某國產資料庫原廠高階工程師找我最佳化SQL,以下是他給的三個案例。😼
案例一:
慢SQL和執行計劃:
SELECT c.*
FROM aaaaa a
INNER JOIN bbbbbbbbbbb b
ON a.attend_rule_id = b.attend_rule_id
INNER JOIN cccccccccc c
ON b.work_place_id = c.id
INNER JOIN ddddddddddd d
ON a.attend_rule_id = d.id
WHERE a.staff_id = '0001A11000000005DVBN'
AND nvl(a.dr, 0) = '0'
AND nvl(b.dr, 0) = '0'
AND nvl(c.dr, 0) = '0'
AND nvl(d.dr, 0) = '0';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.55..258.52 rows=1 width=2253) (actual time=320.842..320.845 rows=0 loops=1)
-> Nested Loop (cost=0.28..251.02 rows=1 width=33) (actual time=320.841..320.843 rows=0 loops=1)
-> Nested Loop (cost=0.00..235.87 rows=1 width=99) (actual time=0.050..83.992 rows=3629 loops=1)
Join Filter: ((b.attend_rule_id)::text = (d.id)::text)
Rows Removed by Join Filter: 540055
-> Seq Scan on bbbbbbbbbbb b (cost=0.00..210.09 rows=20 width=66) (actual time=0.021..2.125 rows=3630 loops=1)
Filter: (NVL(int4(dr), 0) = 0)
Rows Removed by Filter: 314
-> Materialize (cost=0.00..25.19 rows=2 width=33) (actual time=0.000..0.006 rows=150 loops=3630)
-> Seq Scan on ddddddddddd d (cost=0.00..25.18 rows=2 width=33) (actual time=0.013..0.171 rows=302 loops=1)
Filter: (NVL(int4(dr), 0) = 0)
Rows Removed by Filter: 45
-> Index Scan using scopepsnindex on aaaaa a (cost=0.28..15.14 rows=1 width=33) (actual time=0.065..0.065 rows=0 loops=3629)
Index Cond: ((attend_rule_id)::text = (b.attend_rule_id)::text)
Filter: (((staff_id)::text = '0001A11000000005DVBN'::text) AND (NVL(int4(dr), 0) = 0))
Rows Removed by Filter: 5
-> Index Scan using pk_attend_place on cccccccccc c (cost=0.28..5.90 rows=1 width=2253) (never executed)
Index Cond: ((id)::text = (b.work_place_id)::text)
Filter: (NVL(int4(dr), 0) = 0)
Planning Time: 3.101 ms
Execution Time: 321.016 ms
(21 rows)
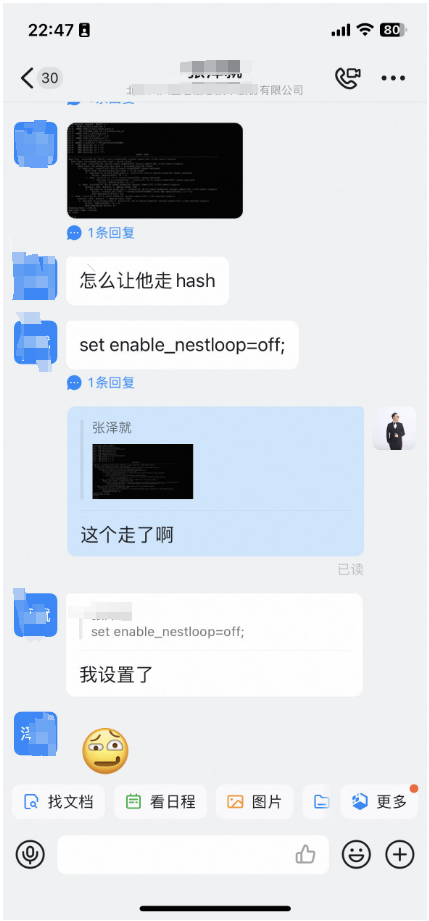
他將 enable_nestloop 關閉以後強行後hash,速度快了不少,但是需要使用hint干預計劃。
ncc=# set enable_nestloop=off;
SET
ncc=# explain analyze SELECT c.*
ncc-# FROM aaaaa a
ncc-# INNER JOIN bbbbbbbbbbb b
ncc-# ON a.attend_rule_id = b.attend_rule_id
ncc-# INNER JOIN cccccccccc c
