PicZoom_BilInear_Common 65.3 fps
// PicZoom_BilInear_MMX 132.9 fps
// PicZoom_BilInear_MMX_Ex 157.0 fps
////////////////////////////////////////////////////////////////////////////////
補充Intel Core2 4400上的測試成績:
////////////////////////////////////////////////////////////////////////////////
//CPU: Intel Core2 4400(2.00G) zoom 800*600 to 1024*768
//==============================================================================
// PicZoom3_SSE 1099.7 fps
//
// PicZoom_BilInear0 10.7 fps
// PicZoom_BilInear1 24.2 fps
// PicZoom_BilInear2 54.3 fps
// PicZoom_BilInear_Common 59.8 fps
// PicZoom_BilInear_MMX 118.4 fps
// PicZoom_BilInear_MMX_Ex 142.9 fps
////////////////////////////////////////////////////////////////////////////////
三次卷積插值:
J: 二次線性插值縮放出的圖片很多時候讓人感覺變得模糊(術語叫低通濾波),特別是在放大
的時候;使用三次卷積插值來改善插值結果;三次卷積插值考慮對映點周圍16個點(4x4)的顏色來
計算最終的混合顏色,如圖;
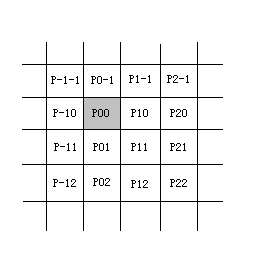
P(0,0)所在畫素為對映的點,加上它周圍的15個點,按一定係數混合得到最終輸出結果;
混合公式參見PicZoom_ThreeOrder0的實現;
插值曲線公式sin(x*PI)/(x*PI),如圖:
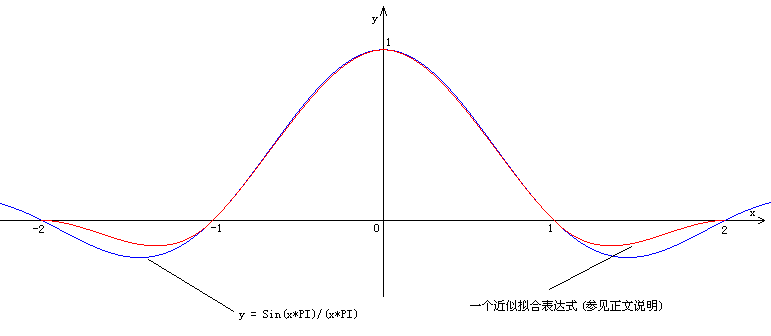
三次卷積插值曲線sin(x*PI)/(x*PI) (其中PI=3.1415926...)
K:三次卷積插值縮放演算法的一個參考實現:PicZoom_ThreeOrder0
該函式並沒有做過多的優化,只是一個簡單的浮點實現版本;
inline double SinXDivX(double x)
{
//該函式計算插值曲線sin(x*PI)/(x*PI)的值 //PI=3.1415926535897932385;
//下面是它的近似擬合表示式
const float a = -1; //a還可以取 a=-2,-1,-0.75,-0.5等等,起到調節銳化或模糊程度的作用
if (x<0) x=-x; //x=abs(x);
double x2=x*x;
double x3=x2*x;
if (x<=1)
return (a+2)*x3 - (a+3)*x2 + 1;
else if (x<=2)
return a*x3 - (5*a)*x2 + (8*a)*x - (4*a);
else
return 0;
}
inline TUInt8 border_color(long Color)
{
if (Color<=0)
return 0;
else if (Color>=255)
return 255;
else
return Color;
}
void ThreeOrder0(const TPicRegion& pic,const float fx,const float fy,TARGB32* result)
{
long x0=(long)fx; if (x0>fx) --x0; //x0=floor(fx);
long y0=(long)fy; if (y0>fy) --y0; //y0=floor(fy);
float fu=fx-x0;
float fv=fy-y0;
TARGB32 pixel[16];
long i,j;
for (i=0;i<4;++i)
{
for (j=0;j<4;++j)
{
long x=x0-1+j;
long y=y0-1+i;
pixel[i*4+j]=Pixels_Bound(pic,x,y);
}
}
float afu[4],afv[4];
//
afu[0]=SinXDivX(1+fu);
afu[1]=SinXDivX(fu);
afu[2]=SinXDivX(1-fu);
afu[3]=SinXDivX(2-fu);
afv[0]=SinXDivX(1+fv);
afv[1]=SinXDivX(fv);
afv[2]=SinXDivX(1-fv);
afv[3]=SinXDivX(2-fv);
float sR=0,sG=0,sB=0,sA=0;
for (i=0;i<4;++i)
{
float aR=0,aG=0,aB=0,aA=0;
for (long j=0;j<4;++j)
{
aA+=afu[j]*pixel[i*4+j].a;
aR+=afu[j]*pixel[i*4+j].r;
aG+=afu[j]*pixel[i*4+j].g;
aB+=afu[j]*pixel[i*4+j].b;
}
sA+=aA*afv[i];
sR+=aR*afv[i];
sG+=aG*afv[i];
sB+=aB*afv[i];
}
result->a=border_color((long)(sA+0.5));
result->r=border_color((long)(sR+0.5));
result->g=border_color((long)(sG+0.5));
result->b=border_color((long)(sB+0.5));
}
void PicZoom_ThreeOrder0(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
unsigned long dst_width=Dst.width;
TARGB32* pDstLine=Dst.pdata;
for (unsigned long y=0;y<Dst.height;++y)
{
float srcy=(y+0.4999999)*Src.height/Dst.height-0.5;
for (unsigned long x=0;x<dst_width;++x)
