阿里電話面試之所做所得所感(2015年7月)
真不敢想象以後成為一名IT男後,每天過著忙碌的上下班擠地鐵的生活,晚上回到房間卻獨守空房,異地他鄉的我將如何面對?是啊,很多時候我們的生活都是匆匆忙忙的,都不知道自己到底在做什麼!其實正如TED中所言“Stop,Look,Go”,有時候停下來,靜靜看看思考,感受生活,再繼續前行。同樣,面試也是一樣,我期望每次面試後都能Stop下來,思考總結,再繼續準備下一次面試。
一. 面試起因
1.面試起因
說起參加阿里巴巴這次內推過程挺有意思的,起因是我在CSDN寫了一篇關於知識圖譜的文章:知識圖譜相關會議之觀後感分享與學習總結,然後有位大哥發私信給我,希望以後多交流並交換了聯絡方式。後來我們通過QQ成為來了好友,當看到我QQ頭像時他驚了個呆(如下圖)。在簡單交流之後他問我:“在哪裡高就?”我說:“今年正準備找工作,研一剛完。”他說:“你想試試淘寶內推嗎?”我說:“好啊!”
因為我導師的研究方向是資料探勘和自然語言處理,同時畢業設計在做知識圖譜和實體對齊相關的研究,自己對這部分挺感興趣的,所以申請了“演算法工程師”這個職位。
2.職位描述
演算法工程師:自然語言處理(NLP)、影象處理、語音識別、機器學習、分散式並行演算法、資料探勘、推薦搜尋、複雜網路、深度學習、廣告、機器翻譯崗位描述:如何從海量商品中找到最合適的商品、推薦和搜尋系統、如何讓賣家的商品達到最精確的人群而願意購買、智慧手機、強大雲作業系統、商品供應鏈等
崗位要求:對資料敏感、數學建模、至少會一門程式語言、R語言、機器學習、NLP、影象處理、海量資料處理MapReduce等
簡述阿里搜尋技術:HBase叢集、搜尋引擎、資源動態管理、大規模個性化搜尋、意圖預測、阿里知識圖譜(使用者/商品多維關係和特色標籤用於搜尋推薦)、個性化搜尋(建立使用者Profile、興趣圖譜、關係儲存)、文字挖掘技術(分詞系統、語義分析、特色標籤分析和挖掘)、最大CDN系統、資料庫系統、阿里雲、淘寶檔案系統TFS、Tair、LVS負載均衡等
二. 面試準備
由於參加這個面試很突然,本打算先回家兩週陪陪父母,再回來好好準備面試的。而且7月8日我剛考過科目四拿到駕照,7月9日參加畢業開題答辯,7月10日早上10點電話面試,所以準備時間僅僅半天了(6小時),晚上還打了三把dota,哎!我主要準備如下基礎東西,而《程式設計之美》、《劍指offer》也還未閱讀,但也希望對你有所幫助吧!
1.資料庫
說到面試,經常問的資料庫問題就是索引。我準備的問題如下:題1:資料庫中的索引採用什麼資料結構?請簡述。
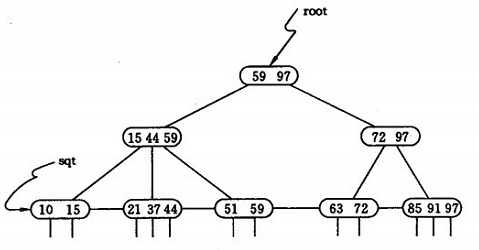
索引(index)是一種排序資料結構,為了提高在屬性A上查詢具有某個特定值的元組的效率,其中Movies(id,name,year,actor)一張電影表的屬性就是裡面的四個值。它是一棵二叉查詢樹的鍵值對,大型關係的索引實現技術是DBMS實現最重要的核心問題。
索引通常使用B樹和B+樹的資料結構,以協助快速查詢、更新資料表中的資料。
eg: select * from Movies where name='A' and year=1990;
當關系很大時,查詢代價太高。若10000個元組需要條件逐個測試,此時可以在Movies和name、year屬性上建立索引。
create index keyIndex on Movies(name,year)
詳細參考文章:淺談MySQL索引背後的資料結構及演算法-量子恆道
如輝仔的文章"資料庫索引的實現原理"所述,下圖展示了一種可能的索引方式。
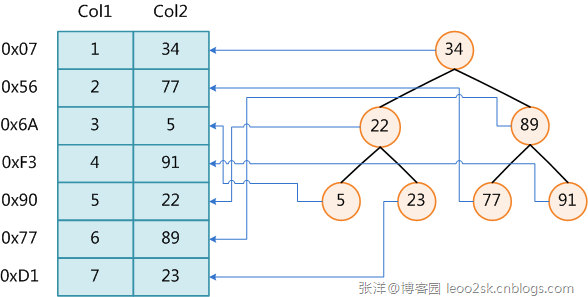
B+樹也通常用來做檔案索引和檔案系統。它的概念如下:參考《資料結構》
(1) 有n棵子樹的結點中含有n個關鍵碼
(2) 所有葉子結點中包含了全部關鍵碼的資訊,及指向含有這些關鍵碼記錄的指標
(3) 葉子結點本身依關鍵碼自小而大的順序連結
(4) 所有非終端結點可看成索引部分,結點中僅含其子樹根結點中最大或最小關鍵碼
重點:索引為什麼用B+樹就能加快資料檢索速度?
