對於小規模資料,我們可以選用時間複雜度為 O(n2) 的排序演算法。因為時間複雜度並不代表實際程式碼的執行時間,它省去了低階、係數和常數,僅代表的增長趨勢,所以在小規模資料情況下, O(n2) 的排序演算法可能會比 O(nlogn) 的排序演算法執行效率高。不過隨著資料規模增大, O(nlogn) 的排序演算法是不二選擇。本篇我們主要對 O(n2) 的排序演算法進行介紹,在介紹之前,我們先了解一下演算法特性:
-
演算法特性:
-
穩定性:經排序後,若等值元素之間的相對位置不變則為穩定排序演算法,否則為不穩定排序演算法
-
原地排序:是否藉助額外輔助空間
-
自適應性: 自適應性排序受輸入資料的影響,即最佳/平均/最差時間複雜度不等,而非自適應排序時間複雜度恆定
-
本篇我們將著重介紹插入排序,選擇排序和氣泡排序瞭解即可。
插入排序
插入排序的工作方式像整理手中的撲克牌一樣,即不斷地將每一張牌插入到其他已經有序的牌中適當的位置。
插入排序的當前索引元素左側的所有元素都是有序的:若當前索引為 i,則 [0, i - 1] 區間內的元素始終有序,這種性質被稱為迴圈不變式,即在第一次迭代、迭代過程中和迭代結束時,這種性質始終保持不變。
不過,這些有序元素的索引位置暫時不能確定,因為它們可能需要為更小的元素騰出空間而向右移動。插入排序的程式碼實現如下:
private void sort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int base = nums[i];
int j = i - 1;
while (j >= 0 && nums[j] > base) {
nums[j + 1] = nums[j--];
}
nums[j + 1] = base;
}
}
它的實現邏輯是取未排序區間中的某個元素為基準數base,將base與其左側已排序區間元素依次比較大小,並"插入"到正確位置。插入排序對部分有序(陣列中每個元素距離它的最終位置都不遠或陣列中只有幾個元素的位置不正確等情況)的陣列排序效率很高。事實上,當逆序很少或資料量不大(n2和nlogn比較接近)時,插入排序可能比其他任何排序演算法都要快,這也是一些程式語言的內建排序演算法在針對小資料量資料排序時選擇使用插入排序的原因。
演算法特性:
-
空間複雜度:O(1)
-
原地排序
-
穩定排序
-
自適應排序:當陣列為升序時,時間複雜度為 O(n);當陣列為降序時,時間複雜度為 O(n2)
希爾排序
插入排序對於大規模亂序陣列排序很慢,因為它只會交換相鄰的元素,所以元素只能一步步地從一端移動到另一端,如果最小的元素恰好在陣列的最右端,要將它移動到正確的位置需要移動 N - 1 次。
希爾排序是基於插入排序改進的排序演算法,它可以交換不相鄰的元素以對陣列的區域性進行排序,並最終用插入排序將區域性有序的陣列排序。它的思想是使陣列中間隔為 h 的元素有序(h 有序陣列),如下圖為間隔為 4 的有序陣列:
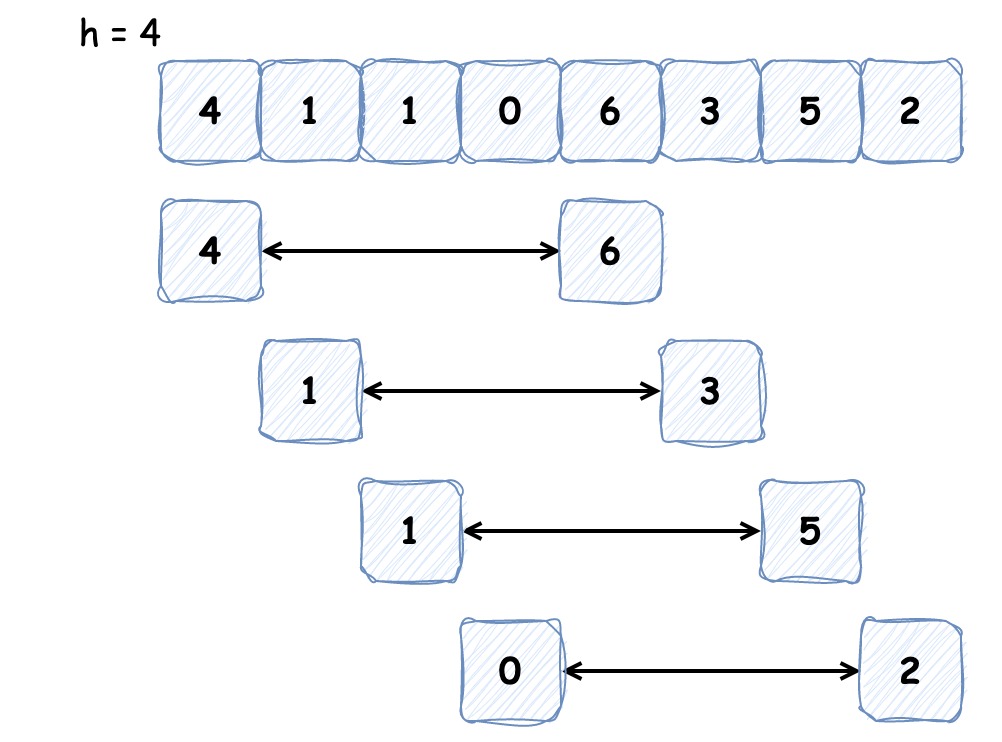