{
float srcx=(x+0.4999999)*Src.width/Dst.width-0.5;
ThreeOrder0(Src,srcx,srcy,&pDstLine[x]);
}
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_ThreeOrder0 3.6 fps
////////////////////////////////////////////////////////////////////////////////
L: 使用定點數來優化縮放函式;邊界和內部分開處理;對SinXDivX做一個查詢表;對border_color做一個查詢表;
class _CAutoInti_SinXDivX_Table {
private:
void _Inti_SinXDivX_Table()
{
for (long i=0;i<=(2<<8);++i)
SinXDivX_Table_8[i]=long(0.5+256*SinXDivX(i*(1.0/(256))))*1;
};
public:
_CAutoInti_SinXDivX_Table() { _Inti_SinXDivX_Table(); }
};
static _CAutoInti_SinXDivX_Table __tmp_CAutoInti_SinXDivX_Table;
//顏色查表
static TUInt8 _color_table[256*3];
static const TUInt8* color_table=&_color_table[256];
class _CAuto_inti_color_table
{
public:
_CAuto_inti_color_table() {
for (int i=0;i<256*3;++i)
_color_table[i]=border_color(i-256);
}
};
static _CAuto_inti_color_table _Auto_inti_color_table;
void ThreeOrder_Fast_Common(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
unsigned long u_8=(unsigned char)((x_16)>>8);
unsigned long v_8=(unsigned char)((y_16)>>8);
const TARGB32* pixel=&Pixels(pic,(x_16>>16)-1,(y_16>>16)-1);
long pic_byte_width=pic.byte_width;
long au_8[4],av_8[4];
//
au_8[0]=SinXDivX_Table_8[(1<<8)+u_8];
au_8[1]=SinXDivX_Table_8[u_8];
au_8[2]=SinXDivX_Table_8[(1<<8)-u_8];
au_8[3]=SinXDivX_Table_8[(2<<8)-u_8];
av_8[0]=SinXDivX_Table_8[(1<<8)+v_8];
av_8[1]=SinXDivX_Table_8[v_8];
av_8[2]=SinXDivX_Table_8[(1<<8)-v_8];
av_8[3]=SinXDivX_Table_8[(2<<8)-v_8];
long sR=0,sG=0,sB=0,sA=0;
for (long i=0;i<4;++i)
{
long aA=au_8[0]*pixel[0].a + au_8[1]*pixel[1].a + au_8[2]*pixel[2].a + au_8[3]*pixel[3].a;
long aR=au_8[0]*pixel[0].r + au_8[1]*pixel[1].r + au_8[2]*pixel[2].r + au_8[3]*pixel[3].r;
long aG=au_8[0]*pixel[0].g + au_8[1]*pixel[1].g + au_8[2]*pixel[2].g + au_8[3]*pixel[3].g;
long aB=au_8[0]*pixel[0].b + au_8[1]*pixel[1].b + au_8[2]*pixel[2].b + au_8[3]*pixel[3].b;
sA+=aA*av_8[i];
sR+=aR*av_8[i];
sG+=aG*av_8[i];
sB+=aB*av_8[i];
((TUInt8*&)pixel)+=pic_byte_width;
}
result->a=color_table[sA>>16];
result->r=color_table[sR>>16];
result->g=color_table[sG>>16];
result->b=color_table[sB>>16];
}
void ThreeOrder_Border_Common(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
long x0_sub1=(x_16>>16)-1;
long y0_sub1=(y_16>>16)-1;
unsigned long u_16_add1=((unsigned short)(x_16))+(1<<16);
unsigned long v_16_add1=((unsigned short)(y_16))+(1<<16);
TARGB32 pixel[16];
long i;
for (i=0;i<4;++i)
{
long y=y0_sub1+i;
pixel[i*4+0]=Pixels_Bound(pic,x0_sub1+0,y);
pixel[i*4+1]=Pixels_Bound(pic,x0_sub1+1,y);
pixel[i*4+2]=Pixels_Bound(pic,x0_sub1+2,y);
pixel[i*4+3]=Pixels_Bound(pic,x0_sub1+3,y);
}
TPicRegion npic;
npic.pdata =&pixel[0];
npic.byte_width=4*sizeof(TARGB32);
//npic.width =4;
//npic.height =4;
ThreeOrder_Fast_Common(npic,u_16_add1,v_16_add1,result);
}
void PicZoom_ThreeOrder_Common(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
