承接上文
承接之前的【精華推薦 |【演算法資料結構專題】「延時佇列演算法」史上非常詳細分析和介紹如何透過時間輪(TimingWheel)實現延時佇列的原理指南】,讓我們基本上已經知道了「時間輪演算法」原理和核心演算法機制,接下來我們需要面向於實戰開發以及落地角度進行分析如何實現時間輪的演算法機制體系。
前言回顧
什麼是時間輪
- 排程模型:時間輪是為解決高效排程任務而產生的排程模型/演算法思想。
- 資料結構:通常由hash表和雙向連結串列實現的資料結構。
為什麼用時間輪?
對比傳統佇列的優勢
相比傳統的佇列形式的排程器來說,時間輪能夠批次高效的管理各種延時任務、週期任務、通知任務等等。例如延時佇列/延時任務體系
延時任務/佇列體系
**延時任務、週期性任務,應用場景主要在延遲大規模的延時任務、週期性的定時任務等。
案例-Kafka的延時操作系列
比如,對於耗時的網路請求(比如Produce時等待ISR副本複製成功)會被封裝成DelayOperation進行延遲處理操作,防止阻塞Kafka請求處理執行緒,從而影響效率和效能。
傳統佇列帶來的效能問題
Kafka沒有使用傳統的佇列機制(JDK自帶的Timer+DelayQueue實現)。因為時間複雜度上這兩者插入和刪除操作都是 O(logn),不能滿足Kafka的高效能要求。
基於JDK自帶的Timer+DelayQueue實現
JDK Timer和DelayQueue底層都是個優先佇列,即採用了minHeap的資料結構,最快需要執行的任務排在佇列第一個,不一樣的是Timer中有個執行緒去拉取任務執行,DelayQueue其實就是個容器,需要配合其他執行緒工作。
ScheduledThreadPoolExecutor是JDK的定時任務實現的一種方式,其實也就是DelayQueue+池化執行緒的一個實現。
基於時間輪TimeWheel的實現
時間輪演算法的插入刪除操作都是O(1)的時間複雜度,滿足了Kafka對於效能的要求。除了Kafka以外,像 Netty 、ZooKeepr、Dubbo等開源專案、甚至Linux核心中都有使用到時間輪的實現。
當流量小時,使用DelayQueue效率更高。當流量大事,使用時間輪將大大提高效率。
時間輪演算法是怎麼樣的,演算法思想是什麼?
時間輪的資料結構
資料結構模型主要由:時間輪環形佇列和時間輪任務列表組成。
-
時間輪(TimingWheel) 是一個儲存定時任務的環形佇列(cycle array),底層採用環形陣列實現,陣列中的每個元素可以對應一個時間輪任務任務列表(TimeWheelTaskList) 。
-
