
前言
作為本系列第一篇文章,我分享一個模型訓練過程中常用到的工具,voc資料集轉coco資料集。
在我做一些演算法學習的時候,需要將voc資料集轉coco放到yolo當中訓練,但是在網上找了很多個都不是很好用,要不是會報錯,要不是根本不能跑起來。為了節省在學習演算法小夥伴的時間,我分享我在工作常常用的voc轉coco的指令碼。
voc 格式分析
為了能夠更好理解指令碼,首先對voc資料集的格式做一個簡單分析。
voc 全稱 The PASCAL Visual Object Classes,它由Visual Object Classes(可視物件類)和挑戰(Challenge)等競賽專案開發, 開始於2005年,結束於2012年最後一屆 。
VOC資料集包含許多不同型別的影像,每個影像都標註了一些可視物件,如人,汽車,狗等。這些標註包括每個物件的位置,大小和類別等資訊。
常見的voc資料集是voc2007 和voc 2012,當然在模型訓練過程肯定都會自己標註資料集,匯出為voc格式。
voc 資料集的格式:
<annotation>
<folder>17</folder> # 圖片所處資料夾
<filename>77258.bmp</filename> # 圖片名
<path>~/frcnn-image/61/ADAS/image/frcnn-image/17/77258.bmp</path>
<source> #圖片來源相關資訊
<database>Unknown</database>
</source>
<size> #圖片尺寸
<width>640</width>
<height>480</height>
<depth>3</depth>
</size>
<segmented>0</segmented> #是否有分割label
<object> 包含的物體
<name>car</name> #物體類別
<pose>Unspecified</pose> #物體的姿態
<truncated>0</truncated> #物體是否被部分遮擋(>15%)
<difficult>0</difficult> #是否為難以辨識的物體, 主要指要結體背景才能判斷出類別的物體。雖有標註, 但一般忽略這類物體
<bndbox> #物體的bound box
<xmin>2</xmin> #左
<ymin>156</ymin> #上
<xmax>111</xmax> #右
<ymax>259</ymax> #下
</bndbox>
</object>
</annotation>
重要的資訊包括:filename, size, object 等。除此之外,還有一個主要注意的點就是標註的座標,xmin,ymin,xmax,ymax是標註的四個角,分別代表:
- xmin: 左上角x軸座標
- ymin:左上角y周座標
- xmax: 右下角x軸座標
- ymax:右下角y軸座標
coco 格式分析
COCO的 全稱是Common Objects in COntext,是微軟團隊提供的一個可以用來進行影像識別的資料集。MS COCO數 據集中的影像分為訓練、驗證和測試集。
假設有以下兩個影像檔案:
- image1.jpg
- image2.jpg
coco格式資料集:annotations.json
{
"images": [
{
"id": 1,
"file_name": "image1.jpg",
"width": 640,
"height": 480
},
{
"id": 2,
"file_name": "image2.jpg",
"width": 800,
"height": 600
}
],
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 1,
"bbox": [50, 50, 100, 100],
"area": 10000,
"segmentation": [
[
50, 50, 50, 150, 150, 50
]
],
"iscrowd": 0
},
{
"id": 2,
"image_id": 2,
"category_id": 2,
"bbox": [150, 200, 200, 150],
"area": 30000,
"segmentation": [
[
150, 200, 150, 350, 350, 200
]
],
"iscrowd": 0
}
],
"categories": [
{
"id": 1,
"name": "cat",
"supercategory": "animal"
