搜尋引擎和知識圖譜那些事 (上).基礎篇
這是一篇基礎性文章,主要介紹搜尋引擎和知識圖譜的一些原理、發展經歷和應用等知識。希望文章對你有所幫助~如果有錯誤或不足之處,還請海涵。(參考資料見後)
一. 搜尋引擎
(一).搜尋引擎的四個時代
根據張俊林大神的《這就是搜尋引擎》這本書中描述(推薦大家閱讀),搜尋引擎從採取的技術劃分為4個時代:
1.史前時代:分類目錄的一代
這個時代成為“導航時代”,Yahoo和國內hao123是這個時代的代表。通過人工蒐集整理,把屬於各個類別的高質量網站或網頁分類,使用者通過分級目錄來查詢高質量的網站。這種純人工方式並未採取什麼高深的技術手段,採取分類目錄的方式,一般收錄的網站質量較高,但這種方式擴充套件性不強,絕大部分網站不能被收錄。
2.第一代:文字檢索的一代
文字檢索的一代採用經典的資訊檢索模型,如布林模型、向量空間模型或者概率模型,來計算使用者查詢關鍵詞和網頁文字內容的相關程度。早期很多搜尋引擎如AltaVista、Excite等大都採用這種模式。
相對分類目錄,這種方式可以收錄大部分網頁,並按照網頁內容和使用者查詢的匹配程度進行排序。但由於網頁之間有豐富的連結關係,而這一代搜尋引擎並未使用這些資訊,所以搜尋質量不是很好。
3.第二代:連結分析的一代
這一代搜尋引擎充分利用了網頁之間的連結關係,並深入挖掘和利用了網頁連結所代表的含義。通常而言,網頁連結代表了一種推薦關係,所以通過連結分析可以在海量內容中找出重要的網頁。被推薦次數多的網頁其實代表了其具有流行性,搜尋引擎通過結合網頁流行性和內容相似性來改善搜尋質量。
Google於1998年成立,它率先提出並使用PageRank連結分析技術,大幅度提高了搜尋質量。目前幾乎所有的搜尋引擎都採取了連結分析技術,但是這種技術並未考慮使用者的個性化要求,所以只要輸入的查詢請求相同,所有使用者都會獲得相同的搜尋結果。另外很多網站為獲取更高的搜尋排名,針對連結分析演算法提出不少連結作弊方案,這樣導致搜尋結果質量變差。
4.第三代:使用者中心的一代