時間輪任務任務列表(TimeWheelTaskList) 是一個環形的雙向連結串列,其中的每個元素都是延時/定時任務項(TaskEntry),其中封裝了任務基本資訊和後設資料(Metadata)。
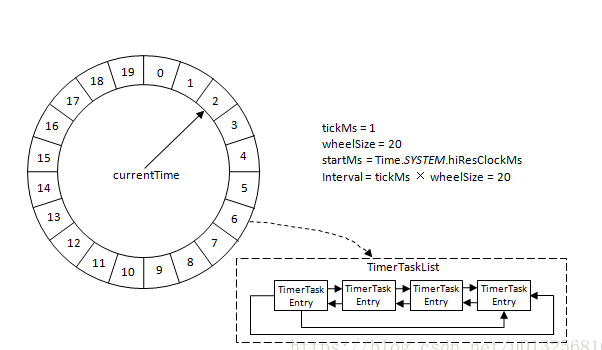
可以看到圖中的幾個引數:
-
startMs: 開始時間
-
tickMs: 時間輪執行的最小單位。時間輪由多個時間格組成,每個時間格代表當前時間輪的基本時間跨度就是tickMs。
-
wheelSize: 時間輪中環形佇列的數量。時間輪的時間格數量是固定的,可用wheelSize來表示。
-
interval:時間輪的整體時間跨度 = tickMs * wheelSize
根據上面這兩個屬性,我們就可以講整個時間輪的總體時間跨度(interval)可以透過公式tickMs × wheelSize計算得出。例如果時間輪的tickMs=1ms,wheelSize=20,那麼可以計算得出interval為20ms。
currentTime遊標指標
此外,時間輪還有一個遊標指標,我們稱之為(currentTime),它用來表示時間輪當前所處的時間,currentTime是tickMs的整數倍。
整個時間輪的總體跨度是不變的,隨著指標currentTime的不斷流動,當前時間輪所能處理的時間段也在不斷後移,整個時間輪的時間範圍在currentTime和currentTime+interval之間。
currentTime可以將整個時間輪劃分為到期部分和未到期部分,currentTime當前指向的時間格也屬於到期部分,表示剛好到期,需要處理此時間格所對應的TimeWheelTaskList中的所有任務。
currentTime遊標指標的運作流程
-
初始情況下表盤指標currentTime指向時間格0,此時有一個定時為2ms的任務插入進來會存放到時間格為2的任務列表中。
-
隨著時間的不斷推移,指標currentTime不斷向前推進,過了2ms之後,當到達時間格2時,就需要將時間格2所對應的任務列表中的任務做相應的到期操作。
-
此時若又有一個定時為8ms的任務插入進來,則會存放到時間格10中,currentTime再過8ms後會指向時間格10。
總之,整個時間輪的總體跨度是不變的,隨著指標currentTime的不斷推進,當前時間輪所能處理的時間段也在不斷後移,總體時間範圍在currentTime和currentTime+interval之間。
層次化時間輪機制
如果當提交了超過整體跨度(interval)的延時任務,如何解決呢?因此引入了層級時間輪的概念,當任務的到期時間超過了當前時間輪所表示的時間範圍時,就會嘗試新增到層次時間輪中。
層次化時間輪實現原理介紹