long xrIntFloat_16=((Src.width)<<16)/Dst.width+1;
long yrIntFloat_16=((Src.height)<<16)/Dst.height+1;
const long csDErrorX=-(1<<15)+(xrIntFloat_16>>1);
const long csDErrorY=-(1<<15)+(yrIntFloat_16>>1);
unsigned long dst_width=Dst.width;
//計算出需要特殊處理的邊界
long border_y0=((1<<16)-csDErrorY)/yrIntFloat_16+1;//y0+y*yr>=1; y0=csDErrorY => y>=(1-csDErrorY)/yr
if (border_y0>=Dst.height) border_y0=Dst.height;
long border_x0=((1<<16)-csDErrorX)/xrIntFloat_16+1;
if (border_x0>=Dst.width ) border_x0=Dst.width;
long border_y1=(((Src.height-3)<<16)-csDErrorY)/yrIntFloat_16+1; //y0+y*yr<=(height-3) => y<=(height-3-csDErrorY)/yr
if (border_y1<border_y0) border_y1=border_y0;
long border_x1=(((Src.width-3)<<16)-csDErrorX)/xrIntFloat_16+1;;
if (border_x1<border_x0) border_x1=border_x0;
TARGB32* pDstLine=Dst.pdata;
long srcy_16=csDErrorY;
long y;
for (y=0;y<border_y0;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
ThreeOrder_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y0;y<border_y1;++y)
{
long srcx_16=csDErrorX;
long x;
for (x=0;x<border_x0;++x)
{
ThreeOrder_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
for (x=border_x0;x<border_x1;++x)
{
ThreeOrder_Fast_Common(Src,srcx_16,srcy_16,&pDstLine[x]);//fast !
srcx_16+=xrIntFloat_16;
}
for (x=border_x1;x<dst_width;++x)
{
ThreeOrder_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y1;y<Dst.height;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
ThreeOrder_Border_Common(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_ThreeOrder_Common 16.9 fps
////////////////////////////////////////////////////////////////////////////////
M: 用MMX來優化ThreeOrder_Common函式:ThreeOrder_MMX
static TMMXData32 SinXDivX_Table_MMX[(2<<8)+1];
class _CAutoInti_SinXDivX_Table_MMX {
private:
void _Inti_SinXDivX_Table_MMX()
{
for (long i=0;i<=(2<<8);++i)
{
unsigned short t=long(0.5+(1<<14)*SinXDivX(i*(1.0/(256))));
unsigned long tl=t | (((unsigned long)t)<<16);
SinXDivX_Table_MMX[i]=tl;
}
};
public:
_CAutoInti_SinXDivX_Table_MMX() { _Inti_SinXDivX_Table_MMX(); }
};
static _CAutoInti_SinXDivX_Table_MMX __tmp_CAutoInti_SinXDivX_Table_MMX;
void __declspec(naked) _private_ThreeOrder_Fast_MMX()
{
asm
{
movd mm1,dword ptr [edx]
movd mm2,dword ptr [edx+4]
movd mm3,dword ptr [edx+8]
movd mm4,dword ptr [edx+12]
movd mm5,dword ptr [(offset SinXDivX_Table_MMX)+256*4+eax*4]
movd mm6,dword ptr [(offset SinXDivX_Table_MMX)+eax*4]
punpcklbw mm1,mm7
punpcklbw mm2,mm7
punpcklwd mm5,mm5
punpcklwd mm6,mm6
psllw mm1,7
psllw mm2,7
pmulhw mm1,mm5
pmulhw mm2,mm6
punpcklbw mm3,mm7
punpcklbw mm4,mm7
movd mm5,dword ptr [(offset SinXDivX_Table_MMX)+256*4+ecx*4]
movd mm6,dword ptr [(offset SinXDivX_Table_MMX)+512*4+ecx*4]
punpcklwd mm5,mm5
punpcklwd mm6,mm6
psllw mm3,7
psllw mm4,7
pmulhw mm3,mm5
pmulhw mm4,mm6
paddsw mm1,mm2
paddsw mm3,mm4
movd mm6,dword ptr [ebx] //v
paddsw mm1,mm3
punpcklwd mm6,mm6
pmulhw mm1,mm6
add edx,esi //+pic.byte_width