第三代即理解使用者需求為核心的一代搜尋引擎。不同使用者即使輸入同一個查詢詞,但其目的可能不一樣。比如同樣輸入“蘋果”作為搜尋詞,一個追捧iPhone的時尚青年和一個果農的目的會存在巨大的差異。即使一個使用者,輸入相同的查詢詞,也會因為所在時間和場合不同,需求有所冰變化。
目前搜尋引擎大都致力於解決如何能夠理解使用者發出的某個很短小的查詢詞背後包含的真正需求的問題。為了獲取使用者真正的需求,目前搜尋引擎做了很多技術方面的嘗試。如利用使用者傳送查詢詞時的時間和地理位置資訊、利用使用者過去發出的查詢詞及相應的點選記錄等歷史資訊手段,來試圖理解使用者此時此地的真正需求。
(二).搜尋引擎的架構原理
搜尋引擎通常是使用者輸入查詢詞,搜尋引擎返回搜尋結果。其目標是:更全、更快、更準。
搜尋引擎需要對百億計的海量網頁進行獲取、儲存、處理,同時要保證搜尋結果的質量。如何獲取、儲存並計算這些海量資料?如何快速響應使用者的查詢?如何使得搜尋結果能夠滿足使用者的資訊需求?這些都是搜尋引擎面對的技術挑戰。
搜尋引擎涉及三個核心問題:
使用者真正的需求是什麼(使用者輸入的查詢詞非常簡單,查詢的平均長度是2.7個單詞,如何獲取使用者的真實需求)、哪些資訊是和使用者需求真正相關的(搜尋引擎的本質是一個匹配的過程,即從海量資料中匹配使用者的需求內容,如何從判斷內容和使用者查詢關鍵詞的相關性到讓計算機真正理解資訊所代表的含義)、哪些資訊是使用者可以信賴的(網際網路上所釋出內容是否可信並無明確的判斷標準,同一個查詢的搜尋結果可能完全是矛盾的答案,此時資訊的可信性尤為重要,連結分析也看成對資訊可信度做出的評判)。
下圖是一個通用的搜尋引擎架構示意圖:(完全參考《這就是搜尋引擎》)
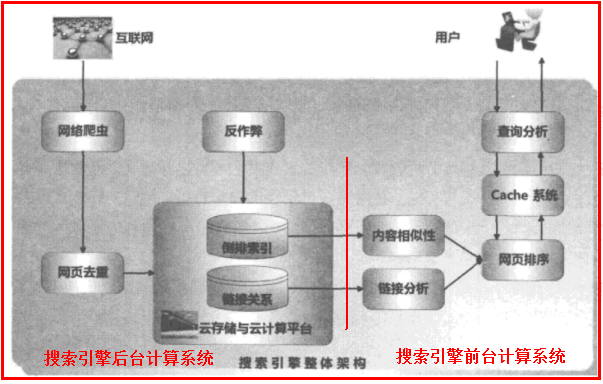
搜尋引擎後臺計算系統
搜尋引擎的資訊來源於網際網路網頁,通過網路爬蟲將整個網際網路的資訊獲取到本地,因此網際網路頁面中有很大部分內容是相同或相似的,“網頁去重”模組會對此作出檢測並去除重複內容。
