寫在前面
在產品初期快速迭代的過程中,往往為了快速上線而佔據市場,在後端開發的過程中往往不會過多的考慮分散式和微服務,往往會將後端服務做成一個單體應用,而資料庫也是一樣,最初會把所有的業務資料都放到一個資料庫中,即所謂的單例項資料庫。隨著業務的迅速發展,將所有資料都放在一個資料庫中已經不足以支撐業務發展的需要。此時,就會對系統進行分散式改造,而資料庫業務進行分庫分表的拆分。那麼,問題來了,如何更好的訪問和管理拆分後的資料庫呢?業界已經有很多成熟的解決方案,其中,一個非常優秀的解決方案就是:Apache ShardingSphere。今天,我們就從原始碼級別來共同探討下sharding-jdbc的核心原始碼。
sharding-jdbc經典用法
Sharding-Jdbc 是一個輕量級的分庫分表框架,使用時最關鍵的是配置分庫分表策略,其餘的和使用普通的 MySQL 驅動一樣,幾乎不用改程式碼。例如下面的程式碼片段。
try(DataSource dataSource = ShardingDataSourceFactory.createDataSource(
createDataSourceMap(), shardingRuleConfig, new Properties()) {
Connection connection = dataSource.getConnection();
...
}
我們在程式中拿到Connection物件後,就可以像使用普通的JDBC一樣來使用sharding-jdbc運算元據庫了。
sharding-jdbc包結構
sharding-jdbc
├── sharding-jdbc-core 重寫DataSource/Connection/Statement/ResultSet四大物件
└── sharding-jdbc-orchestration 配置中心
sharding-core
├── sharding-core-api 介面和配置類
├── sharding-core-common 通用分片策略實現...
├── sharding-core-entry SQL解析、路由、改寫,核心類BaseShardingEngine
├── sharding-core-route SQL路由,核心類StatementRoutingEngine
├── sharding-core-rewrite SQL改寫,核心類ShardingSQLRewriteEngine
├── sharding-core-execute SQL執行,核心類ShardingExecuteEngine
└── sharding-core-merge 結果合併,核心類MergeEngine
shardingsphere-sql-parser
├── shardingsphere-sql-parser-spi SQLParserEntry,用於初始化SQLParser
├── shardingsphere-sql-parser-engine SQL解析,核心類SQLParseEngine
├── shardingsphere-sql-parser-relation
└── shardingsphere-sql-parser-mysql MySQL解析器,核心類MySQLParserEntry和MySQLParser
shardingsphere-underlying 基礎介面和api
├── shardingsphere-rewrite SQLRewriteEngine介面
├── shardingsphere-execute QueryResult查詢結果
└── shardingsphere-merge MergeEngine介面
shardingsphere-spi SPI載入工具類
sharding-transaction
├── sharding-transaction-core 介面ShardingTransactionManager,SPI載入
├── sharding-transaction-2pc 實現類XAShardingTransactionManager
└── sharding-transaction-base 實現類SeataATShardingTransactionManager
sharding-jdbc中的四大物件
所有的一切都從 ShardingDataSourceFactory 開始的,建立了一個 ShardingDataSource 的分片資料來源。除了 ShardingDataSource(分片資料來源),在 Sharding-Sphere 中還有 MasterSlaveDataSourceFactory(主從資料來源)、EncryptDataSourceFactory(脫敏資料來源)。
public static DataSource createDataSource(