強推:B-樹和B+樹的應用:資料搜尋和資料庫索引
索引是對資料庫表中一個或多個列的值進行排序的結構。與在表中搜尋所有的行相比,索引用指標指向儲存在表中指定列的資料值,然後根據指定的次序排列這些指標,有助於更快地獲取資訊。
通常情況下,只有當經常查詢索引列中的資料時,才需要在表上建立索引。索引將佔用磁碟空間,並且影響數 據更新的速度。但是在多數情況下 ,索引所帶來的資料檢索速度優勢大大超過它的不足之處。
二叉查詢樹進化品種的紅黑樹等資料結構也可以用來實現索引,但是檔案系統及資料庫系統普遍採用B-/+Tree作為索引結構。
一般來說,索引本身也很大,不可能全部儲存在記憶體中,因此索引往往以索引檔案的形式儲存的磁碟上。這樣的話,索引查詢過程中就要產生磁碟I/O消耗,相對於記憶體存取,I/O存取的消耗要高几個數量級,所以評價一個資料結構作為索引的優劣最重要的指標就是在查詢過程中磁碟I/O操作次數的漸進複雜度。換句話說,索引的結構組織要儘量減少查詢過程中磁碟I/O的存取次數。為什麼使用B-/+Tree,還跟磁碟存取原理有關。
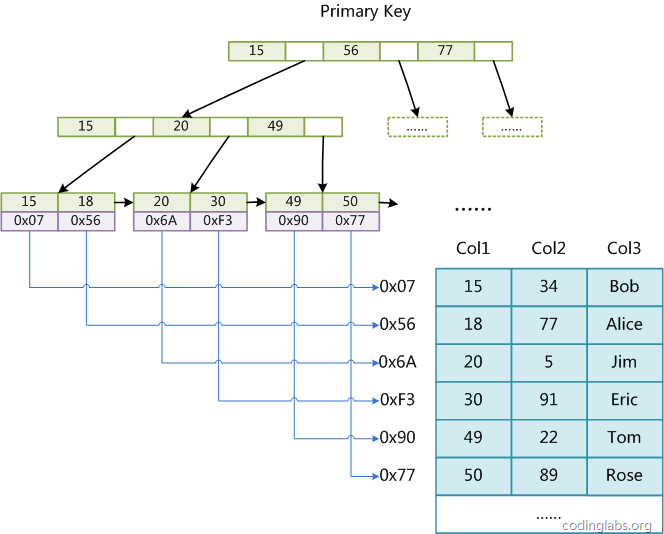
同時索引的缺點也存在,如建立、維護索引耗時,佔物理空間、增刪改查維護。在建立索引時應該考慮哪些列(屬性)加索引,更方便搜尋。
題2:SQL語句(insert\delete\update\select)、事務(rollback\commit)、ACID性質、儲存過程(已經執行過,不需再次編譯)、觸發器(trigger)、BCNF、SQL隱碼攻擊('or'='or')這些基礎知識因為當初學得還行,所以就沒再看了,也沒時間了。
但你應該準備下,尤其是筆試。
2.資料結構
資料結構我也簡單過目了下,首先回顧了當初經常問的一個問題"題3"。題3:陣列和連結串列各自的優缺點?
簡述如下:
(1)陣列:固定長度,減小記憶體浪費,方便遍歷(通過下標存取),刪除操作後面依次前移,插入操作依次後移,可能遇到超出原定義陣列大小,棧分配空間。
(2)連結串列:動態分配儲存,方便增減\插入\刪除操作、遍歷通過指標依次進行,堆分配空間。
題4:二叉樹是個什麼鬼?平衡二叉樹又是什麼?
二叉樹主要性質包括:(1)每個結點至多隻有兩棵子樹(不存在度>2的結點)
(2)有左右之分,其次序不能任意顛倒
當時沒時間只能回顧概念了,更多二叉樹程式碼強推:輕鬆搞定面試中的二叉樹題目
二叉排序樹、平衡二叉樹簡述之:
(1)左子樹!=空,左子樹上結點<根
(2)右子樹!=空,右子樹上結點>根
雜湊表中的元素是由雜湊函式確定的,對映關係。常見雜湊函式:
直接地址法: H(key)=key 或 H(key)=a·key+b
除留餘數法: H(key)=key MOD p,p<=m
eg: H(key)=key+(-1948) 年份作為關鍵字加上一個常數。
雜湊表:
地址 01 02 03 04
年份 1949 1950 1951 1952
人口 ... ... ... ...
建立雜湊表需要考慮時間、關鍵字長度、雜湊表大小、分佈頻率等。
常用的處理衝突方法包括:
(1)開發地址法
開放地址法有一個公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1),其中m為雜湊表的長度、di是產生衝突的增量序列。
如果di值可能為1,2,3,...m-1稱為線性探測再雜湊。如果di=1表示每次衝突後向後移動1個位置,還有二次探測再雜湊和隨機探測再雜湊(di為隨機數列)。
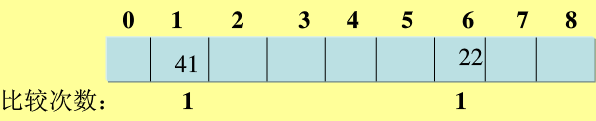
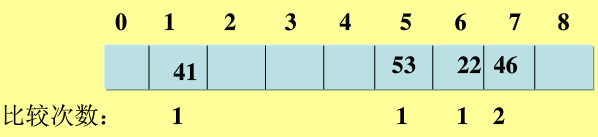
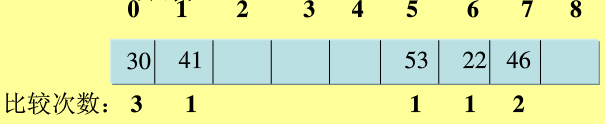
eg: 對給定數列{22,41,53,46,30,13,1,67}建立雜湊表,表長取9,即[0-8]。雜湊函式設定為H(key)=key MOD 8,用線性探測解決衝突Hi=(H(key)+di) MOD m,di=1,2,3,...m-1。(參考百度文庫)
解:取22,計算H(22)=22 mod 8 =6,該地址為空,可用:

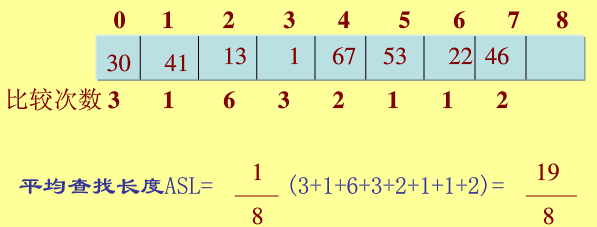
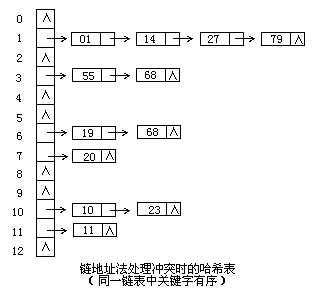
(3)連結地址發
將所有關鍵字為同義詞的記錄儲存在同一線性連結串列中。
題6:圖相關知識。最小生成樹普里姆演算法、最短路徑Dijkstra演算法、Floyd演算法。
PS: 前些天無聊百度了下圖靈獎獲得者,確實都是些大牛啊!那些XXX演算法和XX語言的發明者基本都是其中的成員之一。1978年弗洛伊德圖靈獎獲得者,Floyd-Warshall演算法創始人,但他同時也是堆排序演算法、前後斷言法的創始人。
3.設計模式
據說可能會問到你熟悉的一個設計模式或專案中使用過的一個設計模式。題7:簡述你熟悉的一種設計模式或專案中用過的設計模式。
代理模式:參考自己的部落格"設計模式之代理模式"
其產生原因是有些物件由於某些原因,如物件開銷太大、安全保護、遠端訪問等,直接訪問會給使用者或系統帶來很多麻煩,所以通過在訪問此物件時新增一個對此物件的訪問層——代理。如:購買火車票的代售點、銀行交易的支付寶等。
代理模式(Proxy Pattern)給某個物件提供一個代理,並由代理物件控制原物件的引用。簡言之,一個物件不想或不能直接引用一個物件,可通過”代理“第三者來間接引用,代理物件在客戶端和目標物件之間起到中介作用。
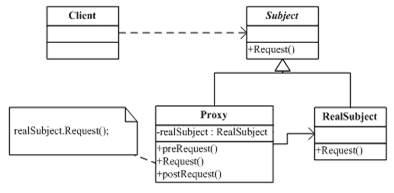
實際應用:在瀏覽海量圖片時,我看可以使用代理模型,其大圖片對應的縮圖就相當於Proxy,當使用者喜歡某張具體的圖片,點選後在顯示具體的大圖。否則都顯示大圖非常浪費資源、記憶體等。
優點:不讓客戶直接對物件進行操作,代理可起到保護作用、代理可設定必要的判斷、減少系統資源的消耗,對系統進行優化並提高執行速度。
題8:簡述設計模式的五大原則。
參考我的文章"設計模式之SOLID原則再回首",主要包括:
(1) 單一職責原則(Modem,一個類只幹一件事撥號\掛機、傳送\接受請求)
(2) 開閉原則(增加新功能,原有功能程式碼關閉,如計算器運算類,子類加法類、減法類)
(3) 里氏替換原則(企鵝繼承鳥,但企鵝不會飛,使用父類也適用於子類)
(4) 介面隔離原則(多個和客戶相關的介面要好於一個通用介面)
(5) 依賴倒置原則(高層次模組不應該依賴於低層次的模組,二者都應該依賴於抽象)
設計模式的核心思想是通過增加抽象層,把變化部分從不變化部分分離出來。
題9:請簡述工廠模式和抽象工廠模式優缺點。
這個就沒有深入看了,它們是很常用的兩種設計模式。
4.計算機網路
題10:請簡述計算機網路的五層協議。下圖非常重要,就圍繞它們講即可。
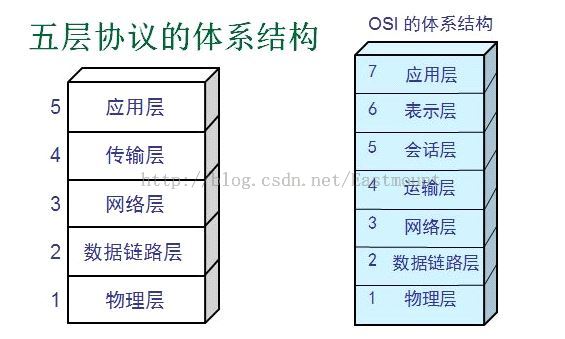
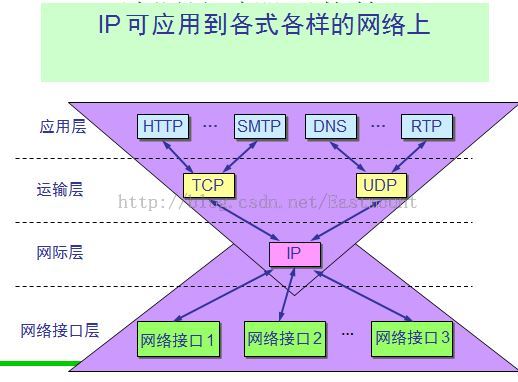
如下圖所示,簡單打個比方:
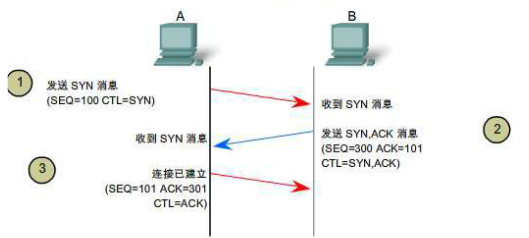
(1)A發請求資料包:"我想發資料給你,可以嗎?"第一次對話
(2)B傳送同意連線,要求同步"可以,你什麼時候發?"第二次對話
(3)A再發一個確認主機B的要求"我現在就發,你接著吧"第三次對話
經過三次對話後,主機A向主機B傳送資料。
因為我自己做過很多C#相關套接字的客戶端/伺服器通訊的程式(你可能不會遇到這種問題),所以自己也準備了這個相關知識點。Socket套接字包括IP地址、主機、Tcp協議,bind方法繫結埠、listen方法監聽埠、accept接收請求、connect請求連結、send方法傳送、receive方法接收、close關閉連線、shutdown停止監聽。這就是整個通訊的簡單過程。
詳見:C# 網路程式設計之套接字程式設計基礎知識
題13:TCP和UDP的區別。
(1)TCP:傳輸控制協議、基於連線、可靠連線、安全
(2)UDP:使用者資料包協議、面向非連線、不與對方建立連線、速度快
5.搜尋引擎和推薦系統
因為我面試的是搜尋部門,所以還是需要知道搜尋相關的一些知識。同時很多面試還是會簡單問問搜素相關的內容,可能對你有用。題14:請簡述搜尋引擎如何實現的?