之後,搜尋引擎會對網頁進行解析,抽取出網頁主體內容及頁面中包含的指向其他頁面的連結。為加快響應使用者查詢的速度,網頁內容通過“倒排索引”這種高效查詢資料結構儲存,網頁之間的連結關係也會儲存。因為通過“連結分析”可以判斷頁面的相對重要性,對於為使用者提供準確的搜尋結果幫助很大。
同時由於海量資料資訊巨大,所以採用雲端儲存與雲端計算平臺作為搜尋引擎及相關應用的基礎支撐。上述是關於搜尋引擎如何獲取及儲存海量的網頁相關資訊,不需要進行實時計算,所以被看做是搜尋引擎的後臺計算系統。
搜尋引擎前臺計算系統
搜尋引擎的最重要目的是為使用者提供準確全面的搜尋結果,如何響應使用者查詢並實時地提供準確結果構成了搜尋引擎前臺計算系統。
當搜尋引擎接到使用者的查詢詞後,首先對查詢詞進行分析,希望能夠結合查詢詞和使用者資訊來正確推導使用者的真正搜尋意圖。先在快取中查詢,快取系統中儲存了不同的查詢意圖對應的搜尋結果,如果能在快取中找到滿足使用者需求的資訊,則直接返回給使用者,即節省資源又加快響應速度。如果快取中不存在,則呼叫“網頁排序”模組功能。
“網頁排序”會根據使用者的查詢實時計算哪些網頁是滿足使用者資訊需求的,並排序輸出作為搜尋結果。而網頁排序中最重要的兩個因素是:內容相似性因素(哪些網頁和使用者查詢相關)和網頁的重要性因素(哪些網頁質量好或相對重要,通過連結分析結果獲得)。然後網頁進行排序,作為使用者查詢的搜尋結果。
同時,搜尋引擎的“反作弊”模組主要自動發現那些通過各種手段將網頁的搜尋排名提高到與其網頁質量不相稱的位置,這會嚴重影響搜尋體驗。現在也出現一種成功的新網際網路公司遮蔽搜尋引擎公司爬蟲的現象,比如Facebook對Google的遮蔽,國內淘寶對百度的遮蔽,主要是商業公司之間的競爭策略,也可看做是垂直搜尋和通用搜尋的競爭。
(三).搜尋引擎簡單技術分析
按照技術原理,搜尋引擎又可以分為三類:
1.全文檢索搜尋引擎(Full Text Search Engine)
國外具有代表的有Google、Yahoo、AltaVista、Teoma等,國內如百度、北大天網等。它們都是從網際網路上提取各個網站的資訊(以網頁文字為主)而建立的資料庫中,檢索與使用者查詢條件匹配相關的記錄,然後按照一定的排序將結果返回給使用者。