paddsw mm0,mm1
ret
}
}
inline void ThreeOrder_Fast_MMX(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
asm
{
mov ecx,pic
mov eax,y_16
mov ebx,x_16
movzx edi,ah //v_8
mov edx,[ecx+TPicRegion::pdata]
shr eax,16
mov esi,[ecx+TPicRegion::byte_width]
dec eax
movzx ecx,bh //u_8
shr ebx,16
imul eax,esi
lea edx,[edx+ebx*4-4]
add edx,eax //pixel
mov eax,ecx
neg ecx
pxor mm7,mm7 //0
//mov edx,pixel
pxor mm0,mm0 //result=0
//lea eax,auv_7
lea ebx,[(offset SinXDivX_Table_MMX)+256*4+edi*4]
call _private_ThreeOrder_Fast_MMX
lea ebx,[(offset SinXDivX_Table_MMX)+edi*4]
call _private_ThreeOrder_Fast_MMX
neg edi
lea ebx,[(offset SinXDivX_Table_MMX)+256*4+edi*4]
call _private_ThreeOrder_Fast_MMX
lea ebx,[(offset SinXDivX_Table_MMX)+512*4+edi*4]
call _private_ThreeOrder_Fast_MMX
psraw mm0,3
mov eax,result
packuswb mm0,mm7
movd [eax],mm0
//emms
}
}
void ThreeOrder_Border_MMX(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
unsigned long x0_sub1=(x_16>>16)-1;
unsigned long y0_sub1=(y_16>>16)-1;
long u_16_add1=((unsigned short)(x_16))+(1<<16);
long v_16_add1=((unsigned short)(y_16))+(1<<16);
TARGB32 pixel[16];
for (long i=0;i<4;++i)
{
long y=y0_sub1+i;
pixel[i*4+0]=Pixels_Bound(pic,x0_sub1 ,y);
pixel[i*4+1]=Pixels_Bound(pic,x0_sub1+1,y);
pixel[i*4+2]=Pixels_Bound(pic,x0_sub1+2,y);
pixel[i*4+3]=Pixels_Bound(pic,x0_sub1+3,y);
}
TPicRegion npic;
npic.pdata =&pixel[0];
npic.byte_width=4*sizeof(TARGB32);
//npic.width =4;
//npic.height =4;
ThreeOrder_Fast_MMX(npic,u_16_add1,v_16_add1,result);
}
void PicZoom_ThreeOrder_MMX(const TPicRegion& Dst,const TPicRegion& Src)
{
if ( (0==Dst.width)||(0==Dst.height)
||(0==Src.width)||(0==Src.height)) return;
long xrIntFloat_16=((Src.width)<<16)/Dst.width+1;
long yrIntFloat_16=((Src.height)<<16)/Dst.height+1;
const long csDErrorX=-(1<<15)+(xrIntFloat_16>>1);
const long csDErrorY=-(1<<15)+(yrIntFloat_16>>1);
unsigned long dst_width=Dst.width;
//計算出需要特殊處理的邊界
long border_y0=((1<<16)-csDErrorY)/yrIntFloat_16+1;//y0+y*yr>=1; y0=csDErrorY => y>=(1-csDErrorY)/yr
if (border_y0>=Dst.height) border_y0=Dst.height;
long border_x0=((1<<16)-csDErrorX)/xrIntFloat_16+1;
if (border_x0>=Dst.width ) border_x0=Dst.width;
long border_y1=(((Src.height-3)<<16)-csDErrorY)/yrIntFloat_16+1; //y0+y*yr<=(height-3) => y<=(height-3-csDErrorY)/yr
if (border_y1<border_y0) border_y1=border_y0;
long border_x1=(((Src.width-3)<<16)-csDErrorX)/xrIntFloat_16+1;;
if (border_x1<border_x0) border_x1=border_x0;
TARGB32* pDstLine=Dst.pdata;
long srcy_16=csDErrorY;
long y;
for (y=0;y<border_y0;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
ThreeOrder_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y0;y<border_y1;++y)
{
long srcx_16=csDErrorX;
long x;
for (x=0;x<border_x0;++x)
{
ThreeOrder_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
for (x=border_x0;x<border_x1;++x)
{
ThreeOrder_Fast_MMX(Src,srcx_16,srcy_16,&pDstLine[x]);//fast MMX !