通過《這就是搜尋引擎——張俊林》這本書的一張圖即可簡單敘述。
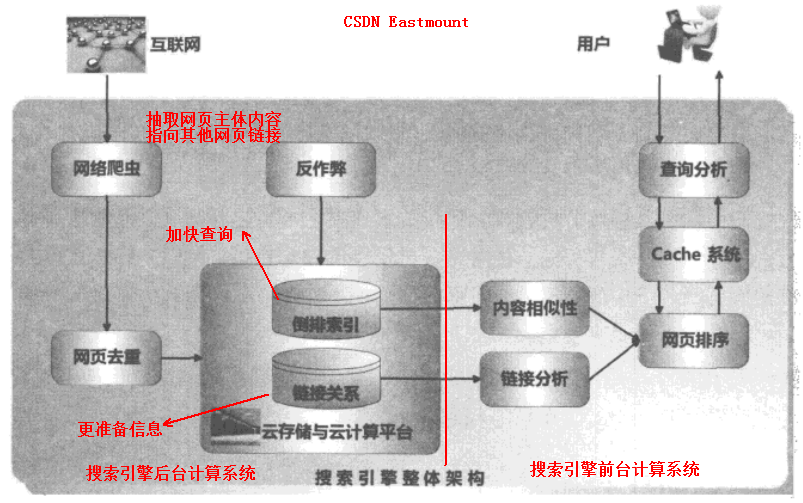
從網際網路中抽取網頁內容及指向其他頁面的連結,因為網際網路中有相當比例的內容是完全相同或近似重複的,網頁去重模組就是做出檢測並去掉重複內容。之後網頁內容通過倒排索引這種高效查詢資料結構來儲存,而網頁連結關係也會儲存,因為連結分析可幫助使用者獲取更準確的搜尋結果。
由於網頁數量太多,同時需要儲存一些中間的處理結果,Google提供的雲端儲存與雲端計算,使用數以萬計的普通PC作為海量資訊搜尋引擎,它成為了搜尋引擎的基礎支撐。
搜尋引擎前臺:
當搜尋引擎接受到使用者的查詢詞後,首先對查詢詞進行分析,希望能夠能夠結合查詢詞和使用者資訊來正確推導使用者的真正搜尋意圖。
先在快取中查詢,搜尋引擎的快取中儲存了不同的查詢意圖對應的搜尋結果,如果存在則直接返回,即節省資源又加快響應速度;如果沒有找到則呼叫網頁排序模組,根據使用者查詢實時計算哪些網頁滿足使用者資訊需求,並排序輸出作為搜尋結果。兩個參考因素:內容相似性和連結分析。
PageRank連結分析提高了搜尋質量,它帝歸每個網頁節點的得分,直到穩定。
題15:推薦系統相關的知識。
(PS:這部分研究較少,只能紙上談兵,後面面試中會講到)
分為三大模組:使用者建模模組、推薦物件模組和推薦演算法模組。
使用者建模模組根據使用者偏好,TF-IDF演算法。
推薦物件模組根據推薦物件特徵提取,每個推薦特徵的影響、是否自動更新等,SVM分類演算法,例如音樂推薦。
推薦演算法模組是最核心、關鍵的模組。(1)基於內容的推薦方法,如音樂共性、興趣點,根據推薦物件內容特徵和使用者模型興趣特徵計算相似性,最簡單的就是餘弦距離計算方法。(2)協同過濾推薦,如郵件系統、書籍,自己身邊朋友都選擇購買,自己很大概率也會購買。
個性化推薦系統,根據使用者的資訊需求、興趣將感興趣的產品推薦給使用者。海量推薦如何更準?
題16:關於淘寶搜尋相關知識。
此次強烈推薦閱讀《你在淘寶上買了一件東西》這篇文章,也可以通過我的部落格閱讀這個故事。連結如下:
《淘寶技術這十年》讀書筆記 (一).淘寶網技術簡介及來源
簡單敘述過程如下:
DNS伺服器,先把taobao.com轉成IP
不同網路轉換不一樣,就會涉及到負載均衡找到一個更快的IP入口
此時產生一個PV頁面訪問量
訪問生成頁面分配給其中一臺Server,涉及到公平公正平均,LVS負載均衡完成
邏輯運算和資料處理後,淘寶網首頁HTML內容生成
瀏覽器載入CSS、JS、圖片、指令碼、檔案資源
資源分佈多個域名,瀏覽器同一個域名併發載入數量有限
CDN內容分發網路分配到最近結點(全國各地),保證淘寶訪問海量資料的速度仍然未減慢
CDN同步共用,TFS淘寶分散式檔案系統
載入完首頁後,搜尋框中輸入:毛衣,產生一個PV
分詞處理(中文"學生"字單位,英文"student"詞單位)
搜尋購物意圖分析
交易記錄、搜尋記錄日誌記錄,作為後續資料分析
根據使用者的意圖推薦產品
6.海量資料處理
大家都知道我會強推July的文章:教你如何迅速秒殺掉:99%的海量資料處理面試題
題18:(騰訊)在40億個海量資料中如何判斷一個是否存在?