2.目錄搜尋引擎(Search Index)
嚴格意義上它不是真正的搜尋引擎,僅僅是按照目錄分類的網站連結列表,雖然它具有搜尋功能。使用者完全可以不用進行關鍵詞查詢,僅靠分類目錄就可以找到需要的資訊,最具代表性的是Yahoo雅虎。國內的搜狐、網易、新浪、hao123等都屬於該類。
目錄介面一般採用分級結構,使用者從基本的大類入口一級級向下訪問,直到找到中意的內容,使用者也可以通過目錄提供的搜尋功能查詢關鍵詞。由於採用人工分類,搜尋結果比Robot搜尋更精準,但侷限性也明顯。
3.元搜尋引擎(Meta Search Engine)
在接受使用者查詢請求時,同時在其他多個引擎上進行搜尋,它自己不進行WWW的遍歷,也沒有自己的索引資料庫。當使用者查詢一個關鍵詞時,它把查詢請求轉換為其他搜尋引擎的命令形式,分別向其他搜尋引擎提交,然後彙總這些搜尋引擎返回的結果,返回給使用者瀏覽器。著名的搜星搜尋引擎就是一箇中文元搜尋引擎。
搜尋引擎通常由搜尋器、索引器、檢索器和使用者介面四部分組成。
就基於中文字詞的特點,由於漢字字元數量多、編碼方式複雜、中文詞分詞(字構成)困難等,所以中文搜尋引擎必須要有專門的中文資訊處理模組來完成中文文件的分詞處理、碼制轉換和全形處理等工作。
同時在“百度招聘”中你可能會看到它的核心部門包括網頁搜尋部、垂直搜尋部等,那麼垂直搜尋是個什麼東西呢?這裡作簡單的補充。
垂直搜尋引擎
它也稱為主題搜尋引擎或專題搜尋引擎。它是對網頁庫中的某類專門的資訊進行一次整合,只關注某一領域或地域的資訊,這些資訊儲存和索引之後,使用者就可以檢索只涉及這部分的資訊。垂直搜尋引擎與通用搜尋引擎最大的區別是:通用搜尋引擎是面向所有使用者的,而垂直搜尋引擎是面向某一領域的使用者。如酒店、道路、公交、商店資訊等,生活搜尋引擎極大的滿足了使用者的出行和旅遊。
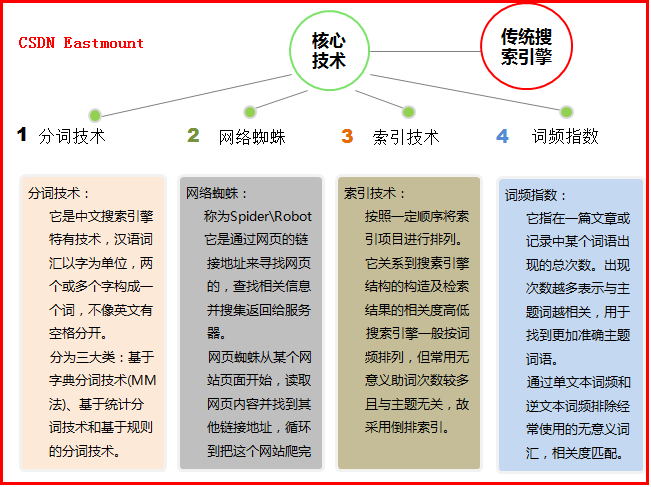