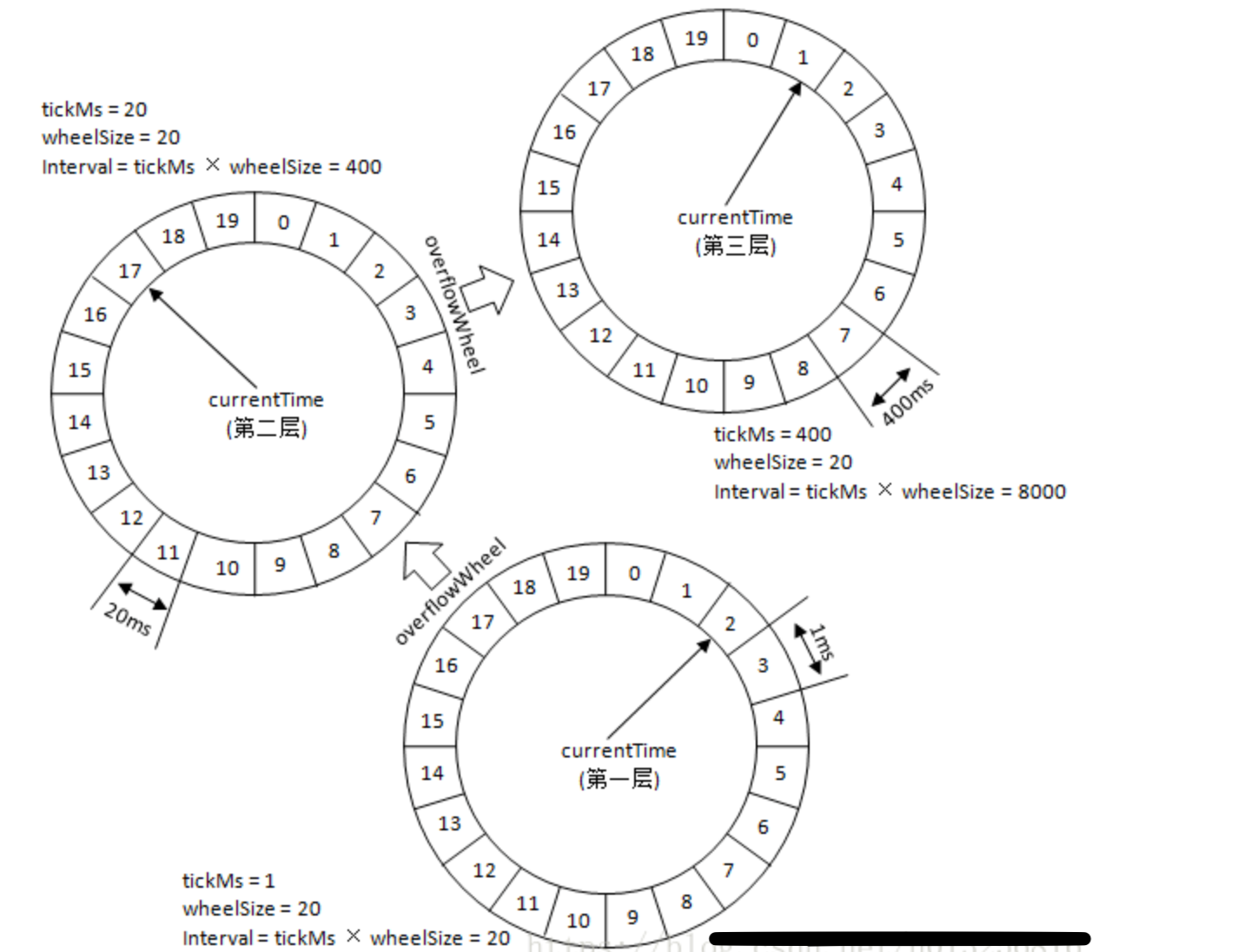
層次化時間輪任務升級躍遷
在任務插入時,如果第一層時間輪不滿足條件,就嘗試插入到高一層的時間輪,以此類推。
-
第一層的時間輪tickMs=1ms, wheelSize=20, interval=20ms
-
第二層的時間輪的tickMs為第一層時間輪的interval,即為20ms
第一層和第二層時間輪的wheelSize是固定的,都是20,那麼第二層的時間輪的總體時間跨度interval為400ms。正好是第一層時間輪的20倍。以此類推,這個400ms也是第三層的tickMs的大小,第三層的時間輪的總體時間跨度為8000ms。
- 第N層時間輪走了一圈,等於N+1層時間輪走一格。即高一層時間輪的時間跨度等於當前時間輪的整體跨度。
層次化時間輪任務降級躍遷
隨著時間推進,也會有一個時間輪降級的操作,原本延時較長的任務會從高一層時間輪重新提交到時間輪中,然後會被放在合適的低層次的時間輪當中等待處理;
案例介紹
層次化時間輪任務升級躍遷
例如:350ms的定時任務,顯然第一層時間輪不能滿足條件,所以就升級到第二層時間輪中,最終被插入到第二層時間輪中時間格17所對應的TimeWheelTaskList中。如果此時又有一個定時為450ms的任務,那麼顯然第二層時間輪也無法滿足條件,所以又升級到第三層時間輪中,最終被插入到第三層時間輪中時間格1的TimeWheelTaskList中。
層次化時間輪任務降級躍遷
在 [400ms,800ms) 區間的多個任務(比如446ms、455ms以及473ms的定時任務)都會被放入到第三層時間輪的時間格1中,時間格1對應的TimerTaskList的超時時間為400ms
隨著時間的流逝,當次TimeWheelTaskList到期之時,原本定時為450ms的任務還剩下50ms的時間,還不能執行這個任務的到期操作。
這裡就有一個時間輪降級的操作,會將這個剩餘時間為50ms的定時任務重新提交到層級時間輪中,此時第一層時間輪的總體時間跨度不夠,而第二層足夠,所以該任務被放到第二層時間輪到期時間為[40ms,60ms)的時間格中。
再經歷了40ms之後,此時這個任務又被“察覺”到,不過還剩餘10ms,還是不能立即執行到期操作。所以還要再有一次時間輪的降級,此任務被新增到第一層時間輪到期時間為[10ms,11ms)的時間格中,之後再經歷10ms後,此任務真正到期,最終執行相應的到期操作。
後續章節預告
接下來小編會出【演算法資料結構專題】「延時佇列演算法」史上手把手教你針對層級時間輪(TimingWheel)實現延時佇列的開發實戰落地(下),進行實戰編碼進行開發對應的層次化的時間輪演算法落地。