申請512M記憶體,一個bit位代表一個unsigned int值,讀40億個數,設定相應bit位,讀入要查詢位,檢視bit是否為1,若為1表示存在否則表示不存在。
題19:海量資料處理。
簡述July的處理方法。
時間:Bloom filter、Hash、bit-map、堆、倒排索引
空間:分而治之、hash對映
叢集:分散式、平行計算
例:300萬個查詢字串中統計最熱門的10個查詢
若10億個則先劃分小,1000個小檔案中,再hashmap通過數量,歸併top10,而該題資料300萬較小,古記憶體中處理,HashTable+堆實現<key,value>對應<字串,次數>的top10獲取。
7.NLP和LTR
題20:請簡述機器學習、NLP、LTR相關知識。(自己相關)
傳統是按照指令一步一步執行,而機器學習不接受輸入的指令,只接受輸入的資料。例如:小Y約會經常遲到,預測這次會不會遲到。它會根據已有的資料(經驗)訓練出模型,在輸入新的資料進行預測未知屬性。再如NG教授說的根據線性迴歸預測某個點房屋大小的房價、預測腫瘤是否良性等。
推薦資料:機器學習科普文章:“一文讀懂機器學習,大資料/自然語言處理/演算法全有了”
資料探勘=機器學習+資料庫
NLP=機器學習+文字處理
計算機視覺=機器學習+影象處理,例如手寫識別字
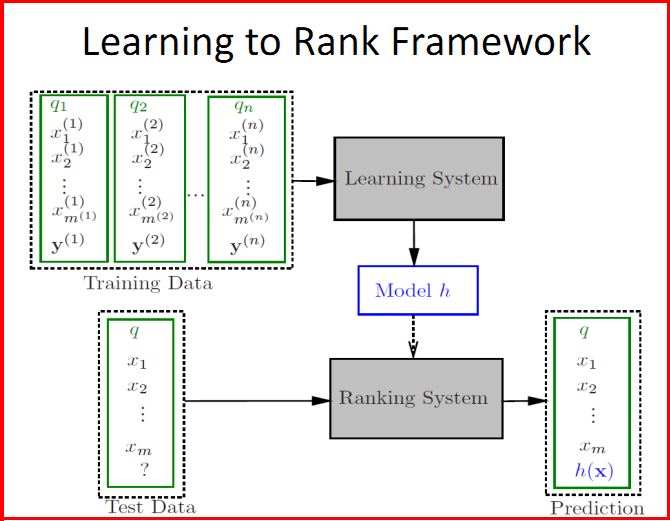
LTR如下圖所示,推薦文章:機器學習排序之Learning to Rank簡單介紹
三. 面試過程
PS:由於準備時間只有6個小時,中間還打了幾把dota2,所以準備的東西就只有這些了。然而這些東西回過頭來看並沒有什麼用,其實就相當於和麵試官進行了一場”裸聊“吧!但對我的收穫還是非常大,非常感謝他和推薦人,謝謝!OK,劇情開始。
時間:2015年7月10日早上10點半
地點:某某大學計算機實驗室四層樓梯
場景:屋外暑假裝修”轟隆隆“的施工聲
準備:我早上9點起的床,擔心錯過阿里的電話(確實阿里昨天約好的10點半,非常準時),來到了實驗室,同時簡單的看了些以前寫過的部落格,因為在簡歷中我簡單提到了我個人喜歡分享,寫了2年多的部落格,所以簡單過了幾篇。快到10點半的時候,去到了樓梯處,手裡拿著我自己的一份簡歷,因為他肯定會問你簡歷相關的內容。同時由於暑假學校很多裝修施工,屋外非常吵,我也沒有換個地方,距離太遠。
強烈建議你自己面試時找個安靜的地方,一個是自己不被影響,另一個是對面試官的尊重吧!他也能聽清楚。
過程:
10點30分 電話響起,是杭州來的電話。
面試官:您好!我是淘寶搜尋部門的面試官,請問您是XXX,對吧!
作者:您好!我是學生XXX。
面試官:我看了你的簡歷,你是做過LTR相關的專案,對吧!
點評:所以說前面我準備的很多都沒有什麼用,面試官上來就會直接問你所投部門和相關專業的知識,而不是基礎知識,因為他可能預設你已經會了吧,這第一次面試也讓我認識到了這點。但是如果你想參加筆試或者面試實習,你非常有可能會遇到上面我所準備的基礎問題,再或者有可能你的面試就會遇到,看看也並沒什麼錯!
作者:對,我們課程做過這方面的大作業。
面試官:那你能簡單說說LTR你們是怎麼做的嗎?
作者:Learning To Rank學習排序,隨著海量資料規模越來越大,傳統的搜尋引擎是通過使用者輸入的關鍵字,獲取相關內容和連結分析作一個結果排序,返回給使用者。而隨著特徵越來越多,好像Google現在就200多個特徵了,PageRank就是其中一個特徵,就考慮把機器學習的方法應用在搜尋中。LTR首先通過訓練資料集得到一個模型,再通過這個模型去預測新的資料。它主要分為三種,一個是基於點的Pointwise演算法、一個是基於對的Pairwise演算法、還有一個是基於列的Listwise演算法。
面試官:那它的資料集是怎樣的?怎樣評價其結果?
作者:我們採用的資料集是微軟提供的,共136個特徵,其中第一列表示查詢label,第二列對於qid查詢id,緊接著是136維特徵,最後是輸出是一個評價等級。比如有5個等級0-4,其中4表示perfect完全相關,0表示完全不相關,就是預測結果看它屬於什麼等級。
面試官:你還沒有自我介紹,你先做個自我介紹吧!