final Map<String, DataSource> dataSourceMap,
final ShardingRuleConfiguration shardingRuleConfig,
final Properties props) throws SQLException {
return new ShardingDataSource(dataSourceMap,
new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);
}
說明: 本文主要以 ShardingDataSource 為切入點分析 Sharding-Sphere 是如何對 JDBC 四大物件 DataSource、Connection、Statement、ResultSet 進行封裝的。
DataSource
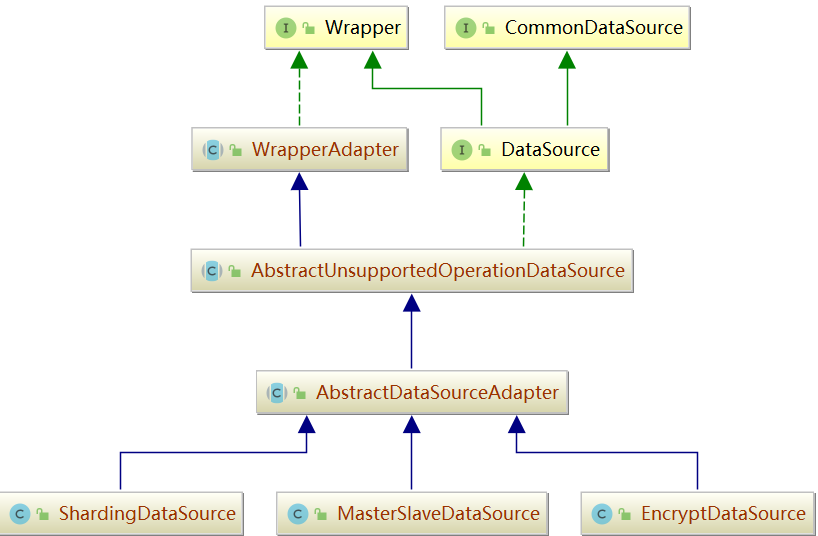
這裡,涉及到兩個比較重要的介面,一個是DataSource,一個是Connection。我們首先來看下它們的類圖。
-
DataSource
-
Connection
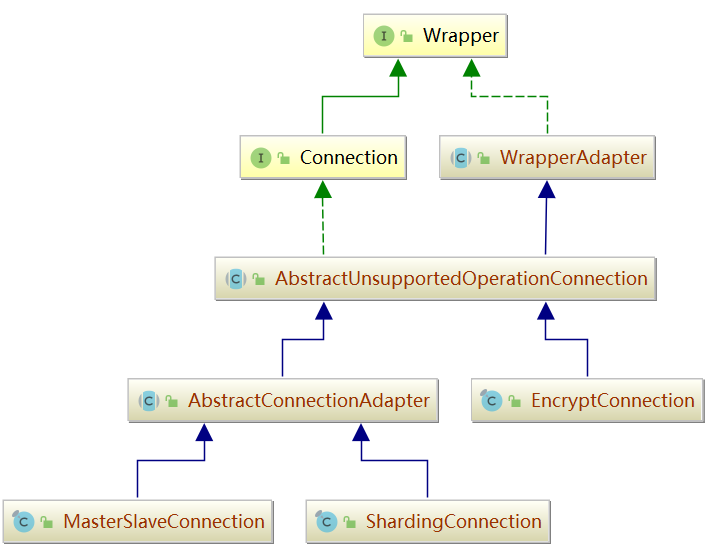
DataSource 和 Connection 都比較簡單,沒有處理過多的邏輯,只是 dataSourceMap, shardingRule 進行簡單的封裝。
ShardingDataSource 持有對資料來源和分片規則,可以通過 getConnection 方法獲取 ShardingConnection 連線。
private final ShardingRuntimeContext runtimeContext = new ShardingRuntimeContext(
dataSourceMap, shardingRule, props, getDatabaseType());
@Override
public final ShardingConnection getConnection() {
return new ShardingConnection(getDataSourceMap(), runtimeContext,
TransactionTypeHolder.get());
}
Connection
ShardingConnection 可以建立 Statement 和 PrepareStatement 兩種執行方式,如下程式碼所示。
@Override
public Statement createStatement(final int resultSetType,
final int resultSetConcurrency, final int resultSetHoldability) {
return new ShardingStatement(this, resultSetType,
resultSetConcurrency, resultSetHoldability);
}
@Override
public PreparedStatement prepareStatement(final String sql, final int resultSetType,
final int resultSetConcurrency, final int resultSetHoldability)
throws SQLException {
return new ShardingPreparedStatement(this, sql, resultSetType,
resultSetConcurrency, resultSetHoldability);
}
說明: ShardingConnection 主要是將建立 ShardingStatement 和 ShardingPreparedStatement 兩個物件,主要的執行邏輯都在 Statement 物件中。另外,ShardingConnection 還有兩個重要的功能,一個是獲取真正的資料庫連線,一個是事務提交功能。
Statement
Statement 相對來說比較複雜,因為它都是 JDBC 的真正執行器,所有邏輯都封裝在 Statement 中。我們來看下Statement的類圖
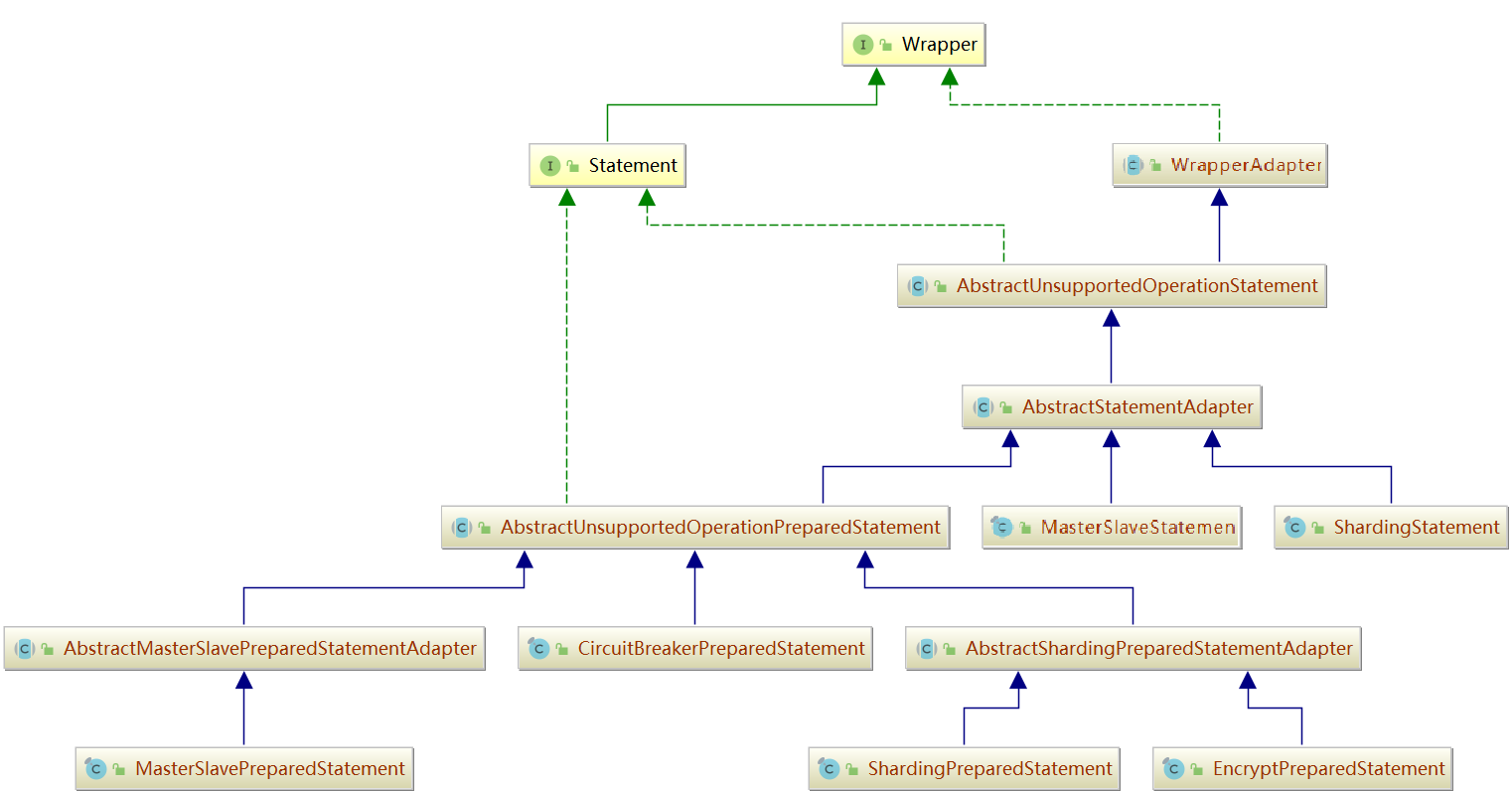
對於Statement,我就不做過多的描述了,相信使用過JDBC的小夥伴,對Statement都不陌生了。
ResultSet
ResultSet類圖如下所示。
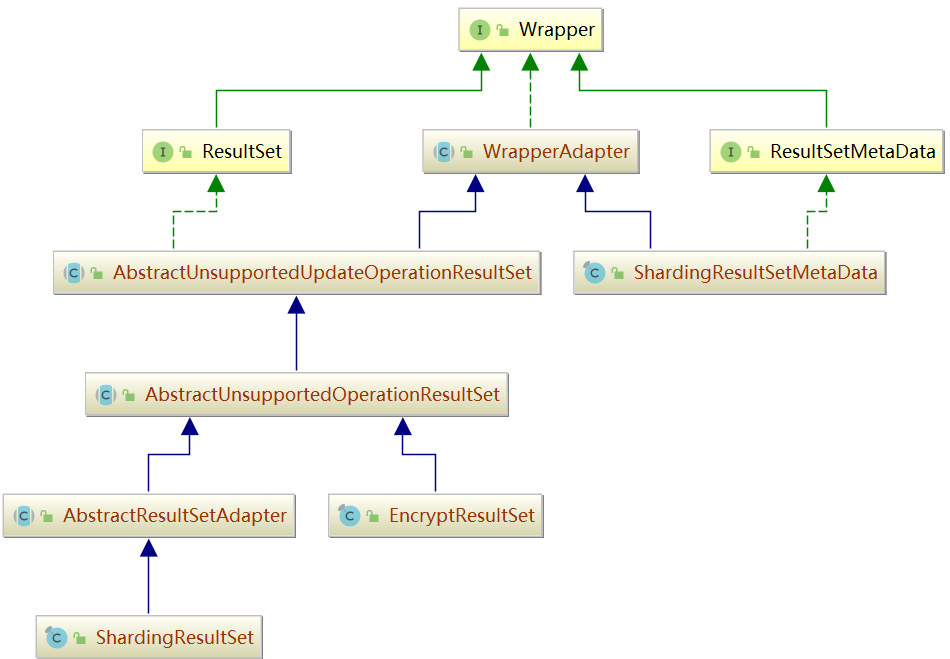
我們從原始碼中可以看出:ShardingResultSet 只是對 MergedResult 的簡單封裝。
private final MergedResult mergeResultSet;
@Override