ncc-# ON b.work_place_id = c.id
ncc-# INNER JOIN ddddddddddd d
ncc-# ON a.attend_rule_id = d.id
ncc-# WHERE a.staff_id = '0001A11000000005DVBN'
ncc-# AND nvl(a.dr, 0) = '0'
ncc-# AND nvl(b.dr, 0) = '0'
ncc-# AND nvl(c.dr, 0) = '0'
ncc-# AND nvl(d.dr, 0) = '0';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=144.46..354.61 rows=1 width=2253) (actual time=0.497..0.499 rows=0 loops=1)
Hash Cond: ((a.attend_rule_id)::text = (d.id)::text)
-> Hash Join (cost=119.26..329.41 rows=1 width=2319) (actual time=0.282..0.283 rows=0 loops=1)
Hash Cond: ((b.attend_rule_id)::text = (a.attend_rule_id)::text)
-> Hash Join (cost=71.19..281.33 rows=1 width=2286) (never executed)
Hash Cond: ((b.work_place_id)::text = (c.id)::text)
-> Seq Scan on bbbbbbbbbbb b (cost=0.00..210.09 rows=20 width=66) (never executed)
Filter: (NVL(int4(dr), 0) = 0)
-> Hash (cost=71.11..71.11 rows=6 width=2253) (never executed)
-> Seq Scan on cccccccccc c (cost=0.00..71.11 rows=6 width=2253) (never executed)
Filter: (NVL(int4(dr), 0) = 0)
-> Hash (cost=48.05..48.05 rows=1 width=33) (actual time=0.278..0.279 rows=0 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 8kB
-> Seq Scan on aaaaa a (cost=0.00..48.05 rows=1 width=33) (actual time=0.278..0.278 rows=0 loops=1)
Filter: (((staff_id)::text = '0001A11000000005DVBN'::text) AND (NVL(int4(dr), 0) = 0))
Rows Removed by Filter: 806
-> Hash (cost=25.18..25.18 rows=2 width=33) (actual time=0.199..0.199 rows=302 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 28kB
-> Seq Scan on ddddddddddd d (cost=0.00..25.18 rows=2 width=33) (actual time=0.013..0.148 rows=302 loops=1)
Filter: (NVL(int4(dr), 0) = 0)
Rows Removed by Filter: 45
Planning Time: 1.556 ms
Execution Time: 0.585 ms
這種簡單的語句我大概看了2秒種,給出改寫方案,不帶思考的。
SELECT c.*
FROM aaaaa a
INNER JOIN bbbbbbbbbbb b
ON a.attend_rule_id = b.attend_rule_id
INNER JOIN cccccccccc c
ON b.work_place_id = c.id
INNER JOIN ddddddddddd d
ON a.attend_rule_id = d.id
WHERE a.staff_id = '0001A11000000005DVBN'
AND CASE WHEN a.dr IS NULL THEN 0 ELSE a.dr END = 0