作者:好的!我叫XXX,來自XXX大學.....現在導師的研究方向是資料探勘和自然語言處理相關的。我希望去到一家好的公司紮紮實實工作幾年,然後回到自己的家鄉貴州去當一名大學程式設計老師,因為父母都是老師,一直都想成為一名老師。
點評:由於這是第一次面試,自我介紹準備得也很倉促。我有幾個疑問與君共勉,希望有心之人能解惑。
1.第一個是我自我介紹時忘記強調我擅長什麼,做過的東西都是課程相關的,一個好的自我介紹應該如何準備?
2.第二個是我說出了自己以後的想成為一名老師,是否不應該說出來?
3.第三個就是最後忘記問面試官的姓名了,是否應該詢問?
面試官:你Pointwise採用的是什麼演算法?請詳細說說。
作者:我們採用PRank演算法實現的,它是一種迴歸的演算法。它存在一個打分函式,就是那136維特徵和對應特徵值的乘積加和,其結果是一個分數。然後五個等級,每個有一個閾值,通過這個得分和閾值比較可以判斷其屬於哪個label等級。
面試官:你是直接通過這個得分與閾值進行比較嗎?那閾值怎麼確定?
作者:對了!我們需要先訓練一個得出一個模型,這裡就相當於先把閾值訓練出來,再用這個閾值去預測。
面試官:對,先有個訓練的過程,那你Pairwise採用什麼演算法?
作者:Pointwise是基於對的學習排序,我們採用的是RankNet演算法實現的,它是基於神經網路的一個演算法。它作個交叉熵,然後在梯度下降迭代直到求最優結果。
面試官:那你們那個損失函式是什麼?
作者:我有些忘了這部分,損失函式好像主要讓它的誤差越來越小。
面試官:簡單說說它們各自的優缺點。
作者:首先是基於點的學習排序,它是通過一個打分得到一個排序結果,比傳統的搜尋排序效果要好,但是由於它沒有考慮相互之間、兩兩之間的關係,所以提出了基於對的方法。基於對的方法又沒有考慮查詢之間的順序、同時有些查詢結果差異很大,所以提出了基於列的方法。
面試官:那你們的結果是怎樣呢?那個好?
作者:我們採用五個效能指標進行了評價,具體是什麼我有些忘了(MAP、NDCG@5),結果是基於對和基於列的好於Pointwise。
面試官:資料集規模有多大?測試資料和訓練資料規模分別多大?
作者:資料規模大的有1G左右,小的幾百兆資料;同時我們要求是是在IBM的SuperVessel雲平臺下實現分散式運算,採用MapReduce實現的。我們一個四個同學,我和另一個同學研究演算法,另外兩個同學做分散式那塊。
面試官:你的資料量也不大,資料集是哪來的?採用的是Python開發嗎?
作者:資料集是微軟研究院提供的,LTR常用的一個資料集,一個46維一個136維。我們採用的是Java實現的。
面試官:看你的簡歷,你是去IBM實習過嗎?
作者:沒有,我沒去實習過。我們就是和IBM一起做了基於雲平臺下的一個應用,這是我們課程《高階軟體工程》的大作業,IBM主要負責提供這個平臺,包括Spark、MapReduce。
面試官:你們當時做這個簡單來說就是IBM提供了一個雲平臺,但是其他公司也有很多雲平臺。
作者:對啊!其它公司也有,但是這是一個相當於公司和學校之間的一個學習合作吧。主要是讓我們感受下分散式、LTR等前沿的知識。
面試官:你們有沒有想過有的特徵值的屬性權重很小,把它刪除的創新呢?
作者:沒有考慮這個。你說這個問題確實存在,我們在做的是否,尤其是PRank演算法,如果有的資料集中某個特徵值很大,其他的值很想,整個結果都是被它影響。但我們當時由於時間比較緊,沒做這方面的創新。
面試官:LTR現在我們已經在用了,特徵值比你說的那個200多個大很多。那你們有沒有遇到什麼難點?
作者:哇啊,居然已經被應用了。我都不知道,只是以為還在學術中。我們當時遇到兩個難點,一個是以前沒有怎麼學過機器學習這部分,現在需要學習這部分的演算法並實現;另外一個是因為要求是基於分散式的,所以我寫完演算法如何與其他同學合作,讓他明白演算法怎麼實現,轉換成分散式的處理。
點評:寫到這裡,幾個關鍵的東西呼之欲出。
1.面試官沒有問我擅長什麼語言,因為你申請的職位都會預設相關的技術和語言,很顯然我這部分就是Python相關。
2.我的簡歷中寫了8個專案,其它的包括Android、C#、MFC、PHP、C++等,但面試官只問了LTR(機器學習、自然語言處理、資料探勘)相關,因為他只關心自己需要的這部分內容。
3.你需要非常仔細的準備簡歷中的非常相關部分的專案,而且是深度剖析,他會問得很詳細很深,同時考慮一些創新點。
4.面試官真的很懂技術,因為你的簡歷會推薦到和你申請職位一致的人員給你面試。
面試官:看你的簡歷和部落格,你做C#比較多,但是C#這塊很少用在自然語言處理。
作者:以前因為本科各個方面都進行了學習,大三暑假自學了C#網路程式設計,後來又學了Android,我的部落格主要都是根據我所做過的專案或作業寫的。現在我在學Python這塊做自然語言處理。
面試官:喔。Python做這塊就沒什麼問題,那你會不會Linux下程式設計?
作者:我不會Linux,沒研究過,最近也準備學習。
面試官:Linux基本的命名行知道嗎?
作者:我沒研究過,不知道。(如果知道,面試官肯定會問相關的命令,確實應該學!)
面試官:那你有沒有出去實習過?