public boolean next() throws SQLException {
return mergeResultSet.next();
}
sharding-jdbc-core核心分析
ShardingStatement 內部有三個核心的類,一是 SimpleQueryShardingEngine 完成 SQL 解析、路由、改寫;一是 StatementExecutor 進行 SQL 執行;最後呼叫 MergeEngine 對結果進行合併處理。
ShardingStatement
初始化
private final ShardingConnection connection;
private final StatementExecutor statementExecutor;
public ShardingStatement(final ShardingConnection connection) {
this(connection, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY,
ResultSet.HOLD_CURSORS_OVER_COMMIT);
}
public ShardingStatement(final ShardingConnection connection, final int resultSetType,
final int resultSetConcurrency, final int resultSetHoldability) {
super(Statement.class);
this.connection = connection;
statementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency,
resultSetHoldability, connection);
}
ShardingStatement 內部執行 SQL 委託給了 statementExecutor。
執行
(1)executeQuery 執行過程
@Override
public ResultSet executeQuery(final String sql) throws SQLException {
ResultSet result;
try {
clearPrevious();
// 1. SQL 解析、路由、改寫,最終生成 SQLRouteResult
shard(sql);
// 2. 生成執行計劃 SQLRouteResult -> StatementExecuteUnit
initStatementExecutor();
// 3. statementExecutor.executeQuery() 執行任務
MergeEngine mergeEngine = MergeEngineFactory.newInstance(
connection.getRuntimeContext().getDatabaseType(),
connection.getRuntimeContext().getRule(), sqlRouteResult,
connection.getRuntimeContext().getMetaData().getRelationMetas(),
statementExecutor.executeQuery());
// 4. 結果合併
result = getResultSet(mergeEngine);
} finally {
currentResultSet = null;
}
currentResultSet = result;
return result;
}
(2)SQL 路由(包括 SQL 解析、路由、改寫)
private SQLRouteResult sqlRouteResult;
private void shard(final String sql) {
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
SimpleQueryShardingEngine shardingEngine = new SimpleQueryShardingEngine(
runtimeContext.getRule(), runtimeContext.getProps(),
runtimeContext.getMetaData(), runtimeContext.getParseEngine());
sqlRouteResult = shardingEngine.shard(sql, Collections.emptyList());
}
SimpleQueryShardingEngine 進行 SQL 路由(包括 SQL 解析、路由、改寫),生成 SQLRouteResult,當 ShardingStatement 完成 SQL 的路由,生成 SQLRouteResult 後,剩下的執行任務就全部交給 StatementExecutor 完成。