AND CASE WHEN b.dr IS NULL THEN 0 ELSE b.dr END = 0
AND CASE WHEN c.dr IS NULL THEN 0 ELSE c.dr END = 0
AND CASE WHEN d.dr IS NULL THEN 0 ELSE d.dr END = 0;

案例二:
慢SQL和執行計劃:
SELECT to_char(t1.signbegintime, 'YYYY-MM-DD HH24:MI:SS') AS workSignTime,
to_char(t1.signendtime, 'YYYY-MM-DD HH24:MI:SS') AS workoffSignTime,
t1.f_v_8 AS signType,
to_char(t1.calendar, 'YYYY-MM-DD') AS calendar,
to_char(t2.begintime, 'YYYY-MM-DD HH24:MI:SS') AS workTime,
to_char(t2.endtime, 'YYYY-MM-DD HH24:MI:SS') AS workOffTime
FROM ts_daystat t1
INNER JOIN ts_shift t2
ON t1.shift_id = t2.id
WHERE t1.staff_id = '0001A110000000062QPG'
AND t1.calendar LIKE '%2024-05%'
ORDER BY calendar ASC;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Sort (cost=98960.15..98960.15 rows=1 width=167) (actual time=436.621..493.088 rows=9 loops=1)
Sort Key: (to_char((t1.calendar)::timestamp without time zone, 'YYYY-MM-DD'::text))
Sort Method: quicksort Memory: 26kB
-> Nested Loop (cost=1000.14..98960.14 rows=1 width=167) (actual time=123.310..493.061 rows=9 loops=1)
-> Gather (cost=1000.00..98951.77 rows=1 width=63) (actual time=123.209..492.857 rows=9 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on ts_daystat t1 (cost=0.00..97951.67 rows=1 width=63) (actual time=184.979..430.729 rows=3 loops=3)
Filter: (((staff_id)::text = '0001A110000000062QPG'::text) AND ((calendar)::text ~~ '%2024-05%'::text))
Rows Removed by Filter: 199107
-> Index Scan using pk_shift on ts_shift t2 (cost=0.14..8.16 rows=1 width=48) (actual time=0.006..0.006 rows=1 loops=9)
Index Cond: ((id)::text = (t1.shift_id)::text)
Planning Time: 0.890 ms
Execution Time: 493.383 ms
(14 rows)
這條SQL我也是簡單喵了一眼,讓原廠高階工程師加個索引 t1 表對 staff_id,shift_id 兩個列加個索引,但是他對我的建議表示懷疑。😂
畢竟人家是原廠工程師,對他們家的產品更加專業,更加權威,專業性這塊是毋庸置疑的。
我只能放低姿態,懇請原廠老師加條索引驗證下我的錯誤,只有認識到自己的錯誤,才能更好得進步。🤓
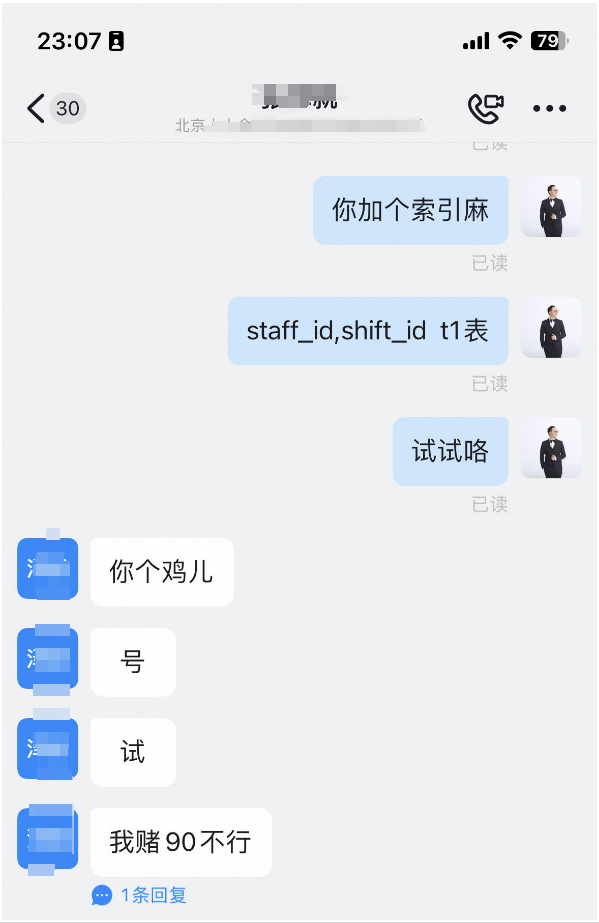
加了索引以後的執行計劃,已經從 493ms 降低到 1.5ms了。

我確實也很想反思一下自己,被原廠老師指正一下,認識自己的錯誤,才能進步。無奈可惜哥真的是太猛了,沒啥值得反思的。😁
案例三:
慢SQL和執行計劃:
SELECT a.*
FROM bbbbbb b
INNER JOIN eeeeee e
ON b.pk_psndoc = e.pk_psndoc
INNER JOIN (SELECT max(orgrelaid) AS orgrelaid, pk_psndoc