傳統搜尋引擎的核心技術常見包括:分詞技術、網路蜘蛛、索引技術和詞頻指數。
二. 知識圖譜
(一).知識圖譜的應用
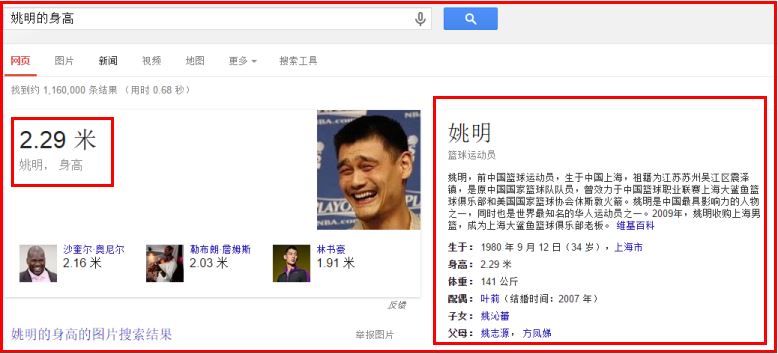
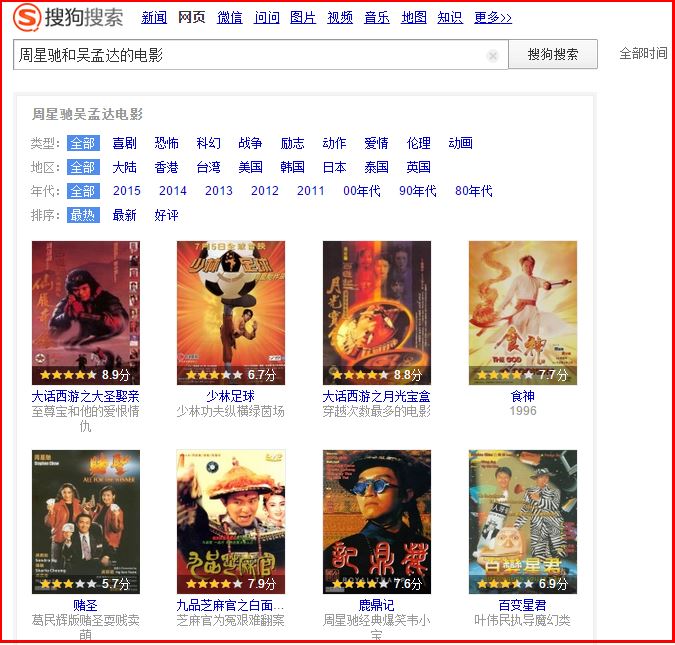
首先通過知識圖譜的應用引入這個概念,同時體會它的優點。傳統的搜尋引擎搜尋“姚明的身高”,返回的結果是網頁內容與姚明身高的相關一些列連結。如Yahoo:

自語義網的概念提出,越來越多的開放連結資料和使用者生成內容被髮佈於網際網路中。網際網路逐步從僅包含網頁與網頁之間超連結的文件全球資訊網轉變為包含大量描述各種實體和實體之間豐富關係的資料全球資訊網。
在此背景下,知識圖譜(Knowledge Graph)於2012年5月首先由Google提出,其目標在於描述真實世界中存在的各種實體和概念,及實體、概念之間的關聯關係,從而改善搜尋結果。緊隨其後,國內搜狗提出了“知立方”、微軟的Probase和百度的“知心”。
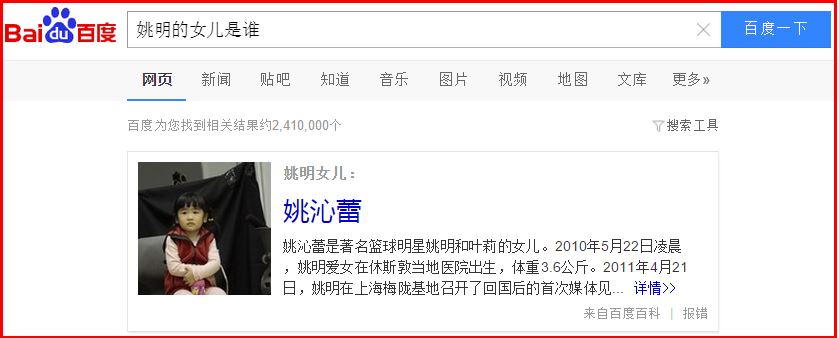
如下圖所示,通過知識圖譜可以搜尋到“姚明的女兒”,如百度知心:
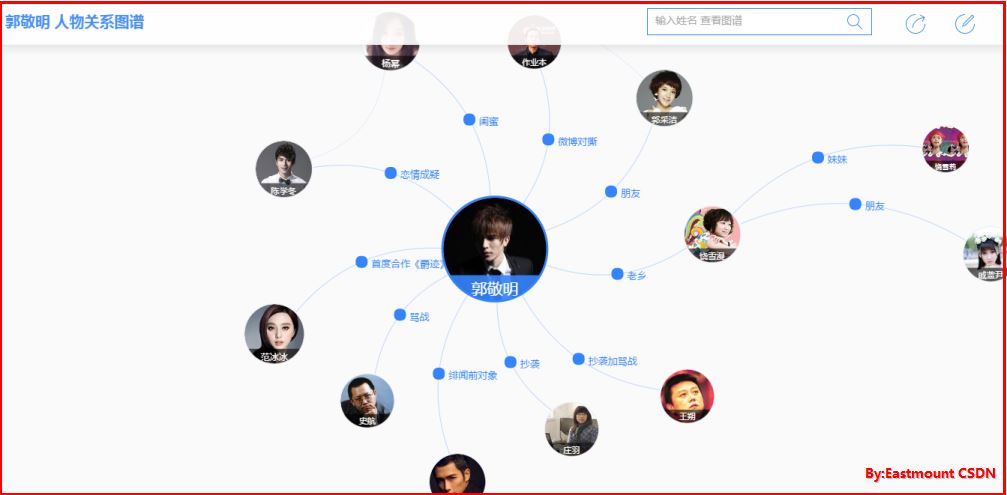

(二).知識圖譜的框架
通過上面的敘述,我們發現傳統的搜尋引擎和知識圖譜的變化:
1.資訊抽取目標發生了變化,傳統的文字指定抽取(ACE)=>海量資料的發現(KBP);
2.從文字分析為核心轉變成了知識發現為核心;
3.讓計算機真正理解使用者的查詢需求,給出準確答案而不是給出相關的連結序列;
目前世界有代表性的知識庫或應用系統包括KnowItAll、TextRunner、基於維基百科的DBpedia、YAGO;公司開發的知識搜尋或計算平臺如谷歌KnowledgeGraph、Facebook推出的實體搜尋服務Graph Search、Evi公司TrueKnowledge知識搜尋平臺。
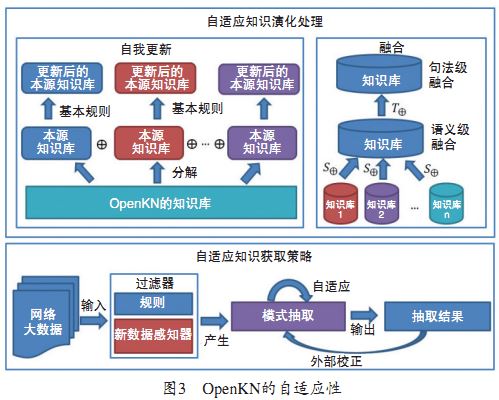