作者:我沒有出去實習過,大一的時候去過大連東軟學習了半個月。
面試官:看了你的簡歷,你做NLP這塊還是非常少,沒有跟著老師或去公司做過相關的嗎?
作者:因為我們大一的課程比較多,需要把所有的課程上完。包括我寫的部落格基本都是課程專案和自學相關的內容,所以自然語言處理和資料探勘這部分還在學習中。其實我一直都想去到企業紮紮實實學習,找個師傅跟著他學,現在是廣度的學習,到了企業找個那個方向再向深度學習。
面試官:首先你說的那個挺好,但是你要知道企業需要的是創造價值的人,當然這裡也有很多的學習機會,但是更多時間是讓你去創造價值。包括你說你五年十年後去當老師挺好的,但是現在你能為我們做些什麼?
點評:確實!企業是需要尋找為其創造價值的人才。寫到這裡我彷彿認識到了“現實很殘酷”的道理。
1.如果有機會,你還是應該學習Linux下的命令列程式設計,這是一個走向吧!
2.去到一個公司實習,尤其是做你將來需要申請職位相關的專案非常重要;但我更多的看到的是實習測試、運維這些,自己斟酌吧!
3.我一直的想法都非常的單純:“在校期間多學些東西,從廣度上發展,養成良好的自學能力;將來到企業擁有這種學習能力再深入學習自己所在職位的知識,學到精通;工作5-10年之後,或者再讀個博士或者直接回到貴州家鄉當一名大學老師,教授程式設計及分享部落格。”但顯然這是不夠的,所以接下來我也需要沉下心來深度學習一段時間。但我的夢想永遠都不會被敲碎的,正如《當幸福來敲門》裡面的一句話”那些沒有成才的人總會說你也不能成才,有夢想就要學會保護它“。
面試官:你今年研究生大二上完,開學大三嗎?
作者:我今年大一剛完,來年上大二。
面試官:看你導師是自然語言處理相關的,你簡述說下分詞?
作者:我只能說說我簡單對它的理解吧!分詞是以字分的。
面試官:分詞不一定是按字分的,不同種類分法不同的。
作者:恩。比如現在我在淘寶輸入框中輸入“I am a student”這句英文是根據word詞進行劃分,分為"I"、"am"、"a"和"student",而輸入中文“我是一個學生”,它分為"學"+"生",那麼"學生"如何判斷它是一個名詞短語呢?
面試官:你說的是個研究這塊大學生都知道,但具體怎麼實現呢?怎樣把"學生"連在一起呢?
作者:這部分我還沒有深入的研究。
面試官:你說你自然語言處理和資料探勘那塊你擅長什麼?
作者:因為這部分還在學習中,我可以說說我現在正在做的知識圖譜相關的東西嗎?
面試官:可以,我現在就在做知識圖譜這塊,那你簡單說說你現在做的這個知識圖譜吧?
作者:我現在在做的畢業設計就是旅遊知識圖譜相關的,首先是從維基百科、百度百科、互動百科、多源旅遊網站中爬取旅遊景點的資料,以前做的比較多的比如實體消歧。舉個簡單的例子吧!現在維基百科有蘋果三個頁面,一個指向蘋果公司,一個指向蘋果水果,一個指向蘋果電影,如何來判斷你需要的是具體哪個蘋果呢?就可以通過上下文如“賈伯斯”來確認它是蘋果公司。而現在我先要做的是從維基百科Infobox訊息盒中爬取旅遊景點的資訊,採用<實體,屬性,屬性值>三元組RDF儲存,比如有三個“長城”,在把這些屬性屬性值進行實體對齊、資訊融合,得到一個更豐富準確的資訊。
面試官:你採用的是什麼演算法?
作者:實體對齊準備採用CURE聚類的演算法實現,屬性對齊採用Word2Vec計算相似距離實現。
面試官:具體的演算法過程能描述下嗎?
作者:因為現在才確定方案,還沒有具體的深入研究具體的演算法過程。
面試官:你這個只是說了資料探勘那塊,但是自然語言處理那塊怎麼實現的,我不知道。換句話說,如果現在你是我的一名員工了,你覺得你能做什麼在這個部門?
作者:(其實想說知識圖譜或搜尋引擎的,我最初的想法是來到公司先學學公司一些基礎東西,從來沒有相關來到公司就開始為公司做什麼東西。感覺都需要一個學習的過程,畢竟學校和公司之間的差別還是非常大的)
面試官:如果你有一個好的演算法,創新的東西,你提出來,我們一起來研究提升現有的東西,這些都非常好。
點評:寫到這裡,確實認識到了自己很多不足,一方面NLP相關的分詞這些基礎的知識實現至少都需要了解。其次是自己學習NLP總有一種感覺:“學習游泳,在岸上觀望了很長時間,卻遲遲不敢下水。”
面試官:你有什麼問題嗎?
作者:我有兩個問題,一個是前面你提到的那個三個學習排序各自的優缺點是什麼?另一個是如何實現分詞的,我也想知道?
面試官:好的!首先是你的第一個問題,三個演算法的優缺點,你基本都回答正確的。Pointwise就是沒有考慮兩兩之間的關係,通過打分函式排序的,Pairwise而沒有考慮它們之間的順序。第二個問題分詞,最簡單的方法就是通過詞庫進行查詢,比如“學生”,相當於一個詞典,定義了很多名詞短語;也可以通過訓練模型來分詞,那如果有個“潘長江”,你如何判斷它是“潘+長江”還是人名“潘長江”呢?因為詞庫裡很少存人名。這些都是需要考慮的。你還有什麼問題嗎?
作者:沒有了,謝謝。
面試官:好的。
作者:非常感謝你告訴了我這麼多東西,因為這是我第一次參加面試有些緊張,同時也認識了很多不足,接下來學習下Linux、進行深入的學習NLP相關知識,再如在專案中應該關注一些創新點。其實我一直都覺得面試是一個相互學習的過程,我能從你那學到很多東西,你也可能從我這學到一些知識。非常感謝!