FROM eeeeee
WHERE indocflag = 'Y'
GROUP BY pk_psndoc) tmp
ON e.pk_psndoc = tmp.pk_psndoc
AND e.orgrelaid = tmp.orgrelaid
INNER JOIN aaaaaa a
ON a.pk_psnorg = e.pk_psnorg
AND a.lastflag = 'Y'
AND a.ismainjob = 'Y'
INNER JOIN oooooo o
ON o.PK_ADMINORG = a.PK_ORG
WHERE e.indocflag = 'Y'
AND e.psntype = 0
AND e.endflag = 'N'
AND a.endflag = 'N'
AND a.pk_group = '0001A110000000000JQ6'
AND length(b.birthdate) = 10
AND a.pk_hrorg IN ('0001A11000000000L7XF')
AND substring(b.birthdate, 6, 5) >= '05-10'
AND substring(b.birthdate, 6, 5) <= '06-09'
ORDER BY substring(b.birthdate, 6, 5),
substring(b.birthdate, 1, 4),
a.PK_ORG,
a.PK_DEPT,
b.CODE;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Sort (cost=43067.37..43067.37 rows=1 width=1887) (actual time=21375.999..21376.005 rows=38 loops=1)
Sort Key: ("substring"((b.birthdate)::text, 6, 5)), ("substring"((b.birthdate)::text, 1, 4)), a.pk_org, a.pk_dept, b.code
Sort Method: quicksort Memory: 63kB
-> Nested Loop (cost=8706.95..43067.36 rows=1 width=1887) (actual time=137.485..21375.586 rows=38 loops=1)
-> Nested Loop (cost=8706.68..43067.03 rows=1 width=1834) (actual time=137.458..21374.882 rows=38 loops=1)
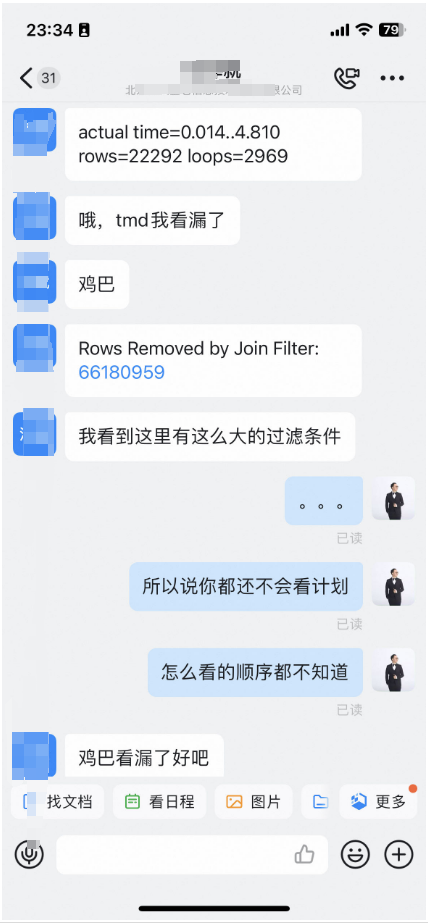
-> Nested Loop (cost=8706.26..43064.13 rows=1 width=45) (actual time=54.801..21358.779 rows=620 loops=1)
Join Filter: ((b.pk_psndoc)::text = (e.pk_psndoc)::text)
-> Nested Loop (cost=8705.85..43062.82 rows=1 width=68) (actual time=54.750..21244.441 rows=2961 loops=1)
Join Filter: ((b.pk_psndoc)::text = (eeeeee.pk_psndoc)::text)
Rows Removed by Join Filter: 66180959
-> Seq Scan on bbbbbb b (cost=0.00..32921.80 rows=1 width=45) (actual time=0.014..79.239 rows=2969 loops=1)
Filter: (("substring"((birthdate)::text, 6, 5) >= '05-10'::text) AND ("substring"((birthdate)::text, 6, 5) <= '06-09'::text) AND (length((birthdate)::text)
= 10))
Rows Removed by Filter: 41327
-> HashAggregate (cost=8705.85..9147.44 rows=44159 width=23) (actual time=0.014..4.810 rows=22292 loops=2969)
Group Key: eeeeee.pk_psndoc