因王元卓等人提出的一種面向網路大資料的、開放的、自適應的、可演化的、可計算的知識計算引擎——OpenKN,其原理類似於知識圖譜,故通過該框架圖進行簡單講解。
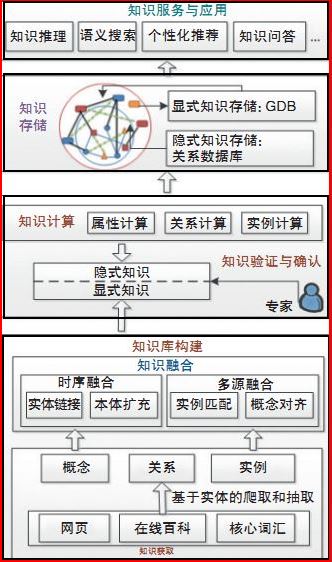
這些模組實現了一個全生命週期的知識處理,從知識獲取、知識融合、知識驗證、知識計算、知識儲存到知識服務與應用的知識處理工作流程。
知識庫的構建:
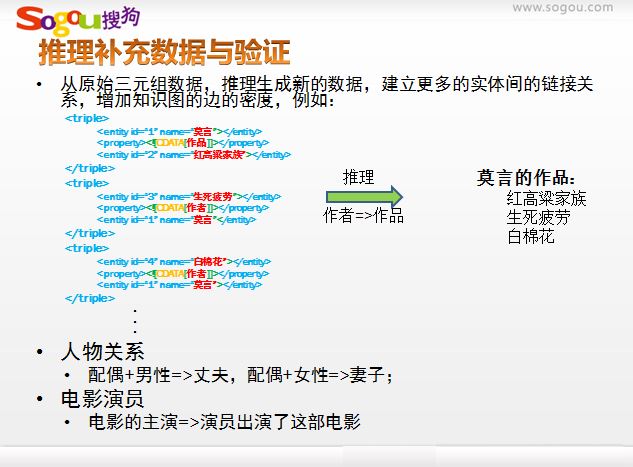
包括知識獲取和知識融合兩方面。知識獲取是從開放網頁、線上百科和核心詞庫等資料中抽取概念、實體、屬性和關係;只是融合的主要目的是實現知識的時序融合和多資料來源融合。在完成知識庫構建工作後得到的知識是顯式的知識。
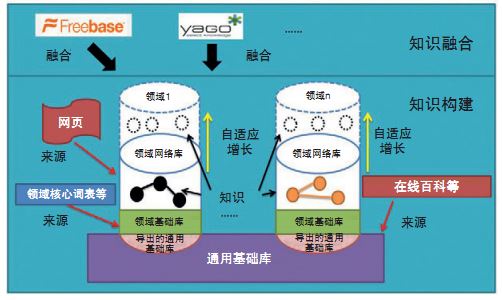
除了顯示的知識,通過OpenKN的知識計算功能,包括屬性計算、關係計算、例項計算等,我們還可以進一步獲得隱式的或推斷的知識。
知識驗證和處理:
為了檢驗顯示知識和隱式知識的完備性、相關性和一致性,我們需要對知識進行校驗,這成為知識驗證過程。主要是專家或特定的知識計算方法檢查冗餘的、衝突的、矛盾的或不完整的知識。
知識儲存:
經過驗證的海量知識,在OpenKN裡儲存在一個基於圖的資料庫(Graph DataBase, GDB)及關聯式資料庫中。其中GDB中儲存的是顯示知識,關聯式資料庫中儲存的是隱式知識。與傳統的資料庫模型Titan相比,GDB通過定義點和邊的圖資料模型來儲存知識,這裡的點和邊都有各自唯一的ID並且支援一系列的多值屬性。GDB描述了一個與現有的圖模型不同的異構網路,成為可演化知識網路。
OpenKN的兩個主要特徵——自適應和可演化性,即詮釋了OpenKN的“Open”含義。
(三).搜狗知立方
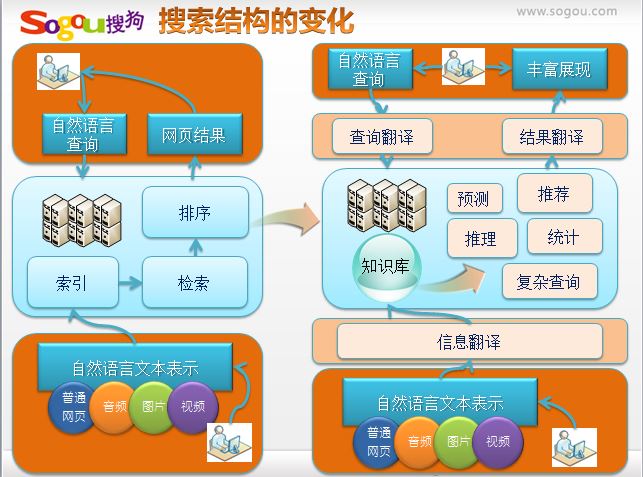
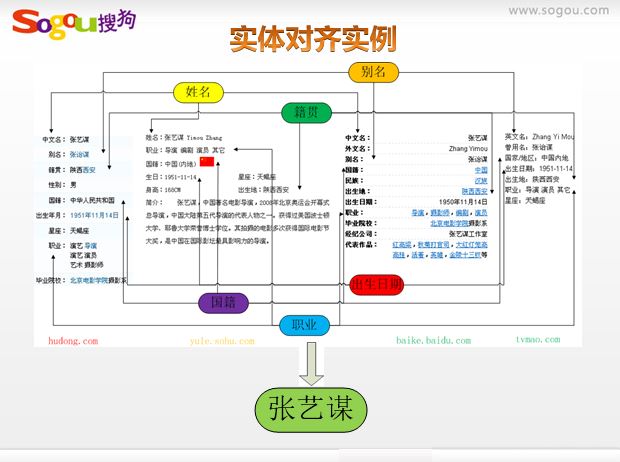