面試官:恩,對。也謝謝你的這次面試!繼續加油,掛了啊。
作者:好的,謝謝您。拜拜~
點評:你需要記住面試官會讓你提問,我也沒準備什麼好的問題,如“職業規劃”、”公司如何培養“,就問了兩個他給我提的問題,至少讓我知道更多。還是那句話,我認為面試是一個相互學習的過程,能讓我找到很多自己的不足,更清晰的看清自己的程式設計方向,同時需要保持一顆平常心去對待。
四. 面試總結
終於45分鐘的人生第一次面試結束了,內容基本與當時一致的,可能忘記一些細節和順序,自己收穫頗多。也希望對你有所幫助,同時是當時的所作所得所感吧!如果有錯誤或不足之處,還請海涵~
自己的優缺點非常明顯:
優點:
1.大學期間學得比較雜,東西比較多:C++、C#、Java、PHP、Python、NLP等;
2.學習能力比較強,至少還是懂些基礎的東西;
3.喜歡分享知識和部落格,至少做過很多的東西,雖然比起企業專案小兒科;
4.只想找個公司,紮紮實實學習工作,沒有好高騖遠,且夢想是老師。
缺點:
1.沒有去公司實習過,尤其是在公司做過NLP和資料探勘相關專案;
2.不會Linux下程式設計,Python還沒有精通;
3.自然語言處理和資料探勘、搜尋推薦相關知識沒有深入學習,但又想從事這方面;
4.沒有深入準備自己所做過的專案LTR和麵試簡歷及問題;
5.學習方面僅有廣度沒有深度,這也不一定是壞事吧。
提升:
1.準備學學Linux下程式設計,鳥哥私房菜從大一就想看,五年都過去了;
2.準備想想自己需要從事哪個方向,並深入學習下該方向知識;
3.把自己的畢設知識圖譜相關的做好,深入學習,因為與找工作也相關;
4.準備些基礎知識,包括《程式設計之美》、《劍指offer》、《面試寶典》等,因為可能會有筆試;
5.如果你有機會,建議出去公司實習,建議大公司且與自己相關的部門;
6.建議你好好準備一份簡歷,專案最好與你所投部門相關,並且自己深入瞭解細節。
最後分享最近自己看的一本書裡的一些內容,《你在忙什麼》,放平心態,工作遲早會有,夢想卻不能被敲碎。
發明機器,本想有更多的休息時間,結果人越來越累;發明手機,本想交流越來越多,結果人越來越孤獨;發明網路,本想讓人更有智慧,結果日益遲鈍。人們猜到了開始,卻猜不到結果,這是因為忽略了什麼?
一部高檔手機,70%的功能是沒用的;一款高檔轎車,70%的速度是多餘的;一屋漂亮衣物,70%是閒置沒空穿的;一生賺再多的錢,70%是留給別人花的。可見,累了一輩子,爭了一輩子,自己能用上的也不過30%,慾望滿足了也是苦。
資訊爆炸的今天,各種慾望撲面而來,每個人不僅在外面不停地忙,內心也特別忙,忙了一輩子,最後卻不知道自己到底在忙什麼。因此,尋找讓心寧靜的智慧,尤為重要。束縛你的永遠是你自己,所以解開它的,也只有靠你自己。
——索達吉堪布
相關文章
- 阿里外包電話面試阿里面試
- 接到阿里的面試電話了阿里面試
- Web 開發 17 年的所見所得Web
- 4.21 阿里電話面試問題記錄阿里面試
- 記一次阿里實習生電話面試阿里面試
- 【面試】阿里iOS開發實習電話面試記錄(一)面試阿里iOS
- 電話面試面試
- 記一次阿里電話面試| 掘金技術徵文阿里面試
- 騰訊電話面試面試
- 所得與所見:[-View周邊-] 框架層View框架
- 電話面試總結面試
- 一個前端崗位電話面試所帶來的問題的思考前端面試
- 同事有話說 | 那些所謂的敏捷儀式感敏捷
- 利用JavaScript所見即所得的生成Excel表格JavaScriptExcel
- 所按非所得——聊一聊StandHogg漏洞HOG
- 面試技巧:HR如何做好電話面試面試
- 一次電話面試題面試題
- 微軟電話面試程式設計微軟面試程式設計
- 網易金融前端實習生電話面試整理前端面試
- 所見即所得富文字編輯器實現原理
- 程式設計師面試:電話面試問答Top 50程式設計師面試
- 幾款所見即所得視覺化UML工具介紹視覺化
- 利用VC++開發所見即所得的列印程式 (轉)
- 三本學歷,自從接到阿里的面試電話後,五個月從 安卓轉前端阿里面試安卓前端
- IBM幾個電話面試問題IBM面試
- 頁面錄製服務上線:RESTful API 呼叫實現,所見所錄即所得RESTAPI
- 2015年馬雲熬過的雞湯:阿里官方公佈了這8句話阿里
- 【面試】騰訊iOS開發實習電話面試記錄(二)面試iOS
- 電感
- 所見即所得 HTML 編輯器 Froala Editor 3.1.1 破解過程HTML
- 丁香園iOS電話面試問題總結iOS面試
- 2015年電話會議、網路會議市場研究報告摘要
- [面試] 記錄一次來自 bigo 的電話面試面試Go
- 阿里2015校招面試回憶(成功拿到offer)阿里面試
- 遮蔽電感廠家科普遮蔽電感和非遮蔽電感的區別
- Hallo.js:一款所見即所得的Web編輯器JSWeb
- 花樣玩轉“所見即所得”的視覺化開發UI視覺化UI
- Wainhouse:2015年電話會議、網路會議市場研究報告摘要AI