StatementExecutor
StatementExecutor 內部封裝了 SQL 任務的執行過程,包括:SqlExecutePrepareTemplate 類生成執行計劃 StatementExecuteUnit,以及 SQLExecuteTemplate 用於執行 StatementExecuteUnit。
類結構

重要屬性
AbstractStatementExecutor 類中重要的屬性:
// SQLExecutePrepareTemplate用於生成執行計劃StatementExecuteUnit
private final SQLExecutePrepareTemplate sqlExecutePrepareTemplate;
// 儲存生成的執行計劃StatementExecuteUnit
private final Collection<ShardingExecuteGroup<StatementExecuteUnit>> executeGroups =
new LinkedList<>();
// SQLExecuteTemplate用於執行StatementExecuteUnit
private final SQLExecuteTemplate sqlExecuteTemplate;
// 儲存查詢結果
private final List<ResultSet> resultSets = new CopyOnWriteArrayList<>();
生成執行計劃
// 執行前清理狀態
private void clearPrevious() throws SQLException {
statementExecutor.clear();
}
// 執行時初始化
private void initStatementExecutor() throws SQLException {
statementExecutor.init(sqlRouteResult);
replayMethodForStatements();
}
這裡,需要注意的是: StatementExecutor 是有狀態的,每次執行前都要呼叫 statementExecutor.clear() 清理上一次執行的狀態,並呼叫 statementExecutor.init() 重新初始化。
statementExecutor.init() 初始化主要是生成執行計劃 StatementExecuteUnit。
public void init(final SQLRouteResult routeResult) throws SQLException {
setSqlStatementContext(routeResult.getSqlStatementContext());
getExecuteGroups().addAll(obtainExecuteGroups(routeResult.getRouteUnits()));
cacheStatements();
}
private Collection<ShardingExecuteGroup<StatementExecuteUnit>> obtainExecuteGroups(
final Collection<RouteUnit> routeUnits) throws SQLException {
return getSqlExecutePrepareTemplate().getExecuteUnitGroups(
routeUnits, new SQLExecutePrepareCallback() {
// 獲取連線
@Override
public List<Connection> getConnections(
final ConnectionMode connectionMode,
final String dataSourceName, final int connectionSize)
throws SQLException {
return StatementExecutor.super.getConnection().getConnections(
connectionMode, dataSourceName, connectionSize);
}
// 生成執行計劃RouteUnit -> StatementExecuteUnit
@Override
public StatementExecuteUnit createStatementExecuteUnit(
final Connection connection, final RouteUnit routeUnit,
final ConnectionMode connectionMode) throws SQLException {