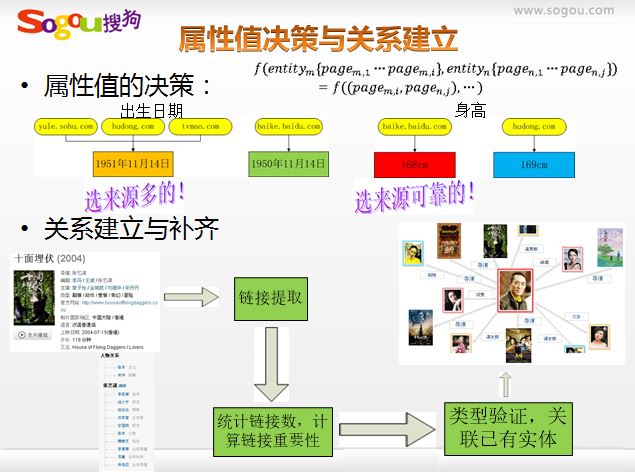
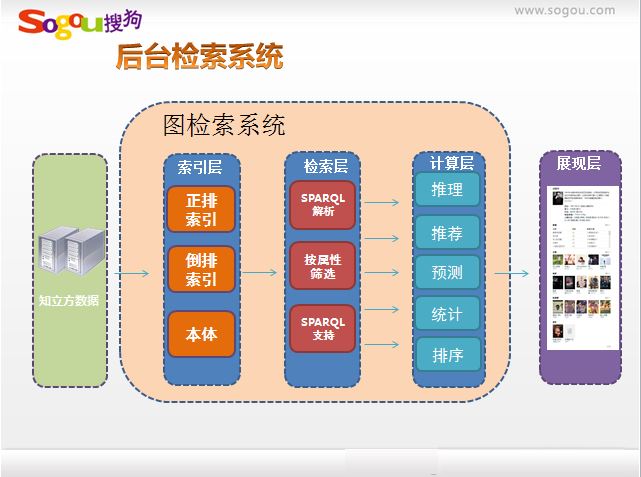
這部分內容是我在百度文庫中搜尋知識圖譜找到的,主要是張坤分享的“面向知識圖譜的搜尋技術”,關於搜狗知立方的,可惜沒聽到原作者的講述。但我也分享他的幾張圖片,一目瞭然。
第一張圖 搜尋結構發生的變化
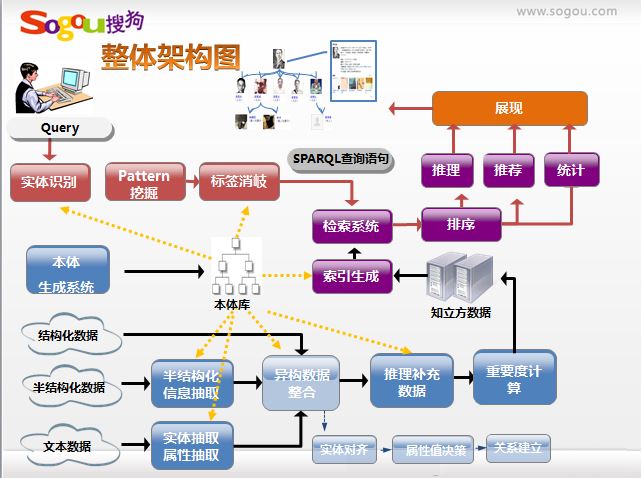
第三張圖 知識庫
比如張藝謀的國籍需要對齊“中華人民共和國”、“中國(內地)”、“中國”三個值實現屬性值對齊,“記過”、“國籍”、“國籍”實現屬性對齊;再如出生日期對齊“1951年11月14日”、“1951-11-14”、“1951-11-14”實現屬性值對齊。
總結:最後還是希望文章對你有所幫助,它主要是關於搜尋引擎和知識圖譜的一篇入門知識介紹,至少讓你明白存在這麼個東西,相當於一篇普及知識吧!如果有錯誤或不足之處,請海涵~
參考資料下載: http://download.csdn.net/detail/eastmount/8906799
參考資料如下:
1.搜尋引擎主要參考張俊林的書籍《這就是搜尋引擎》,電子工業出版社
2.曲衛華,王群. 搜尋引擎原理介紹與分析. 中國地質大學資訊工程學院
3.佘正平. 搜尋引擎原理及存在問題. 圖書情報論壇
4.張蹇. 傳統搜尋引擎與智慧搜尋引擎比較研究. 鄭州大學碩士學位論文
5.Eastmount. 知識圖譜相關會議之觀後感分享與學習總結
6.王元卓, 賈巖濤, 趙澤亞, 程學旗. OpenKN——網路大資料時代的知識計算引擎. 中科院計算機研究所
7.張坤. 面向知識圖譜的搜尋技術. 百度文庫
(By:Eastmount 2015-7-16 晚上8點 http://blog.csdn.net/eastmount/)
相關文章
- 知識圖譜——搜尋引擎的未來
- NumPy基礎知識圖譜
- 騰訊音樂知識圖譜搜尋實踐
- 堆疊、佇列、樹、圖、搜尋 基礎知識佇列