},
{
"id": 2,
"name": "dog",
"supercategory": "animal"
}
]
}
coco 資料集欄位解析
coco 資料集是一個json檔案,一共包括5個部分。
{
"info": info, # 資料集的基本資訊
"licenses": [license], # 許可證
"images": [image], # 圖片資訊,名字和寬高
"annotations": [annotation], # 標註資訊
"categories": [category] # 標籤資訊
}
info{ # 資料集資訊描述
"year": int, # 資料集年份
"version": str, # 資料集版本
"description": str, # 資料集描述
"contributor": str, # 資料集提供者
"url": str, # 資料集下載連結
"date_created": datetime, # 資料集建立日期
}
license{
"id": int,
"name": str,
"url": str,
}
image{ # images是一個list,存放所有圖片(dict)資訊。image是一個dict,存放單張圖片資訊
"id": int, # 圖片的ID編號(每張圖片ID唯一)
"width": int, # 圖片寬
"height": int, # 圖片高
"file_name": str, # 圖片名字
"license": int, # 協議
"flickr_url": str, # flickr連結地址
"coco_url": str, # 網路連線地址
"date_captured": datetime, # 資料集獲取日期
}
annotation{ # annotations是一個list,存放所有標註(dict)資訊。annotation是一個dict,存放單個目標標註資訊。
"id": int, # 目標物件ID(每個物件ID唯一),每張圖片可能有多個目標
"image_id": int, # 對應圖片ID
"category_id": int, # 對應類別ID,與categories中的ID對應
"segmentation": RLE or [polygon], # 例項分割,物件的邊界點座標[x1,y1,x2,y2,....,xn,yn]
"area": float, # 物件區域面積
"bbox": [xmin,ymin,width,height], # 目標檢測,物件定位邊框[x,y,w,h]
"iscrowd": 0 or 1, # 表示是否是人群
}
categories{ # 類別描述
"id": int, # 類別對應的ID(0預設為背景)
"name": str, # 子類別名字
"supercategory": str, # 主類別名字
}
需要注意的是coco資料集標註的座標。xmin ymin width height和voc有很大差異,分別代表:
- xmin 左上角x軸座標
- ymin 左上角y軸座標
- width 圖片畫素寬
- heidht 圖片畫素高
指令碼使用
通常在yolo模型檢測訓練時需要的資料集是coco格式或者yolo格式,那麼就需要將voc轉成coco。通常在生成任務中實用的voc資料集的檔案和官方資料集格式略有差異。所以首先需要說明,使用該指令碼之前需要將voc檔案調整成如下格式:
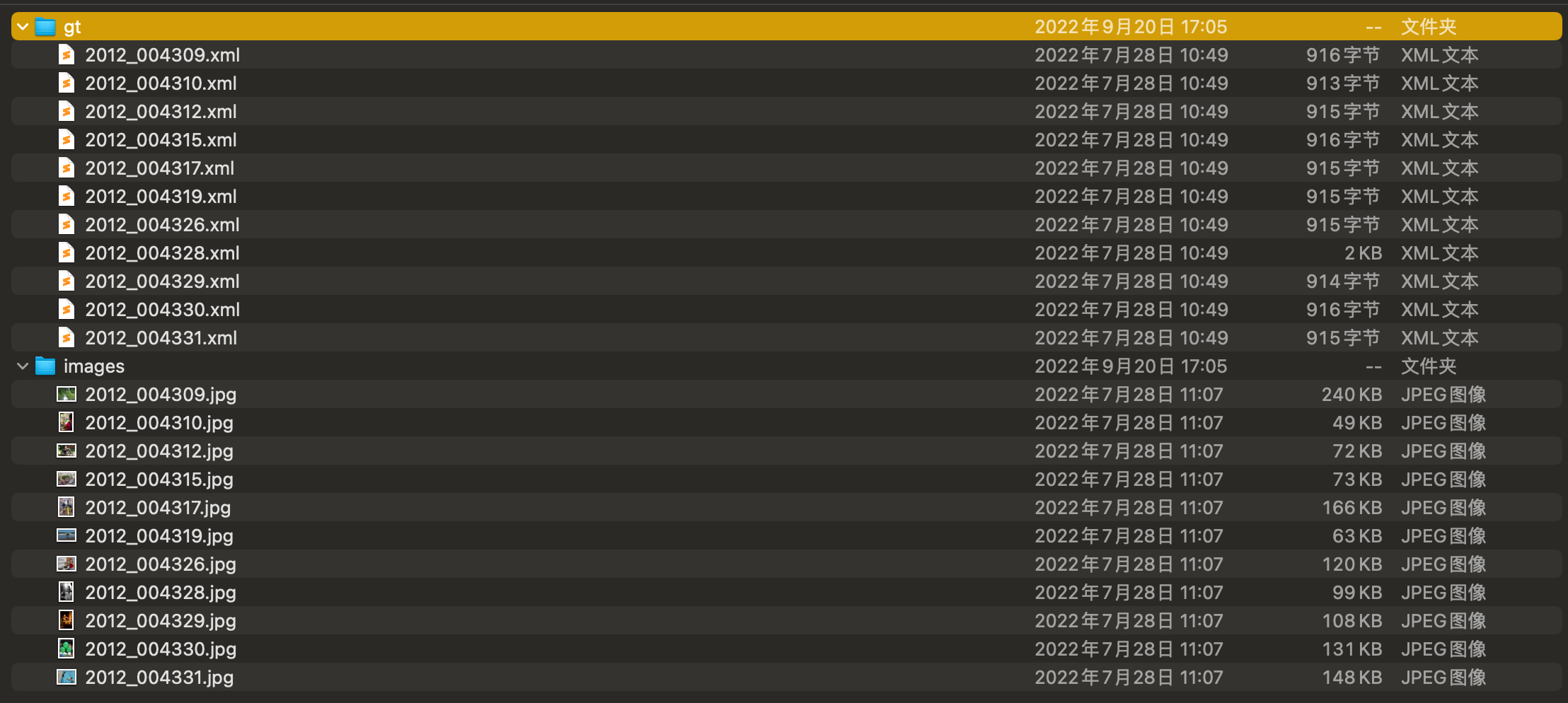
資料集包含兩個資料夾,包括gt和images。gt是xml檔案儲存的目錄,images是圖片儲存的目錄。而且xml檔案和images同名,只是字尾不一樣。
import os
import json
from xml.etree import ElementTree as ET
from collections import defaultdict
class VocToCoco:
def __init__(self, voc_gt_dir: str, output_coco_path: str) -> None:
self.voc_gt_dir = voc_gt_dir
self.output_coco_path = output_coco_path
self.categories_count = 1
self.images = []
self.categories = {}
self.annotations = []