return new StatementExecuteUnit(
routeUnit, connection.createStatement(
getResultSetType(), getResultSetConcurrency(),
getResultSetHoldability()), connectionMode);
}
});
}
SqlExecutePrepareTemplate 是 sharding-core-execute 工程中提供的一個工具類,專門用於生成執行計劃,將 RouteUnit 轉化為 StatementExecuteUnit。同時還提供了另一個工具類 SQLExecuteTemplate 用於執行 StatementExecuteUnit,在任務執行時我們會看到這個類。
任務執行
public List<QueryResult> executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback<QueryResult> executeCallback =
new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final String sql, final Statement statement,
final ConnectionMode connectionMode) throws SQLException {
return getQueryResult(sql, statement, connectionMode);
}
};
// 執行StatementExecuteUnit
return executeCallback(executeCallback);
}
// sqlExecuteTemplate 執行 executeGroups(即StatementExecuteUnit)
protected final <T> List<T> executeCallback(
final SQLExecuteCallback<T> executeCallback) throws SQLException {
// 執行所有的任務 StatementExecuteUnit
List<T> result = sqlExecuteTemplate.executeGroup(
(Collection) executeGroups, executeCallback);
refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);
return result;
}
SqlExecuteTemplate 執行 StatementExecuteUnit 會回撥 SQLExecuteCallback#executeSQL 方法,最終呼叫 getQueryResult 方法。
private QueryResult getQueryResult(final String sql, final Statement statement,
final ConnectionMode connectionMode) throws SQLException {
ResultSet resultSet = statement.executeQuery(sql);
getResultSets().add(resultSet);
return ConnectionMode.MEMORY_STRICTLY == connectionMode
? new StreamQueryResult(resultSet)
: new MemoryQueryResult(resultSet);
}
ConnectionMode 有兩種模式:記憶體限制(MEMORY_STRICTLY)和連線限制(CONNECTION_STRICTLY),如果一個連線執行多個 StatementExecuteUnit 則為記憶體限制(MEMORY_STRICTLY),採用流式處理,即 StreamQueryResult ,反之則為連線限制(CONNECTION_STRICTLY),此時會將所有從 MySQL 伺服器返回的資料都載入到記憶體中。特別是在 Sharding-Proxy 中特別有用,避免將代理伺服器撐爆。
重磅福利
微信搜一搜【冰河技術】微信公眾號,關注這個有深度的程式設計師,每天閱讀超硬核技術乾貨,公眾號內回覆【PDF】有我準備的一線大廠面試資料和我原創的超硬核PDF技術文件,以及我為大家精心準備的多套簡歷模板(不斷更新中),希望大家都能找到心儀的工作,學習是一條時而鬱鬱寡歡,時而開懷大笑的路,加油。如果你通過努力成功進入到了心儀的公司,一定不要懈怠放鬆,職場成長和新技術學習一樣,不進則退。如果有幸我們江湖再見!
另外,我開源的各個PDF,後續我都會持續更新和維護,感謝大家長期以來對冰河的支援!!