- 知識圖譜 KnowledgeGraph基礎解析
- 搜尋歷史、推理未來:時序知識圖譜上的兩階段推理
- 大眾點評搜尋基於知識圖譜的深度學習排序實踐深度學習排序
- 前端基礎技術知識講解-面試圖譜前端面試
- 面試圖譜:前端基礎技術知識講解面試前端
- 致新手:先了解搜尋引擎知識 再做SEO
- 知識圖譜的器與用(一):百萬級知識圖譜實時視覺化引擎視覺化
- 搜尋引擎工作的基礎流程與原理
- 認識搜尋引擎 ElasticsearchElasticsearch
- KGB知識圖譜透過智慧搜尋提升金融行業分析能力行業
- 知識圖譜|知識圖譜的典型應用
- 知識圖譜01:知識圖譜的定義
- 圖資料和知識圖譜,數字化轉型的新引擎
- 47_初識搜尋引擎_search api的基礎語法介紹API
- 知識圖譜學習記錄--知識圖譜概述
- 【預研】搜尋引擎基礎——inverted index(倒排索引)Index索引
- 以圖搜圖三大搜尋引擎:Google圖片、TinEye、百度識圖Go
- 構建高效能分散式搜尋引擎(Wcf-基礎篇)一薦分散式
- 知識圖譜之知識表示
- go 知識圖譜Go
- OI知識圖譜
- 搜尋引擎-03-搜尋引擎原理
- 分散式搜尋引擎Elasticsearch基礎入門學習分散式Elasticsearch
- 程式設計師的基礎生存技能:搜尋引擎程式設計師
- 57_初識搜尋引擎_分散式搜尋引擎核心解密之query phase分散式解密
- 解析Graph Search:基於社交圖譜的多維搜尋
- Solr搜尋基礎Solr
- 48_初識搜尋引擎_快速上機動手實戰Query DSL搜尋語法
- Nebula 基於 ElasticSearch 的全文搜尋引擎的文字搜尋Elasticsearch
- 圖解 IP 基礎知識!圖解
- 圖形學基礎知識
- Java基礎知識篇05——方法Java
- 56_初識搜尋引擎_核心級知識點之doc value初步探秘
- Mac上神奇的內建搜尋引擎——Spotlight(聚焦搜尋)Mac