srcx_16+=xrIntFloat_16;
}
for (x=border_x1;x<dst_width;++x)
{
ThreeOrder_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]);//border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
for (y=border_y1;y<Dst.height;++y)
{
long srcx_16=csDErrorX;
for (unsigned long x=0;x<dst_width;++x)
{
ThreeOrder_Border_MMX(Src,srcx_16,srcy_16,&pDstLine[x]); //border
srcx_16+=xrIntFloat_16;
}
srcy_16+=yrIntFloat_16;
((TUInt8*&)pDstLine)+=Dst.byte_width;
}
asm emms
}
////////////////////////////////////////////////////////////////////////////////
//速度測試:
//==============================================================================
// PicZoom_ThreeOrder_MMX 34.3 fps
////////////////////////////////////////////////////////////////////////////////
N:將測試結果放到一起:
////////////////////////////////////////////////////////////////////////////////
//CPU: AMD64x2 4200+(2.37G) zoom 800*600 to 1024*768
//==============================================================================
// StretchBlt 232.7 fps
// PicZoom3_SSE 711.7 fps
// PicZoom_BilInear_MMX_Ex 157.0 fps
//
// PicZoom_ThreeOrder0 3.6 fps
// PicZoom_ThreeOrder_Common 16.9 fps
// PicZoom_ThreeOrder_MMX 34.3 fps
////////////////////////////////////////////////////////////////////////////////
補充Intel Core2 4400上的測試成績:
////////////////////////////////////////////////////////////////////////////////
//CPU: Intel Core2 4400(2.00G) zoom 800*600 to 1024*768
//==============================================================================
// PicZoom3_SSE 1099.7 fps
// PicZoom_BilInear_MMX_Ex 142.9 fps
//
// PicZoom_ThreeOrder0 4.2 fps
// PicZoom_ThreeOrder_Common 17.6 fps
// PicZoom_ThreeOrder_MMX 34.4 fps
////////////////////////////////////////////////////////////////////////////////
相關文章
- 圖形影象處理-之-高質量的快速的影象縮放 上篇 近鄰取樣插值和其速度優化優化
- [work] 影象縮放——雙線性插值演算法演算法
- 影象縮放--插值法(opencv,原理)OpenCV
- 【影像縮放】雙立方(三次)卷積插值卷積
- 影象縮放的雙線性內插值演算法的原理解析演算法
- opencv中自定義的雙線性二次插值的影像旋轉及縮放OpenCV
- [Python影象處理] 六.影象縮放、影象旋轉、影象翻轉與影象平移Python
- Python-OpenCV 處理影象(八):影象二值化處理PythonOpenCV
- 【數字影象處理】五.MFC影象點運算之灰度線性變化、灰度非線性變化、閾值化和均衡化處理詳解
- 影象放大並進行BiCubic插值 Matlab/C++程式碼MatlabC++
- 影象的卷積和池化操作卷積
- MATLAB一維插值和二維插值 比較Matlab
- [Python影象處理] 七.影象閾值化處理及演算法對比Python演算法
- SCSS #{} 插值CSS
- 極端影象壓縮的生成對抗網路,可生成低位元速率的高質量影象
- SSE影像演算法優化系列十八:三次卷積插值的進一步SSE優化。演算法優化卷積
- 二、插值操作
- MATLAB插值Matlab
- Swift 5 字串插值之美Swift字串
- 影象卷積與濾波卷積
- C++影象縮放C++
- NOISEDIFFUSION: 改進基於擴散模型的球面線性插值模型
- c#影象處理入門(-bitmap類和影象畫素值獲取方法)C#
- iOS 影象處理 - 影象拼接iOS
- webgl centroid質心插值的一點理解Web
- Java 實現高斯模糊和影象的空間卷積Java卷積
- 【java】【插值查詢】Java
- 求插值係數
- 插值技術研究
- 影像重取樣演算法之雙線性插值演算法演算法
- 介紹一種二維線性插值計算方法
- 資料分析缺失值處理(Missing Values)——刪除法、填充法、插值法
- 影象處理之影象增強
- Python-OpenCV 處理影象(四):影象直方圖和反向投影PythonOpenCV直方圖
- 二值影象分析之輪廓分析
- 插值查詢的簡單理解
- MemoryCache 的原生插值方式淺談
- 機器學習 第3篇:資料預處理(使用插補法處理缺失值)機器學習