self.data = defaultdict(list)
# 圖片處理
def images_handle(self, root: ET.Element, img_id: int) -> None:
filename = root.find('filename').text.strip()
width = int(root.find('size').find('width').text)
height = int(root.find('size').find('height').text)
self.images.append({
'id': int(img_id),
'file_name': filename,
'height': height,
'width': width,
})
# 標籤轉換
def categories_handle(self, category: str) -> None:
if category not in self.categories:
self.categories[category] = {'id': len(self.categories) + 1, 'name': category}
# 標註轉換
def annotations_handle(self, bbox: ET.Element, img_id: int, category: str) -> None:
x1 = int(bbox.find('xmin').text)
y1 = int(bbox.find('ymin').text)
x2 = int(bbox.find('xmax').text)
y2 = int(bbox.find('ymax').text)
self.annotations.append({
'id': self.categories_count,
'image_id': int(img_id),
'category_id': self.categories[category].get('id'),
'bbox': [x1, y1, x2 - x1, y2 - y1],
'iscrowd': 0
})
self.categories_count += 1
def parse_voc_annotation(self) -> None:
for img_id, filename in enumerate(os.listdir(self.voc_gt_dir), 1):
xml_file = os.path.join(self.voc_gt_dir, filename)
tree = ET.parse(xml_file)
root = tree.getroot()
self.images_handle(root, img_id)
for obj in root.iter('object'):
category = obj.find('name').text
self.categories_handle(category)
bbox = obj.find('bndbox')
self.annotations_handle(bbox, img_id, category)
self.data['images'] = self.images
self.data['categories'] = list(self.categories.values())
self.data['annotations'] = self.annotations
with open(self.output_coco_path, 'w') as f:
json.dump(self.data, f)
if __name__ == "__main__":
# Example usage
voc_gt_dir = 'person_驗證集_voc/gt'
img_dir = 'person_驗證集_voc/images'
output_coco_path = 'person_驗證集_voc/annocation_coco.json'
voc2coco = VocToCoco(voc_gt_dir, output_coco_path)
voc2coco.parse_voc_annotation()
指令碼的主要邏輯:
- 遍歷所有voc資料集
- 獲取所有標籤資訊,去重儲存在self.categories
- 獲取所有圖片後設資料,儲存在self.images
- 獲取所有標註資訊,儲存在self.annotations
- 將以上三個容器儲存到字典中,並將字典儲存為一個json檔案