排序之初 h 較大,這樣我們能將較小的元素儘可能移動到靠近左端的位置,為實現更小的 h 有序創造便利,最後一次迴圈時 h 為 1,便是我們熟悉的插入排序。這就是希爾排序的過程,程式碼實現如下:
private void sort(int[] nums) {
int N = nums.length;
int h = 1;
while (h < N / 3) {
h = 3 * h + 1;
}
while (h >= 1) {
for (int i = h; i < N; i++) {
int base = nums[i];
int j = i - h;
while (j >= 0 && nums[j] > base) {
nums[j + h] = nums[j];
j -= h;
}
nums[j + h] = base;
}
h /= 3;
}
}
希爾排序更高效的原因是它權衡了子陣列的規模和有序性,它也可以用於大型陣列。排序之初,各個子陣列都很短,排序之後子陣列都是部分有序的,這兩種情況都很適合插入排序。
選擇排序
選擇排序的實現非常簡單:每次選擇未排序陣列中的最小值,將其放到已排序區間的末尾,程式碼實現如下:
private void sort(int[] nums) {
for (int i = 0; i < nums.length; i++) {
int min = i;
for (int j = i + 1; j < nums.length; j++) {
if (nums[j] < nums[min]) {
min = j;
}
}
swap(nums, i, min);
}
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
演算法特性:
-
空間複雜度:O(1)
-
原地排序
-
非穩定排序:會改變等值元素之間的相對位置
-
非自適應排序:最好/平均/最壞時間複雜度均為 O(n2)
氣泡排序
氣泡排序透過連續地比較與交換相鄰元素實現排序,每輪迴圈會將未被排序區間內的最大值移動到陣列的最右端,這個過程就像是氣泡從底部升到頂部一樣,程式碼實現如下:
public void sort(int[] nums) {
for (int i = nums.length - 1; i > 0; i--) {
// 沒有發生元素交換的標誌位
boolean flag = true;
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
swap(nums, j, j + 1);
flag = false;
}
}
if (flag) {
break;
}
}
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
演算法特性:
-
空間複雜度:O(1)
-
原地排序
-
穩定排序
-
自適應排序:經過最佳化後最佳時間複雜度為 O(n)
巨人的肩膀
-
《演算法導論 第三版》第 2.1 章
-
《演算法 第四版》第 2.1 章
-
《Hello 演算法》第 11 章
作者:京東物流 王奕龍
來源:京東雲開發者社群 自猿其說Tech 轉載請註明來源