-> Seq Scan on eeeeee (cost=0.00..8484.91 rows=44187 width=23) (actual time=0.005..21.398 rows=44216 loops=1)
Filter: (indocflag = 'Y'::bpchar)
Rows Removed by Filter: 105
-> Index Scan using i_hi_psnorg_1 on eeeeee e (cost=0.41..1.30 rows=1 width=44) (actual time=0.033..0.033 rows=0 loops=2961)
Index Cond: ((pk_psndoc)::text = (eeeeee.pk_psndoc)::text)
Filter: ((indocflag = 'Y'::bpchar) AND (psntype = 0) AND (endflag = 'N'::bpchar) AND ((max(eeeeee.orgrelaid)) = orgrelaid))
Rows Removed by Filter: 1
-> Index Scan using i_hi_psnjob_8 on aaaaaa a (cost=0.41..2.89 rows=1 width=1810) (actual time=0.024..0.024 rows=0 loops=620)
Index Cond: ((pk_psnorg)::text = (e.pk_psnorg)::text)
Filter: ((lastflag = 'Y'::bpchar) AND (ismainjob = 'Y'::bpchar) AND (endflag = 'N'::bpchar) AND (pk_group = '0001A110000000000JQ6'::bpchar) AND ((pk_hrorg)::text = '000
1A11000000000L7XF'::text))
Rows Removed by Filter: 1
-> Index Only Scan using i_pk_adminorg on oooooo o (cost=0.27..0.32 rows=1 width=21) (actual time=0.011..0.011 rows=1 loops=38)
Index Cond: (pk_adminorg = a.pk_org)
Heap Fetches: 0
Planning Time: 4.773 ms
Execution Time: 21376.659 ms
(31 rows)

原廠大佬覺得可以加索引解決問題,但是在下確不這麼認為,還是等價改了一個版本讓原廠大佬測試下:
SELECT a.*
FROM bbbbbb b
INNER JOIN eeeeee e
ON b.pk_psndoc = e.pk_psndoc
INNER JOIN (SELECT max(orgrelaid) AS orgrelaid, pk_psndoc
FROM eeeeee
WHERE indocflag = 'Y' AND ROWNUM > 0
GROUP BY pk_psndoc) tmp
ON e.pk_psndoc = tmp.pk_psndoc
AND e.orgrelaid = tmp.orgrelaid
INNER JOIN aaaaaa a
ON a.pk_psnorg = e.pk_psnorg
AND a.lastflag = 'Y'
AND a.ismainjob = 'Y'
INNER JOIN oooooo o
ON o.PK_ADMINORG = a.PK_ORG
WHERE e.indocflag = 'Y'
AND e.psntype = 0
AND e.endflag = 'N'
AND a.endflag = 'N'
AND a.pk_group = '0001A110000000000JQ6'
AND length(b.birthdate) = 10
AND a.pk_hrorg IN ('0001A11000000000L7XF')
AND substring(b.birthdate, 6, 5) >= '05-10'
AND substring(b.birthdate, 6, 5) <= '06-09'
ORDER BY substring(b.birthdate, 6, 5),
substring(b.birthdate, 1, 4),
a.PK_ORG,
a.PK_DEPT,
b.CODE;

改寫後這條語句 2.3 秒能跑出結果,比之前速度快了10倍。
原廠大佬最後還不遺餘力來請教我這條SQL最佳化的原理,這愛上進,愛學習的精神,真的是領人感到敬佩!!!😁😁😁
本文內容都是開玩笑的,大家當段子看就行。